Ceph 管理员手册
Ceph 是一个高可靠性、可扩展的分布式存储服务,能够存储 PB 级别的海量数据,并对外提供文件系统、对象存储、块存储接口,其架构见官方文档。
TensorStack AI 平台支持使用 Ceph 作为集群存储服务,并提供 PVC、S3 等方式使用。下图展示了 K8s 集群与 Ceph 集群如何协同工作:
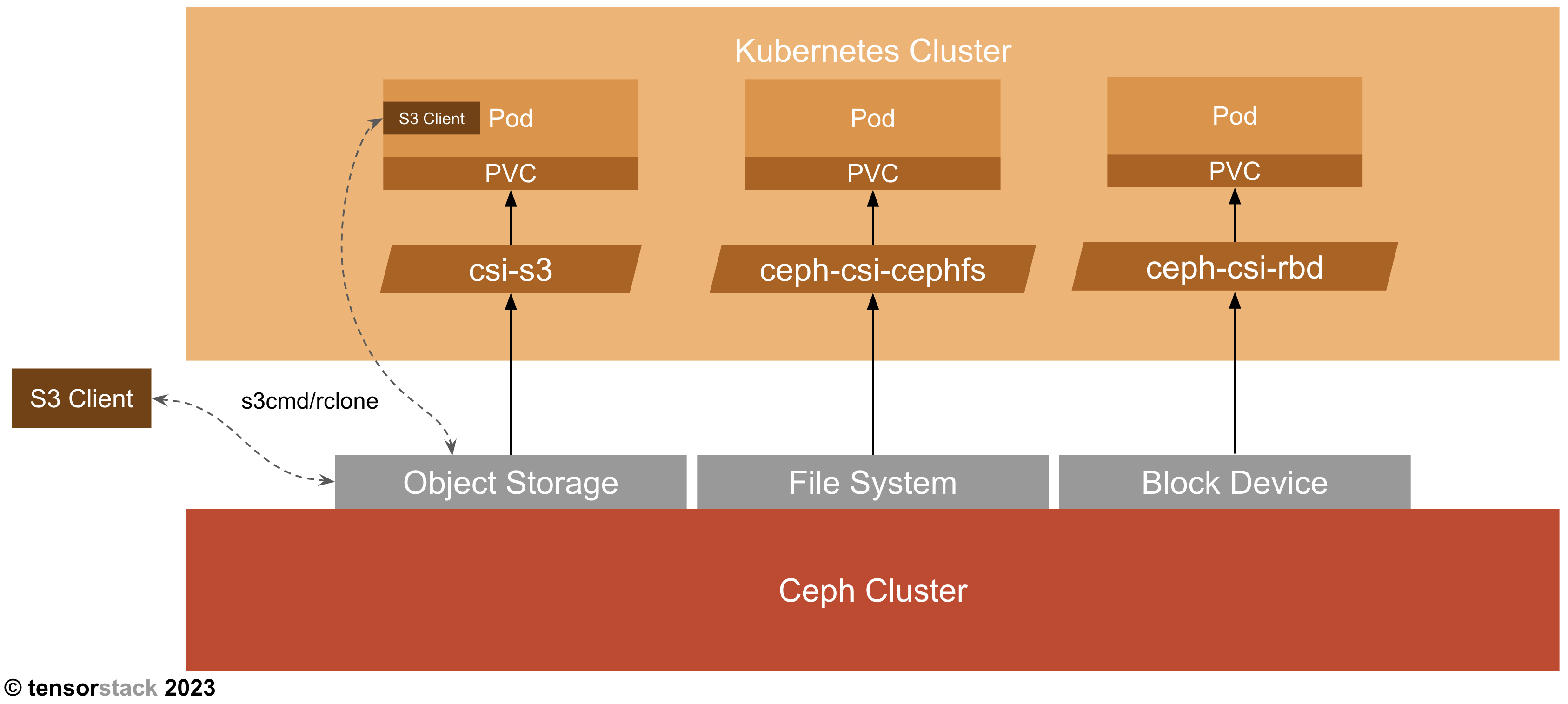
本手册在 Ceph 官方文档的基础上提供更加具有针对性的指导,方便管理员对 TensorStack AI 平台中部署的 Ceph 存储集群进行日常管理、故障排查等工作。
基本概念
Ceph 架构
Ceph 架构如下图所示:
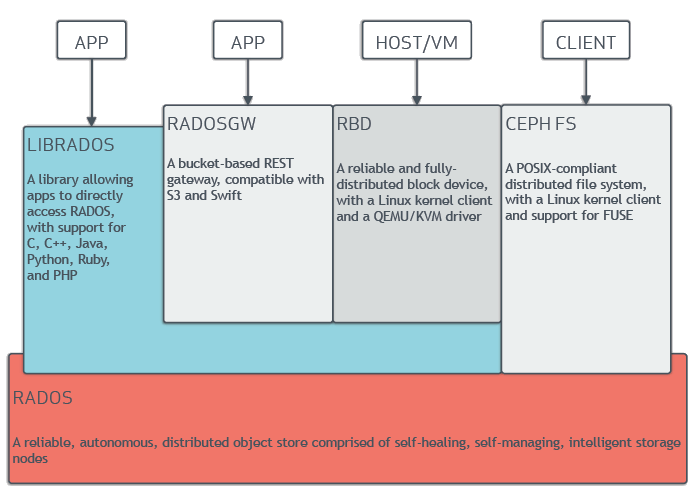
在底层 RADOS (Reliable, Autonomic Distributed Object Store) 存储服务的支撑下,Ceph 对外提供三种接口:
- CephFS (Ceph File System): 文件系统接口,兼容 POSIX。
- RGW (Rados Gateway): 对象存储接口,兼容 S3。
- RBD (Raw Block Device): 块存储接口,提供虚拟块设备。
Ceph 组件
Ceph 主要有以下组件:
- MON (Monitor): 保存 Ceph 存储集群的完整信息(称之为 cluster map),一般每个集群 3~7 个。
- MGR (Manager): 提供监控、编排、插件等功能,一般每个集群 2 个。
- OSD (Object Storage Device): 用于保存数据,一般每个集群 10~1000 个。
- 每个 OSD 对应一个 HDD/SSD 存储设备。
- 客户端直接向 OSD 发起 IO 请求。
- OSD 之间互相合作,共同完成数据的可靠存储。
- MDS (Metadata Server): 用于在 CephFS 中存储所有文件的元数据,一般每个 CephFS 2 个。
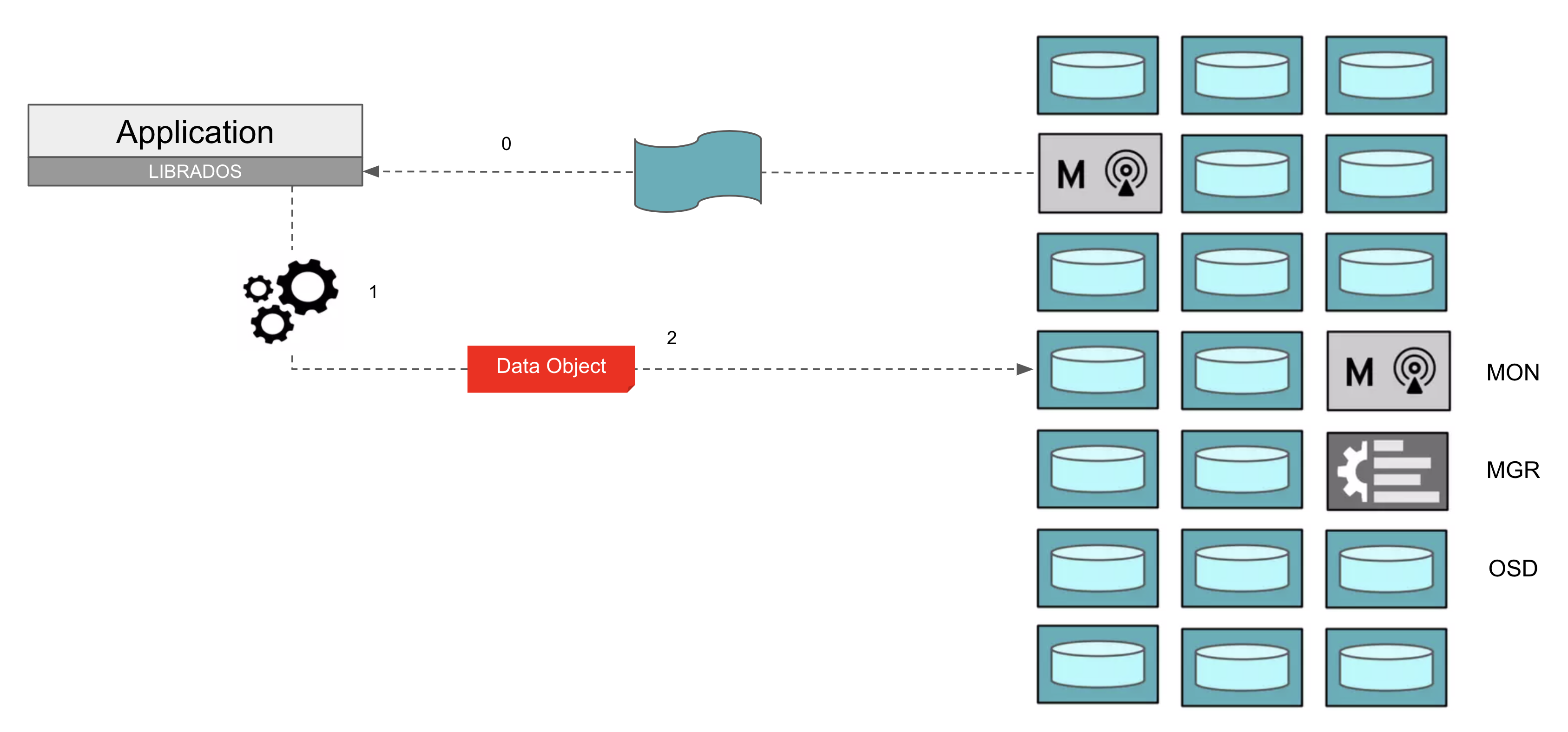
客户端与 Ceph 通信的步骤如上图所示:
- 客户端从 MON 获取 cluster map,包括 OSD 数量、地址等信息。
- 客户端根据 cluster map 计算一个 object 应当存储在哪个 OSD。
- 客户端向相应的 OSD 发起请求,写入 object。
- 当集群发生变动时(例如存储设备损坏、节点增加),客户端从 MON 获取更新的 cluster map,重新计算 object 的存储位置,并与相应的 OSD 通信。
- 当客户端通过 CephFS 接口访问 Ceph 时,文件元数据相关的操作(例如打开文件、创建文件夹)与 MDS 通信,文件数据相关的操作(例如写入文件、读取文件)与相应的 OSD 通信。
RADOS 原理
RADOS 存储数据以 object 为单位,每个 RADOS object 由 ID、二进制数据、元数据组成:

其中:
- ID 是每个 RADOS object 的全局唯一标识
- 二进制数据是 RADOS object 的主体,大小约数十 MB
- 元数据是一些键值对,数量可以有数万个,每个键值对的大小约数十 KB
下图展示了一个文件存入 RADOS 的具体原理:
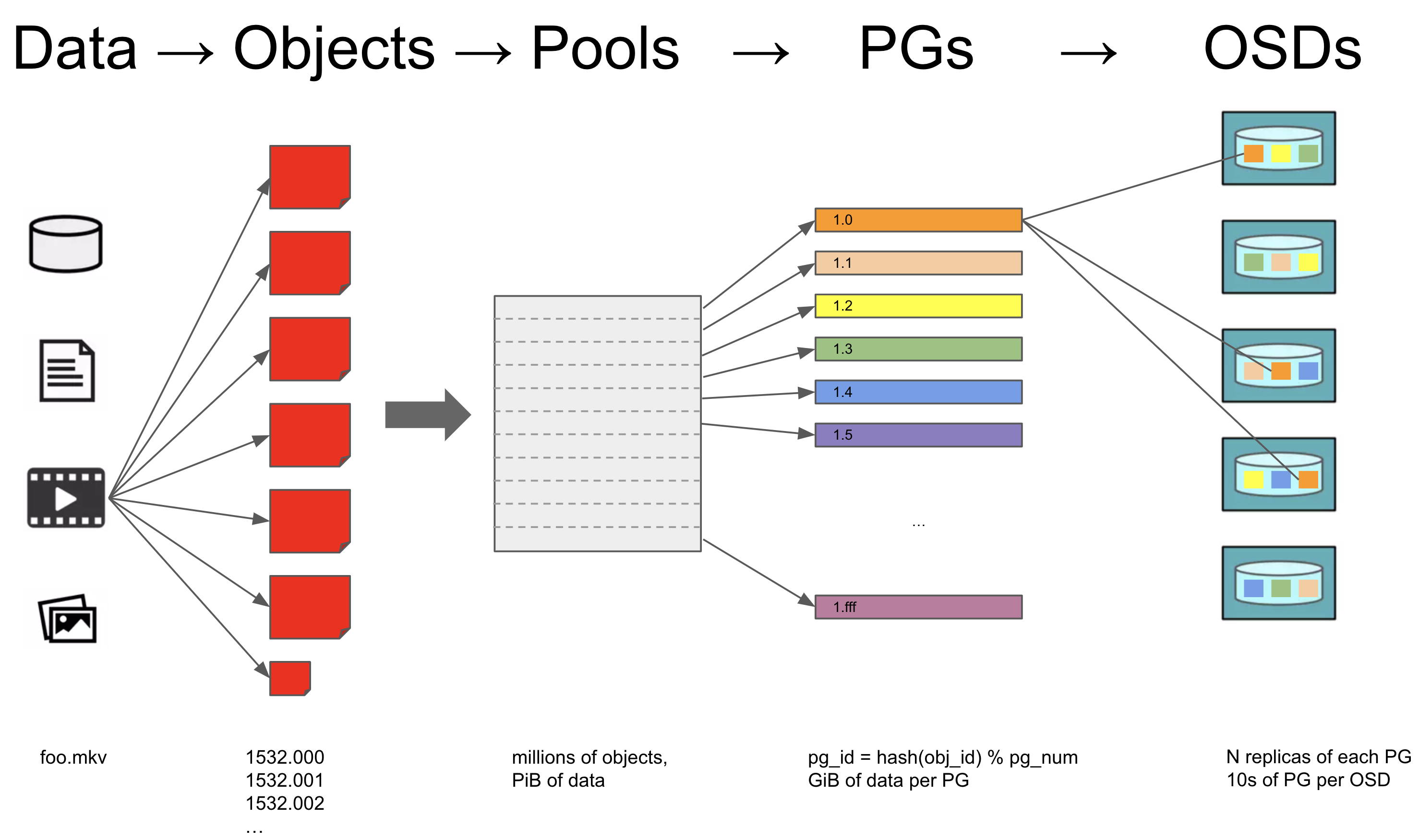
当一个文件需要存入 RADOS 时,
- 文件被分为很多个 RADOS object
- RADOS object 被存入相应的 Pool
- CephFS 分为 medata pool 和 data pool
- RGW 分为 user pool、bucket pool、data pool 等
- 一个 Pool 由很多个 PG (Placement Group) 组成
- 每个 PG 默认会有 3 份拷贝,存储在不同的 OSD 中,确保少量 OSD 的损坏不会影响数据的完整性
根据数据可靠性要求的不同,我们可以:
- 配置 PG 的拷贝存储在不同的 OSD 中、不同的节点中、或者不同的机架中。
- 配置 PG 拷贝多份,或者配置 PG 以 Erasure Code 的形式存储。
集群安装
安装 Ceph
Ceph 集群的安装从 bootstrap 一个节点开始,然后逐步加入其它节点、添加存储设备。
首先,确保节点上装有 Docker,如果没有,请按照 Docker 官方文档安装 Docker。
然后,在第一个节点上安装 Ceph:
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
chmod +x cephadm
sudo ./cephadm add-repo --release quincy
sudo ./cephadm install
sudo cephadm bootstrap --mon-ip <ip-address-of-first-node>
sudo cephadm add-repo --release quincy
sudo cephadm install ceph-common
参考文档:
添加节点
假设新加入的节点的 IP 为 10.1.2.3,名称为 host1。
首先,将 Ceph 集群的 SSH 公钥添加到新节点的信任列表中。
如果有新节点的 root 密码,在任意管理节点上运行:
sudo ssh-copy-id -f -i /etc/ceph/ceph.pub root@10.1.2.3
如果有新节点的某个具有 sudo 权限的用户密码,假设其用户名为 superuser。
在任意管理节点上运行:
sudo scp /etc/ceph/ceph.pub superuser@10.1.2.3:~/ceph.pub
在新节点上运行:
sudo su
cat ~/ceph.pub >> /root/.ssh/authorized_keys
然后,确保新节点上安装了 Docker:
sudo docker version
如果没有,请按照 Docker 官方文档安装 Docker。
最后,在管理节点上运行以下命令添加新节点到 Ceph 集群:
sudo ceph orch host add host1 10.1.2.3
sudo ceph orch host add host1 10.1.2.3 --labels _admin
并在新节点中安装 Ceph 命令行:
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
chmod +x cephadm
sudo ./cephadm add-repo --release quincy --repo-url https://mirrors.aliyun.com/ceph # speed up using aliyun mirror
sudo apt update
sudo ./cephadm install ceph-common ceph
参考文档:
添加存储设备
用于 Ceph 存储的存储设备需要满足下列要求:
- 没有分区
- 没有 LVM 状态
- 没有被挂载
- 没有文件系统
- 大于 5GB
如果存储设备曾被用于其他 Ceph 集群,可通过以下命令清除设备状态:
sudo ceph orch device zap <hostname> <devicepath>
例如:
sudo ceph orch device zap host1 /dev/sdb
如果存储设备曾被用作其他用途,可通过以下命令删除设备中的分区:
# 删除分区
sudo fdisk /dev/sdX
# 清除残余的分区表信息
sudo sgdisk --zap-all /dev/sdX
如果设备中仍然有残留的 LVM 状态,可尝试:
- 重启节点
- 利用 LVM 相关命令清除
在任意管理节点上运行以下命令,即可自动化地发现所有节点上可用的存储设备,并为其创建 OSD Daemon、添加到 Ceph 集群中:
sudo ceph orch apply osd --all-available-devices
或者,停止自动发现:
sudo ceph orch apply osd --all-available-devices --unmanaged=true
然后手动为某个存储设备创建 OSD:
sudo ceph orch daemon add osd <hostname>:<device-path>
例如:
sudo ceph orch daemon add osd host1:/dev/sdb
参考文档:
mpath 设备
如果存储设备不是常见的 hdd、ssd 硬盘,而是 mpath 设备,您需要手动创建 osd。
假设 mpath 设备位于 /dev/mapper/mpatha。首先,创建 lvm 相关的 pv、vg、lv 等:
sudo pvcreate --metadatasize 250k -y -ff /dev/mapper/mpatha
sudo vgcreate vgmpatha /dev/mapper/mpatha
sudo lvcreate -n lv0 -l 100%FREE vgmpatha
然后,使用 ceph 命令行工具准备 lv:
sudo ceph-volume lvm prepare --data /dev/vgmpatha/lv0
最后,激活 osd:
sudo ceph-volume lvm activate --all
激活时可能需要指定具体的 osd:
sudo ceph-volume lvm activate <osd-id> <osd-fsid>
例如:
sudo ceph-volume lvm activate 3 249e9103-5fec-4acc-b545-82c644f8756f
其中,<osd-id> 和 <osd-fsid> 在使用 ceph 命令行工具准备 lv 步骤的输出中可以找到,也可以通过以下命令查看:
sudo ceph-volume lvm list
通过以下命令可以查看 lvm 相关的 pv、vg、lv:
sudo pvs
sudo pvdisplay
sudo vgs
sudo vgdisplay
sudo lvs
sudo lvdisplay
当 mpath 设备所在的节点重启时,lv 可能变为 unavailable 状态,导致 osd 异常,需要通过以下命令重新激活 lv:
sudo lvchange -ay /dev/vgmpatha/lv0
参考文档:
配置 dashboard
Ceph 提供可视化 dashboard 来管理集群。
启用 dashboard:
sudo ceph mgr module enable dashboard
设置 http 访问:
sudo ceph config set mgr mgr/dashboard/ssl false
重启 dashboard:
sudo ceph mgr module disable dashboard
sudo ceph mgr module enable dashboard
设置 dashboard 密码:
sudo ceph dashboard ac-user-set-password admin -i <file-containing-password>
参考查看 daemon 状态,找到 mgr daemon 所在的节点,dashboard 的地址即为 http://<mgr-host-ip>:8080。
为了配置 grafana 使用 http,通过 SSH 登录 grafana 所在的节点,修改 grafana 的配置文件,将 https 改为 http,然后重启 grafana 容器:
sudo vim /var/lib/ceph/<cluster-id>/grafana.<hostname>/etc/grafana/grafana.ini
docker ps | grep grafana
docker restart <grafana-container>
配置 grafana、alertmanager、prometheus 等监控组件,以便在 dashboard 中查看可视化统计图表:
sudo ceph dashboard set-grafana-frontend-api-url http://<host-ip>:3000
sudo ceph dashboard set-grafana-api-ssl-verify False
sudo ceph dashboard set-grafana-api-url http://<host-ip>:3000
sudo ceph dashboard set-alertmanager-api-host http://<host-ip>:9093
sudo ceph dashboard set-alertmanager-api-ssl-verify false
sudo ceph dashboard set-prometheus-api-host http://<host-ip>:9095
sudo ceph dashboard set-prometheus-api-ssl-verify false
参考文档:
配置 crushmap
Ceph 的默认存储策略是在不同的节点之间将数据复制 3 份,以提供高可用性。如果我们只有少于 3 个节点,根据这个博客,需要配置 Ceph 在 OSD 之间复制数据。
查看当前的 crushmap:
sudo ceph osd crush rule dump
导出当前的 crushmap:
sudo ceph osd getcrushmap -o comp_crush_map.cm
将导出的 curshmap 解析为人类可读的文件:
crushtool -d comp_crush_map.cm -o crush_map.cm
编辑 crushmap,将其中的 host 改为 osd:
vim crush_map.cm
例如,寻找 crushmap 中的下列内容:
# rules
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
将其修改为:
# rules
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type osd
step emit
}
编译新的 crushmap:
crushtool -c crush_map.cm -o new_crush_map.cm
应用新的 curshmap:
sudo ceph osd setcrushmap -i new_crush_map.cm
参考文档:
配置时钟同步
我们推荐使用 chrony 来同步所有节点的时钟,推荐采用一个主节点向外部时钟服务器同步时钟、其他节点向该主节点同步时钟的方案。
通过以下命令安装 chrony:
sudo apt update
sudo apt install chrony
chrony 配置文件位于 /etc/chrony/chrony.conf
主节点配置如下:
# Welcome to the chrony configuration file. See chrony.conf(5) for more
# information about usuable directives.
# This will use (up to):
# - 4 sources from ntp.ubuntu.com which some are ipv6 enabled
# - 2 sources from 2.ubuntu.pool.ntp.org which is ipv6 enabled as well
# - 1 source from [01].ubuntu.pool.ntp.org each (ipv4 only atm)
# This means by default, up to 6 dual-stack and up to 2 additional IPv4-only
# sources will be used.
# At the same time it retains some protection against one of the entries being
# down (compare to just using one of the lines). See (LP: #1754358) for the
# discussion.
#
# About using servers from the NTP Pool Project in general see (LP: #104525).
# Approved by Ubuntu Technical Board on 2011-02-08.
# See http://www.pool.ntp.org/join.html for more information.
pool ntp.ubuntu.com iburst maxsources 4
pool 0.ubuntu.pool.ntp.org iburst maxsources 1
pool 1.ubuntu.pool.ntp.org iburst maxsources 1
pool 2.ubuntu.pool.ntp.org iburst maxsources 2
allow 100.64.4.0/8
# This directive specify the location of the file containing ID/key pairs for
# NTP authentication.
keyfile /etc/chrony/chrony.keys
# This directive specify the file into which chronyd will store the rate
# information.
driftfile /var/lib/chrony/chrony.drift
# Uncomment the following line to turn logging on.
#log tracking measurements statistics
# Log files location.
logdir /var/log/chrony
# Stop bad estimates upsetting machine clock.
maxupdateskew 100.0
# This directive enables kernel synchronisation (every 11 minutes) of the
# real-time clock. Note that it can't be used along with the 'rtcfile' directive.
rtcsync
# Step the system clock instead of slewing it if the adjustment is larger than
# one second, but only in the first three clock updates.
makestep 1 3
注意,其中 allow 100.64.4.0/8 需填写其他节点的 ip 网段。
其他节点配置如下:
# Welcome to the chrony configuration file. See chrony.conf(5) for more
# information about usuable directives.
# This will use (up to):
# - 4 sources from ntp.ubuntu.com which some are ipv6 enabled
# - 2 sources from 2.ubuntu.pool.ntp.org which is ipv6 enabled as well
# - 1 source from [01].ubuntu.pool.ntp.org each (ipv4 only atm)
# This means by default, up to 6 dual-stack and up to 2 additional IPv4-only
# sources will be used.
# At the same time it retains some protection against one of the entries being
# down (compare to just using one of the lines). See (LP: #1754358) for the
# discussion.
#
# About using servers from the NTP Pool Project in general see (LP: #104525).
# Approved by Ubuntu Technical Board on 2011-02-08.
# See http://www.pool.ntp.org/join.html for more information.
server 100.64.4.104
# This directive specify the location of the file containing ID/key pairs for
# NTP authentication.
keyfile /etc/chrony/chrony.keys
# This directive specify the file into which chronyd will store the rate
# information.
driftfile /var/lib/chrony/chrony.drift
# Uncomment the following line to turn logging on.
#log tracking measurements statistics
# Log files location.
logdir /var/log/chrony
# Stop bad estimates upsetting machine clock.
maxupdateskew 100.0
# This directive enables kernel synchronisation (every 11 minutes) of the
# real-time clock. Note that it can't be used along with the 'rtcfile' directive.
rtcsync
# Step the system clock instead of slewing it if the adjustment is larger than
# one second, but only in the first three clock updates.
makestep 1 3
注意,其中 server 100.64.4.104 需填写主节点的 ip。
修改配置文件后,通过以下命令重启 chrony 使配置生效:
sudo systemctl restart chronyd
在主节点上查看 chrony 运行状态:
sudo chronyc activity
sudo chronyc tracking
sudo chronyc sources -v
sudo chronyc clients
查看 Ceph 时钟同步状态:
sudo ceph time-sync-status
参考文档:
配置警告通知
Ceph 自带一整套监控系统,包括 prometheus/grafana/alert mamanger。为了能够及时收到 alert manager 发出的警告,您可以配置 alert manager 通过邮箱和企业微信来发送警告信息。
通过 SSH 登录 alert manager 所在的节点,将位于 /var/lib/ceph/<cluster-id>/alertmanager.<hostname>/etc/alertmanager 的配置文件 alertmanager.yml 修改为如下内容(注意替换其中邮箱和企业微信相关的具体配置):
# This file is generated by cephadm.
# See https://prometheus.io/docs/alerting/configuration/ for documentation.
global:
resolve_timeout: 5m
http_config:
tls_config:
insecure_skip_verify: true
route:
receiver: 'ceph-dashboard'
routes:
- group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'ceph-dashboard'
continue: true
- group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 6h
receiver: 't9k-monitoring/email/t9k-sre'
continue: true
- group_by: ['alertname']
group_wait: 10s
group_interval: 5m
repeat_interval: 12h
receiver: 't9k-monitoring/wechat/alerts'
continue: true
receivers:
- name: 'ceph-dashboard'
webhook_configs:
- url: 'http://<hostname>:8080/api/prometheus_receiver'
- name: t9k-monitoring/email/t9k-sre
email_configs:
- to: <to>
from: <from>
smarthost: <smarthost>
auth_username: <auth_username>
auth_password: <auth_password>
headers:
Subject: '{{ template "email.subject" . }}'
- name: t9k-monitoring/wechat/alerts
wechat_configs:
- api_secret: <api_secret>
corp_id: <corp_id>
agent_id: <agent_id>
to_user: '@all'
message: '{{ template "wechat.message" . }}'
templates:
- /etc/alertmanager/custom.tmpl
在同一文件夹下创建 custom.tmpl,内容如下:
{{ define "email.subject" }}[ceph]{{ template "__subject" . }}{{ end }}
{{ define "__custom_text_alert_list" }}{{ range . }}
--
{{with .Annotations.description}}Description: {{.}} {{else -}} {{end}}
Labels:
{{- range .Labels.SortedPairs }}
- {{ .Name }}:
{{ .Value }}
{{- end }}
{{- end }}{{- end -}}
{{ define "wechat.message" }}[ceph]{{ template "__subject" . }}
Summary: {{ .CommonAnnotations.summary }}
{{ if gt (len .Alerts.Firing) 0 }}
Firing Alerts:
{{ template "__custom_text_alert_list" .Alerts.Firing }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0}}
Resolved Alerts:
{{ template "__custom_text_alert_list" .Alerts.Resolved }}
{{- end }}{{- end -}}
然后重启 alert manager 容器:
docker ps | grep alertmanager
docker restart <alert-manager-container>
创建 cephfs
运行以下命令创建 cephfs:
sudo ceph fs volume create <fs_name> --placement=<placement>
其中 <placement> 是指 cephfs 的 mds daemon 部署在哪些节点上。为了高可用,一个 cephfs 一般有两个 mds daemon:一个正常运行,一个随时准备接替。
例如:
sudo ceph fs volume create k8s --placement="host1 host2"
参考文档:
配置 erasure code
erasure code 是一种纠错码,在原始数据的基础上冗余存储一些经过编码的数据块,以便在一些数据块损坏时仍然能够计算出原始数据。
erasure code 最重要的参数是 k 和 m,其中
- k 表示原始数据将被分为 k 个数据块(data chunks)
- m 表示在原始数据的基础上计算出 m 个编码块(encoding chunks)
上述 k + m 个块将会被分别存储在不同的地方,根据配置的不同,可以是不同的 host、不同的 osd 等。
erasure code 的优势在于
- 最多能承受 k + m 个块中任意 m 个块的损坏
- 存储 1 个单位的原始数据,需要 (k + m) / k 个单位的空间
作为参考,Red Hat 支持以下 k/m 值:
- k=8 m=3
- k=8 m=4
- k=4 m=2
首先创建一个 erasure code profile(以 k=4 m=2 为例):
sudo ceph osd erasure-code-profile set ecprofile-k4-m2 k=4 m=2 crush-failure-domain=osd
sudo ceph osd erasure-code-profile ls
sudo ceph osd erasure-code-profile get ecprofile-k4-m2
然后创建一个 erasure coded pool:
sudo ceph osd pool create ecpool-k4-m2 erasure ecprofile-k4-m2
sudo ceph osd pool set ecpool-k4-m2 allow_ec_overwrites true
sudo ceph osd pool application enable ecpool-k4-m2 cephfs
最后将 erasure coded pool 作为第二个 data pool 加入到 CephFS 中:
sudo ceph fs add_data_pool <fs-name> ecpool-k4-m2
sudo ceph fs ls
参考文档:
- Ceph - Erasure code
- Ceph - Using erasure coded pools with CephFS
- Ceph - Adding a data pool to the file system
集群运维
查看集群状态
Ceph 提供了完善的 Web UI 来查看和操作集群中的各项服务。首先,使用管理员的用户名和密码登录 Ceph Web UI。

点击左侧导航栏的 Dashboard,查看集群状态总览。
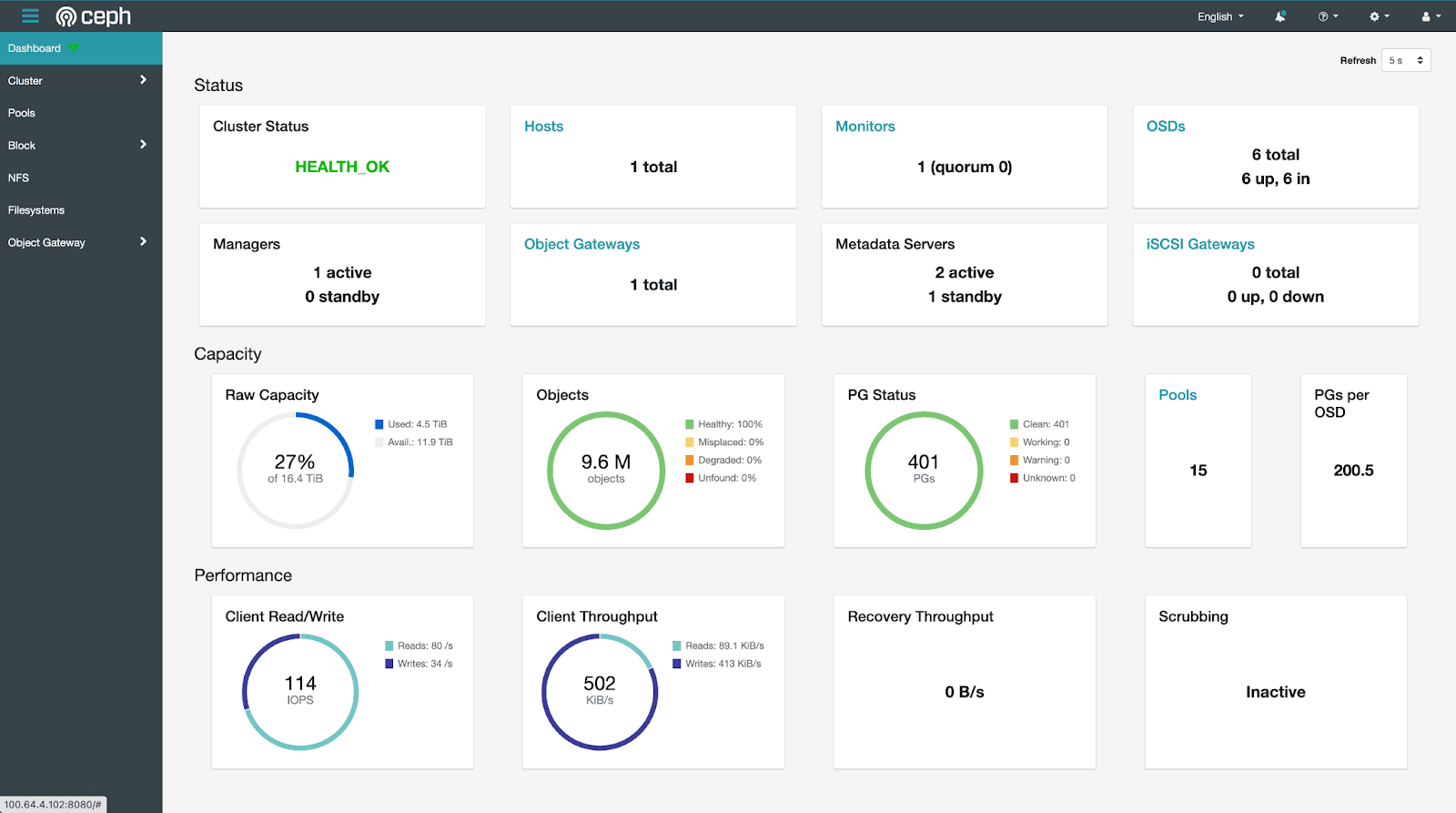
点击左侧导航栏的 Cluster > OSDs,查看各个磁盘的使用情况。
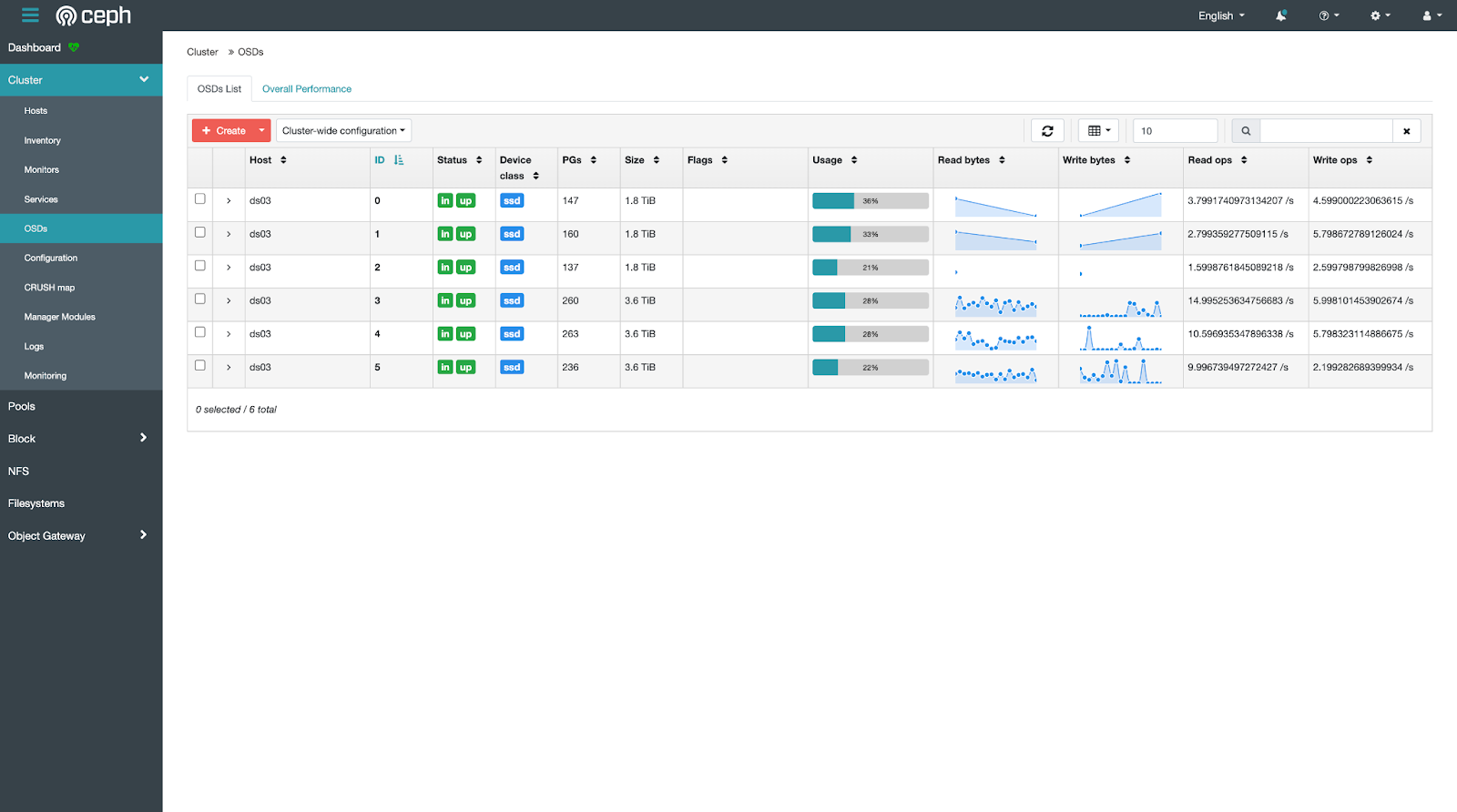
点击左侧导航栏的 Cluster > OSDs,然后点击上侧的 Overall Performance,查看磁盘使用情况的可视化统计数据。
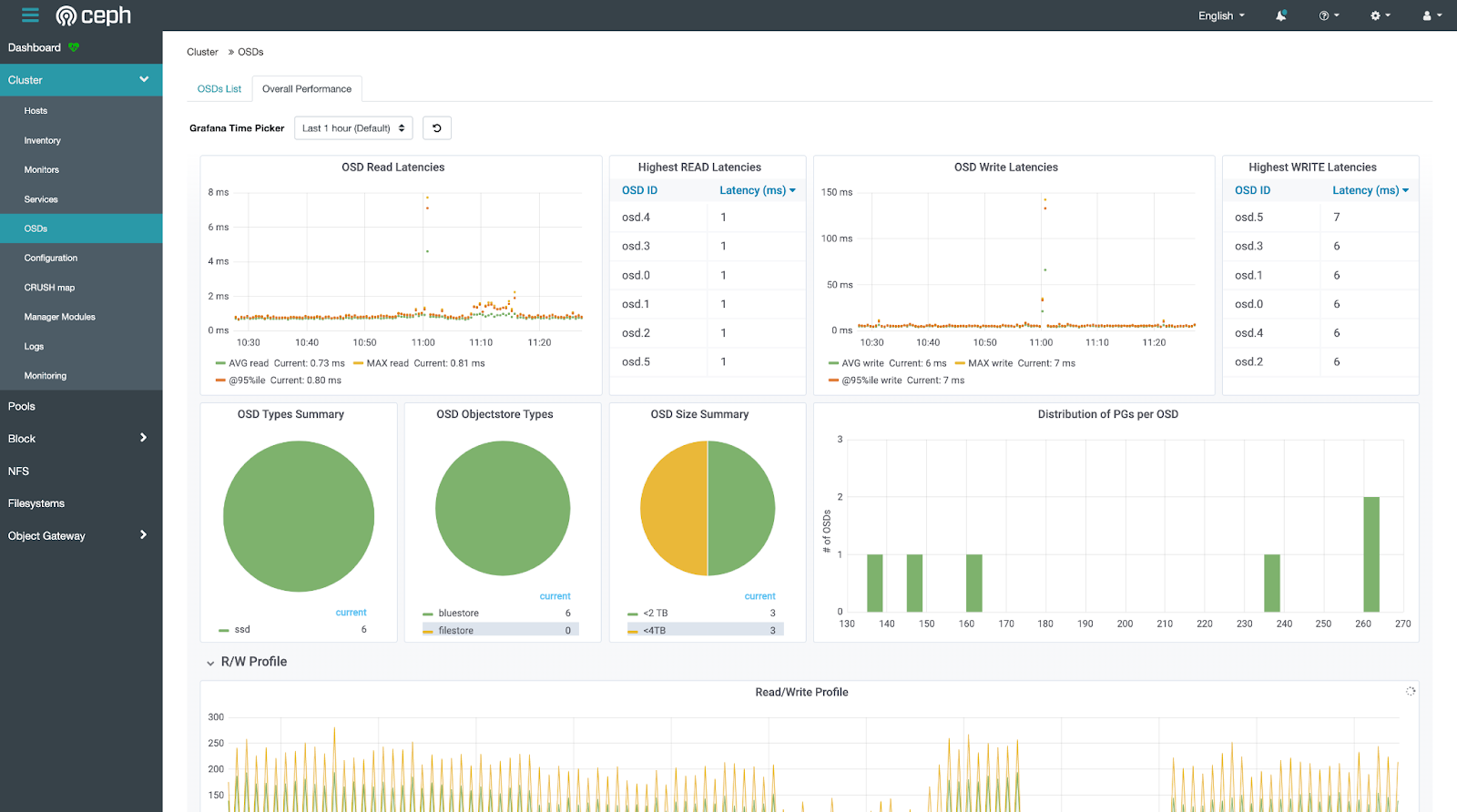
点击左侧导航栏的 Cluster > Logs,查看集群日志。
另外,您也可以通过 SSH 登录 Ceph 集群的管理节点,使用命令行来查看。
查看集群状态总览:
sudo ceph status
sudo ceph -s
sudo ceph health detail
查看本节点上运行的各项服务状态:
sudo systemctl status ceph\*.service ceph\*.target
查看本节点上运行的某项服务的详细日志:
sudo journalctl -u <service-name>
例如:
sudo journalctl -u ceph-osd@0.service
参考文档:
管理 alert
在 Ceph Dashboard 中,点击左侧导航栏的 Cluster > Monitoring,可以查看当前集群中的警告信息。
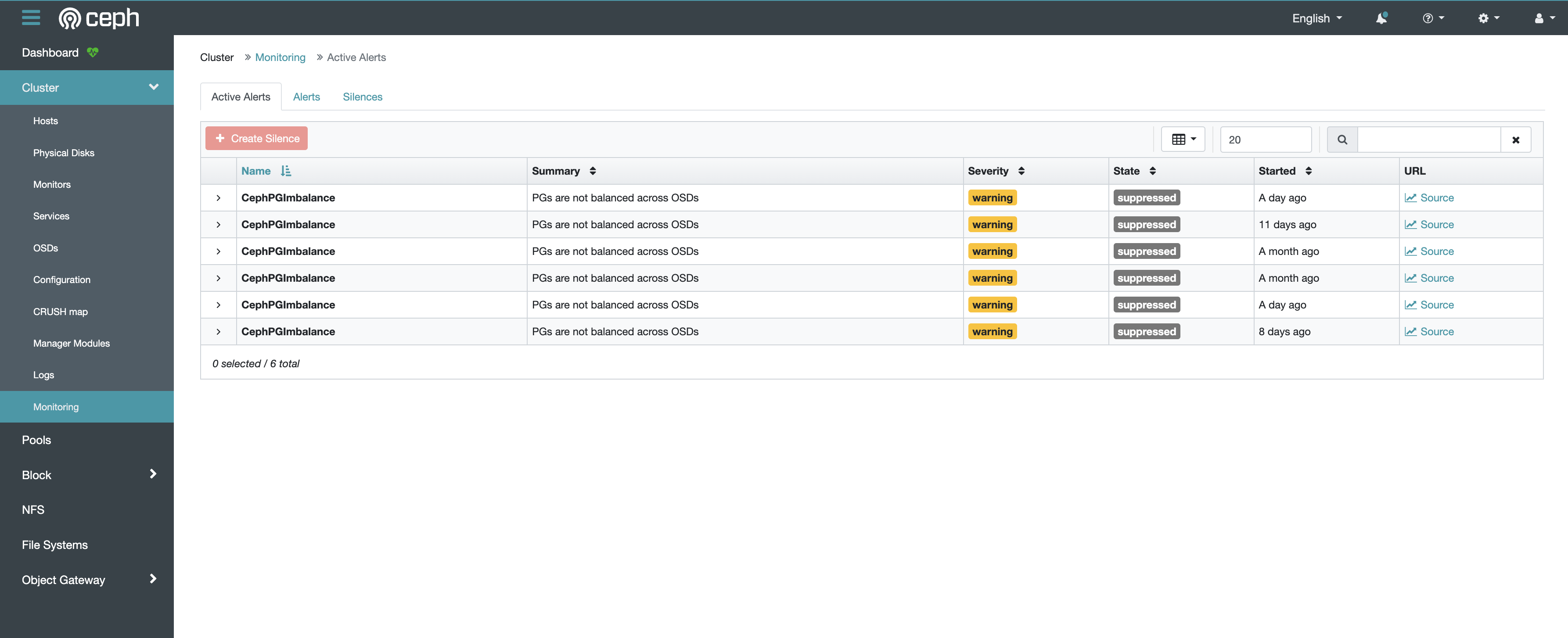
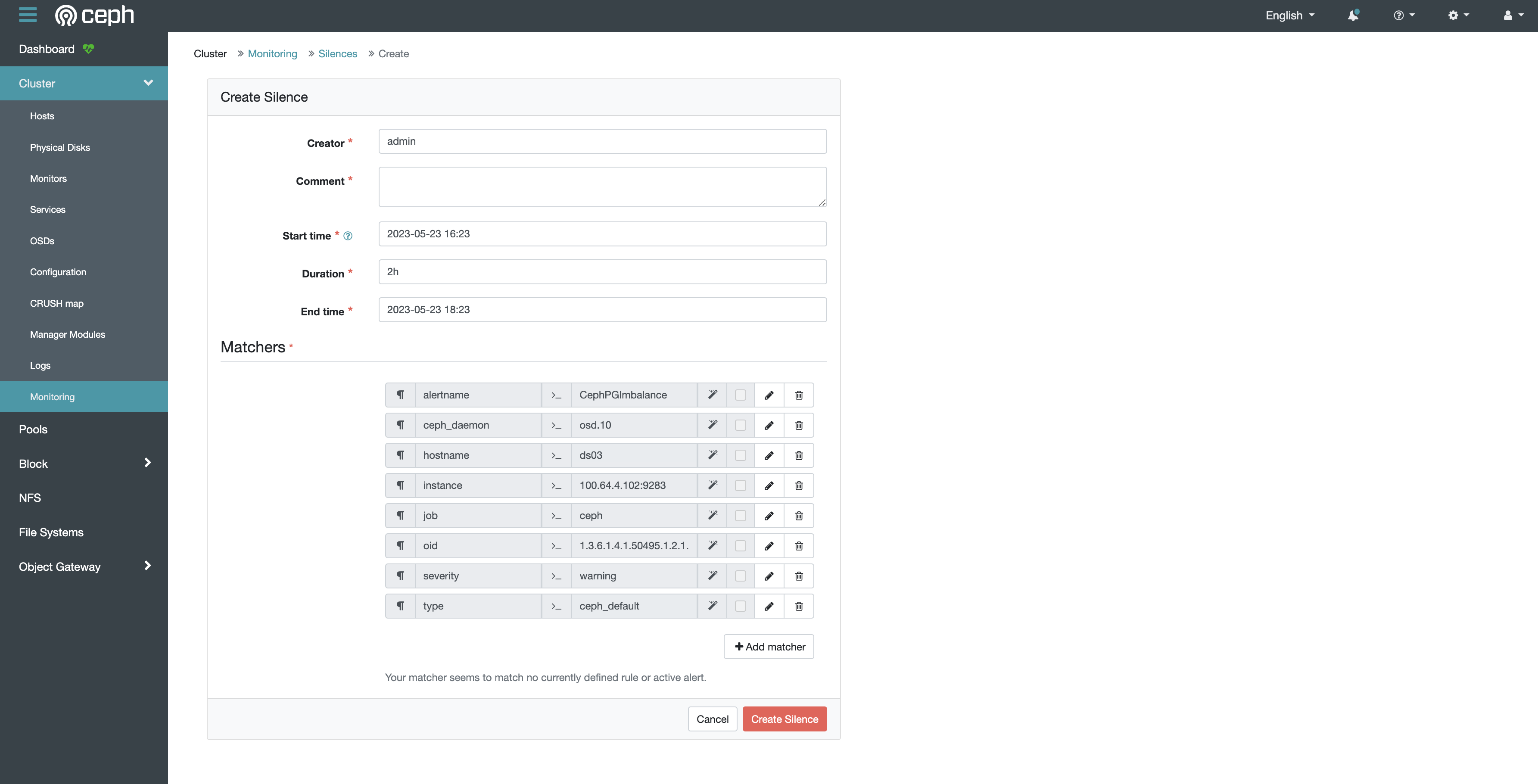
如果确认警告信息无关紧要,您可以静默警告信息。首先在表格中点击所要静默的行,然后点击左上角的 Create Silence 按钮,填写静默时长和筛选条件等配置即可。
另外,您也可以通过命令行来静默警告信息。例如,如果通过命令行查看集群状态发现有如下警告:
$ ceph health detail
[WRN] MDS_SLOW_METADATA_IO: 1 MDSs report slow metadata IOs
您可以通过以下命令静默该警告:
ceph health mute MDS_SLOW_METADATA_IO
或在一定时间内静默警告:
ceph health mute MDS_SLOW_METADATA_IO 1h
通过以下命令取消静默:
ceph health unmute MDS_SLOW_METADATA_IO
参考文档:
查看 daemon 状态
通过以下命令查看集群中运行的所有 daemon:
sudo ceph orch ls
sudo ceph orch ps
sudo ceph orch ls --export > cluster.yaml
参考文档:
获取 daemon 地址
为了获取某个 daemon 的地址,例如 prometheus、grafana、alert manager 等,首先通过以下命令查看 daemon 所在的节点与端口:
$ sudo ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.host1 host1 *:9093,9094 running (5w) 4m ago 8w 54.3M - ba2b418f427c 10679fbf3b3d
grafana.host1 host1 *:3000 running (5w) 4m ago 8w 149M - 8.3.5 dad864ee21e9 526bb2c28317
prometheus.host1 host1 *:9095 running (5w) 4m ago 8w 213M - 514e6a882f6e 8579c7c74cc5
可以看到,prometheus、grafana、alert manager 均运行在 host1 节点上,并分别使用 9095、3000、9093 端口。
通过以下命令查看 host1 节点的 ip:
$ sudo ceph orch host ls
HOST ADDR LABELS STATUS
host1 10.1.2.3 _admin
因此:
- prometheus 的地址为
http://10.1.2.3:9095 - grafana 的地址为
http://10.1.2.3:3000 - alert manager 的地址为
http://10.1.2.3:9093
调整 daemon 配置
Ceph 支持以 yaml 配置文件的形式指定 daemon 的详细 spec。
以 rgw daemon 为例,导出配置文件:
sudo ceph orch ls --service_type rgw --export > rgw.yaml
rgw.yaml 示例如下:
service_type: rgw
service_id: cephs3
service_name: rgw.cephs3
placement:
hosts:
- host1
修改 rgw.yaml 为以下内容:
service_type: rgw
service_id: cephs3
service_name: rgw.cephs3
placement:
count: 2
hosts:
- host1
- host2
networks:
- 172.0.0.0/24
spec:
rgw_frontend_port: 8081
其中:
- 配置 rgw daemon 为 2 个,host1 节点、host2 节点各一个
- 配置 rgw daemon 使用 172.0.0.0/24 网络
- 配置 rgw daemon 使用 8081 端口
应用该配置文件:
sudo ceph orch apply -i ./rgw.yaml
移除 daemon
通过以下命令移除某个 daemon:
sudo ceph orch daemon rm <daemon-name>
例如:
sudo ceph orch daemon rm mgr.ds03.obymbg
移除 service
通过以下命令移除某个 service:
sudo ceph orch rm <service-name>
例如:
sudo ceph orch rm mds.k8s
参考文档:
查看 mon ip
通过以下命令查看 mon ip:
sudo ceph mon dump
创建 mon
默认情况下,Ceph 集群自动管理 mon daemon,一般在 5 个不同的节点上部署 5 个 daemon,占用节点的 3300 和 6789 端口。
如果需要手动管理 mon,首先执行以下命令:
sudo ceph orch apply mon --unmanaged
然后手动创建 mon:
sudo ceph orch daemon add mon --placement="myhost:[v2:1.2.3.4:3300,v1:1.2.3.4:6789]=name"
其中,[v2:1.2.3.4:3300,v1:1.2.3.4:6789] 是 mon 的网络地址,=name 用于指定所创建的 mon 名称。
参考文档:
查看 crash 历史
通过以下命令查看集群中曾经发生过的 crash 事件:
sudo ceph crash ls
查看某个 crash 事件的详细信息:
sudo ceph crash info <crash-id>
将 crash 事件归档,以免出现在 ceph status 的输出中:
sudo ceph crash archive-all
参考文档:
查看节点
通过以下命令查看集群中的所有节点:
sudo ceph orch host ls
添加节点
重启节点
通过 SSH 登录 Ceph 集群的任意一个节点,可执行以下命令重启本节点上的 Ceph 服务:
sudo systemctl stop ceph\*.service ceph\*.target
sudo systemctl start ceph.target
移除节点
假设将被移除的节点名称为 host1,以下命令均需要在 Ceph 集群的其他管理节点上运行。
运行以下命令移除 host1:
sudo ceph orch host ls
sudo ceph orch host drain host1
sudo ceph mon remove host1
观察 OSD 的移除情况,直到其报告 “No OSD remove/replace operations reported”:
sudo ceph orch osd rm status
观察 Daemon 的移除情况(这可能会需要较长的时间),直到其报告 “No daemons reported”:
sudo ceph orch ps host1
所有 Daemon 都被移除后才能通过以下命令删除节点 host1:
sudo ceph orch host rm host1
sudo ceph orch host ls
参考文档:
查看存储设备
查看节点上的所有存储设备:
lsblk
查看集群中 Ceph 能看到的所有存储设备:
sudo ceph orch device ls
查看集群中运行的所有 OSD:
sudo ceph osd status
添加存储设备
检查存储设备
如果某个存储设备出现异常,读写速度较慢,可通过以下命令检查:
hdparm -Tt <device-path>
例如:
hdparm -Tt /dev/sdb
移除存储设备
假设将被移除的磁盘上运行的 OSD 编号为 0(可通过 Web UI 或 sudo ceph osd status 命令获取)。
在磁盘所属节点上运行以下命令移除 OSD,并自动化地将该磁盘中存储的数据移动到其他磁盘中:
sudo ceph orch osd rm 0
通过以下命令查看 OSD 移除进展:
sudo ceph orch osd rm status
参考文档:
存储设备故障恢复
如果某个存储设备发生故障,其中的数据无法读取,该存储设备对应的 OSD Daemon 在一段时间后会自动发现故障并显示在集群状态总览中。此时,管理员应当按照移除存储设备一节中的步骤移除故障设备,并将其从物理机器中拔出。
由于 Ceph 使用了冗余存储机制,一个存储设备的损坏并不会造成数据的丢失,Ceph 将自动恢复损坏的数据。一个 Ceph 集群具体能够容忍的存储设备损坏数量根据配置的不同有所区别,详见 Erasure Code 一节。
查看存储空间
通过以下命令查看存储空间的整体使用情况:
sudo ceph df
通过以下命令查看每个 osd 的存储空间使用情况:
sudo ceph osd df
重启 mgr
mgr 负责集群的外围监控和管理,dashboard 即为 mgr 的一个组件。如果 dashboard 无法访问,可以尝试重启 mgr。
通过以下命令将当前正在运行的 mgr daemon 标记为失败,ceph 会自动重启该 daemon 并启用候补 daemon:
sudo ceph mgr fail
配置 crushmap
crushmap 用于指定数据如何存放到存储设备中,例如仅使用 hdd、仅使用 ssd、以 replicate 的形式、以 erasure code 的形式。
首先导出 crushmap:
sudo ceph osd getcrushmap -o comp_crush_map.cm
crushtool -d comp_crush_map.cm -o crush_map.cm
查看 crushmap:
$ cat crush_map.cm
...
# rules
rule replicated_hdd {
id 0
type replicated
step take default class hdd
step chooseleaf firstn 0 type osd
step emit
}
rule replicated_ssd {
id 1
type replicated
step take default class ssd
step chooseleaf firstn 0 type osd
step emit
}
rule ecpool-k4-m2 {
id 2
type erasure
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default class ssd
step choose indep 0 type osd
step emit
}
从上述 crushmap 示例可以看出:
type replicated表示 crush rule 是 replicate 类型type erasure表示 crush rule 是 erasure code 类型step take default class hdd表示 crush rule 仅使用 hddstep take default class ssd表示 crush rule 仅使用 ssdstep chooseleaf firstn 0 type osd表示 crush rule 在不同的 osd 中存储数据的多个备份
您可以编辑并通过以下命令应用 crushmap:
crushtool -c crush_map.cm -o new_crush_map.cm
sudo ceph osd setcrushmap -i new_crush_map.cm
然后即可配置 pool 使用新的 crush rule,参考配置 pool。
参考文档:
查看 pool
通过以下命令查看集群中所有的 pool
sudo ceph osd lspools
删除 pool
通过以下命令删除一个 pool:
sudo ceph osd pool rm <pool-name> <pool-name> --yes-i-really-really-mean-it
注意:pool 中的数据将被彻底删除,无法恢复,请小心操作。
配置 pool
如果 pool 的 crush rule 是 replicate 类型,可通过以下命令设置 replicate size:
sudo ceph osd pool set <pool-name> size <size> --yes-i-really-mean-it
sudo ceph osd pool set <pool-name> min_size <min-size>
一般情况下,replicate pool 的 size 为 3(表示数据会被复制 3 份),min_size 为 2(表示最少有 2 份数据才能正常工作)。
特殊情况下,例如底层存储已经有 RAID 容错机制,可将 size 和 min_size 都设为 1。
如果集群中有多个 crush rule,可通过以下命令为 pool 指定 crush rule:
sudo ceph osd pool set <pool-name> crush_rule <crush-rule-name>
参考文档:
查看 cephfs
通过以下命令查看集群中所有的 cephfs:
sudo ceph fs ls
删除 cephfs
为了删除一个 cephfs,首先将其标记为不可用:
sudo ceph fs fail <fs-name>
然后确认删除该 cephfs:
sudo ceph fs rm <fs-name> --yes-i-really-mean-it
参考删除 pool,删除该 cephfs 下属所有的 pool。
参考移除 daemon,移除该 cephfs 对应的所有 mds daemon。
挂载 cephfs
您可以通过 mount 命令在任意能够访问 Ceph 集群的机器上挂载 cephfs。
首先安装 ceph 工具:
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
chmod +x cephadm
sudo ./cephadm add-repo --release quincy
sudo ./cephadm install ceph-common
然后配置访问权限:
mkdir -p -m 755 /etc/ceph
ssh root@<ceph-admin-node-ip> "sudo ceph config generate-minimal-conf" | sudo tee /etc/ceph/ceph.conf
chmod 644 /etc/ceph/ceph.conf
ssh root@<ceph-admin-node-ip> "sudo ceph fs authorize <fs-name> client.foo / rw" | sudo tee /etc/ceph/ceph.client.foo.keyring
chmod 600 /etc/ceph/ceph.client.foo.keyring
最后执行 mount 命令:
mount -t ceph foo@<cluster-id>.<fs-name>=/ <mount-path> -o secret=<client-keyring>
例如:
mount -t ceph foo@f5e95c18-a869-11ed-ba9b-b95348587a43.k8s=/ /mnt/mycephfs -o secret=AQBFgglkj0N0CRAA0LHXD/QFerke3mZZ6W3UAw==
注意:不要直接在 Ceph 集群的节点上挂载 cephfs,这可能会造成死锁。但在容器中挂载 cephfs 是可以的。
参考文档:
配置 cephfs
cephfs 支持的最大文件大小默认是 1TiB,可通过以下命令修改:
sudo ceph fs set <fs-name> max_file_size <num-bytes>
例如,修改为 4TiB:
sudo ceph fs set <fs-name> max_file_size 4398046511104
查看 osd
通过以下命令查看集群中所有的 osd 和 pool:
sudo ceph osd dump
查看 pg
查看所有 pg 情况:
sudo ceph pg dump
查看某个 pool 中的所有 pg:
sudo ceph pg ls-by-pool <pool-name>
查看某个 osd 中的所有 pg
sudo ceph pg ls-by-osd <pool-name>
查看存在异常的所有 pg:
sudo ceph pg dump_stuck unclean
查看某个 pg 的详细情况:
sudo ceph pg <pg-id> query
参考文档:
调整 pg 数量
一般情况下,建议通过以下命令禁用 pg autoscaling,以便集群正常运行:
sudo ceph config set osd osd_pool_default_pg_autoscale_mode off
禁用 pg autoscaling 后,通过以下命令设置每个 pool 的 pg 数量:
sudo ceph osd pool set <pool-name> pg_num <num>
sudo ceph osd pool set <pool-name> pgp_num <num>
例如:
sudo ceph osd pool set default.rgw.buckets.data pg_num 256
sudo ceph osd pool set default.rgw.buckets.data pgp_num 256
根据 Red Hat 文档,推荐每个 osd 约 100~200 个 pg。
修复 pg
当集群的存储策略发生变化时,数据在重新平衡的过程中,pg 可能卡住,可尝试以下方式修复 pg:
sudo ceph pg force-backfill <pg-id>
sudo ceph pg force-recovery <pg-id>
sudo ceph pg repeer <pg-id>
手动 scrub / deep scrub
scrub 是指 Ceph 对 pg 中的数据进行一致性验证,通常每天进行一次。
deep scrub 是一种更深层次的 scrub,会读取数据的每个 bit 并计算 checksum,通常每周进行一次。
对某个 pg 进行 scrub / deep scrub:
sudo ceph pg scrub <pg-id>
sudo ceph pg deep-scrub <pg-id>
对某个 osd 上的所有 pg 进行 scrub / deep scrub:
sudo ceph osd scrub <osd-id>
sudo ceph osd deep-scrub <osd-id>
对某个 pool 中的所有 pg 进行 scrub / deep scrub:
sudo ceph osd pool scrub <pool-name>
sudo ceph osd pool deep-scrub <pool-name>
参考文档:
修改集群配置
Ceph 集群有非常多的配置可以实时修改。
查看某项配置的命令格式如下:
sudo ceph config get <who> <config-key>
修改某项配置的命令格式如下:
sudo ceph config set <who> <config-key> <config-value>
其中,<who> 表示该项配置对应的服务,如 mon、osd 等。
例如,获取 osd 中最多能够同时进行多少个 backfill 操作:
sudo ceph config get osd osd_max_backfills
设置该项配置的值为 8:
sudo ceph config set osd osd_max_backfills 8
参考文档:
调整数据平衡速度
当集群的存储策略发生变化时,数据会在 osd 之间进行重新平衡。如果期望尽快完成数据平衡,可以调整以下设置:
| Name | Default | Now |
| osd_max_backfills | 1 | 8 |
| osd_recovery_max_active_hdd | 3 | 8 |
| osd_recovery_priority | 5 | 1 |
| osd_recovery_op_priority | 3 | 1 |
| osd_recovery_max_single_start | 1 | 8 |
| osd_recovery_sleep_hdd | 0.1 | 0 |
注意:调整上述配置会极大地影响正常的读写速度,最好在无人使用的情况下进行,并在数据平衡完成后重新调整为默认值。
删除集群
注意,此为危险操作,数据将全部丢失。
如果确认需要删除整个 Ceph 集群,可以从非管理节点开始,逐一在每个节点上运行以下命令:
sudo apt update
sudo apt install ceph-deploy -y
sudo ceph-deploy purge <hostname>
sudo rm -rf /var/lib/ceph/*
通过以下命令格式化 Ceph 使用过的存储设备:
sudo sgdisk --zap-all <device-path>
例如:
sudo sgdisk --zap-all /dev/sdb
然后重启节点,才能恢复存储设备的状态:
sudo reboot
K8s 集成
通过 Ceph CSI,K8s 可以利用 Ceph 作为 PVC 的存储提供者(Provisioner)。
配置 Ceph CSI
首先,在 Ceph 集群中创建一个名为 demo-fs 的 Ceph File System 和一个名为 demo-user 的 Ceph 用户,在管理节点中执行以下命令即可:
$ sudo ceph fs volume create demo-fs
$ sudo ceph auth get-or-create client.demo-user mon 'allow r' \
osd 'allow rw tag cephfs *=*' mgr 'allow rw' mds 'allow rw'
[client.demo-user]
key = AQAhuZBjSuS9AxBD77AvVjr+vAg9zhjRK7NR+g==
注意上述生成的 key 值后面会用到。
然后,查看 Ceph 集群的一些相关信息,在管理节点中执行以下命令即可:
$ sudo ceph mon dump
epoch 2
fsid 47f20cbc-914f-24ed-93dc-9f2800951ba2
last_changed 2023-01-12T06:01:55.659954+0000
created 2023-01-11T01:30:12.337519+0000
min_mon_release 17 (quincy)
election_strategy: 1
0: [v2:10.0.0.1:3300/0,v1:10.0.0.1:6789/0] mon.ds01
1: [v2:10.0.0.2:3300/0,v1:10.0.0.2:6789/0] mon.e01
dumped monmap epoch 2
注意上述输出中的 fsid (47f20cbc-914f-24ed-93dc-9f2800951ba2) 和节点列表 (10.0.0.1:6789, 10.0.0.2:6789),后面会用到。
最后,在 K8s 集群中创建相关资源,包括 ConfigMap、Secret、Deployment、DaemonSet 等等。
git clone https://github.com/ceph/ceph-csi.git
cd ceph-csi/examples
编辑 csi-config-map-sample.yaml,填入上面的 fsid 和节点列表,除此之外的其他项可以删除,示例如下:
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
[
{
"clusterID": "47f20cbc-914f-24ed-93dc-9f2800951ba2",
"monitors": [
"10.0.0.1:6789",
"10.0.0.2:6789"
]
}
]
metadata:
name: ceph-csi-config
编辑 cephfs/secret.yaml,填入上面创建的用户名和 key 值,除此之外的其他项可以删除,示例如下:
apiVersion: v1
kind: Secret
metadata:
name: csi-cephfs-secret
namespace: default
stringData:
# Required for dynamically provisioned volumes
adminID: demo-user
adminKey: AQB7JL5jugJwFxAA+szhrjIi48JhJbZsI3feRg==
编辑 cephfs/storageclass.yaml,填入上面的 fsid 和 Ceph File System 名称,示例如下:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-cephfs
provisioner: cephfs.csi.ceph.com
parameters:
clusterID: 47f20cbc-914f-24ed-93dc-9f2800951ba2
fsName: demo-fs
csi.storage.k8s.io/provisioner-secret-name: csi-cephfs-secret
csi.storage.k8s.io/provisioner-secret-namespace: default
csi.storage.k8s.io/controller-expand-secret-name: csi-cephfs-secret
csi.storage.k8s.io/controller-expand-secret-namespace: default
csi.storage.k8s.io/node-stage-secret-name: csi-cephfs-secret
csi.storage.k8s.io/node-stage-secret-namespace: default
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
- debug
按照 README.md 中的指引,执行以下命令在 K8s 集群中依次创建所需资源:
kubectl apply -f ./ceph-conf.yaml
kubectl apply -f ./csi-config-map-sample.yaml
kubectl apply -f ./cephfs/secret.yaml
kubectl apply -f ./cephfs/storageclass.yaml
cd ../../deploy/cephfs/kubernetes
kubectl create -f ./csi-provisioner-provisioner.yaml
kubectl create -f ./csi-nodeplugin-rbac.yaml
kubectl create -f ./csi-cephfsplugin-provisioner.yaml
kubectl create -f ./csi-cephfsplugin.yaml
kubectl create -f ./csidriver.yaml
注意,上述资源均默认在 default namespace 中创建。
等待所创建的 Pod 成功运行后,即可创建基于 Ceph 的 PVC。
kubectl get pod -w
通过 Helm Chart 配置 Ceph CSI
理论上,我们可以在同一个 K8s 集群中部署两套 Ceph CSI,提供两个 Storage Class 以供用户使用。
在部署过程中:
- 对于 Ceph 集群,我们需要创建两个不同的 Ceph Filesystem 及对应的用户
- 对于 K8s 集群,我们需要创建两个不同的命名空间,并对 Storage Class、ClusterRole、ClusterRoleBinding 等集群级别资源使用不同的名称
为了方便部署,我们提供了 Helm Chart(点击此处下载),您只需要在 values.yaml 中填写参数即可。
values.yaml 示例如下:
ceph:
storageClassName: sc-cephfs
driverName: cephfs.csi.ceph.com
clusterID: 47f20cbc-914f-24ed-93dc-9f2800951ba2
fsName: demo-fs
adminID: demo-user
adminKey: AQAhuZBjSuS9AxBD77AvVjr+vAg9zhjRK7NR+g==
metricsPort: 8681
monitors:
- "10.0.0.1:6789"
- "10.0.0.2:6789"
# erasureCode: true
# pool: ecpool-k4-m2
images:
cephCSI: quay.io/cephcsi/cephcsi:v3.8.0
csiProvisioner: registry.k8s.io/sig-storage/csi-provisioner:v3.3.0
csiResizer: registry.k8s.io/sig-storage/csi-resizer:v1.6.0
csiSnapshotter: registry.k8s.io/sig-storage/csi-snapshotter:v6.1.0
csiNodeDriverRegistrar: registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.6.2
运行以下命令在 K8s 集群中创建相关资源:
unzip cephcsi-helmchart.zip
helm template ./cephcsi-helmchart -n cephfs -o ./deploy.yaml
kubectl create ns cephfs
kubectl create -n cephfs -f ./deploy.yaml
kubectl get pod -n cephfs -w
创建 PVC 并绑定 Pod
在 PVC spec 中指定 StorageClass 名称即可创建基于 Ceph 存储集群的 PVC。例如,配置 Ceph CSI 一节中创建了名为 sc-cephfs 的 Storage Class,通过如下 YAML 创建 PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: sc-cephfs
然后创建 Pod 绑定该 PVC:
apiVersion: v1
kind: Pod
metadata:
name: cephfs-demo-pod
spec:
containers:
- name: web-server
image: nginx:latest
resources:
limits:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: cephfs-pvc
mountPath: /var/lib/www
volumes:
- name: cephfs-pvc
persistentVolumeClaim:
claimName: cephfs-pvc
查看 PVC 创建/绑定失败原因
如果创建 PVC 和 Pod 后,Pod 一直无法正常运行,请按照以下步骤查找原因:
1. 查看 PVC 是否创建成功
运行以下命令获取 PVC 信息:
kubectl get pvc cephfs-pvc
如果 STATUS 字段是 Bound,则转至第 2 步。
如果 STATUS 字段是 Pending,说明 PVC 没有 provision 成功,请查看 Ceph CSI Provisioner Pod 的日志寻找原因。
通过以下命令获取 Ceph CSI Provisioner Pod 名称:
$ kubectl get pod -n cephfs -l app=csi-cephfsplugin-provisioner
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-provisioner-5b77dc5fff-56mr9 6/6 Running 0 6d21h
csi-cephfsplugin-provisioner-5b77dc5fff-rcpbg 6/6 Running 0 6d21h
csi-cephfsplugin-provisioner-5b77dc5fff-tkmsh 6/6 Running 0 6d21h
其中只有一个 Pod 是主要的工作 Pod,另外两个处于待命状态。通过以下命令查看其日志:
kubectl logs -n cephfs csi-cephfsplugin-provisioner-5b77dc5fff-56mr9 csi-provisioner
2. 查看 PVC 与 Pod 是否绑定成功
运行以下命令获取 Pod 信息:
kubectl describe pod cephfs-demo-pod
输出结果中的 Events 字段会显示 PVC 绑定不成功的原因。
另外,查看 Ceph CSI Plugin Pod 日志也有助于查找原因。
首先,通过以下命令查看所创建的 Pod 位于哪个节点上:
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
cephfs-demo-pod 1/1 Running 0 6d22h 10.233.106.203 nc13
然后,通过以下命令找到位于同一个节点上的 Ceph CSI Plugin Pod:
$ kubectl get pod -n cephfs -l app=csi-cephfsplugin -o wide
NAME READY STATUS RESTARTS AGE IP NODE
csi-cephfsplugin-55nc4 3/3 Running 0 3d1h 100.64.4.74 nc14
csi-cephfsplugin-dd99m 3/3 Running 0 3d1h 100.64.4.199 nuc
csi-cephfsplugin-jcxv6 3/3 Running 0 3d1h 100.64.4.71 nc11
csi-cephfsplugin-jf4mn 3/3 Running 0 3d1h 100.64.4.209 acer
csi-cephfsplugin-jhffm 3/3 Running 0 3d1h 10.0.0.2 e01
csi-cephfsplugin-mxjh2 3/3 Running 0 3d1h 100.64.4.73 nc13
csi-cephfsplugin-rdbbp 3/3 Running 0 3d1h 100.64.4.72 nc12
csi-cephfsplugin-vql6n 3/3 Running 0 3d1h 100.64.4.132 kylin
最后,通过以下命令查看该 Ceph CSI Plugin Pod 的日志:
kubectl logs -n cephfs csi-cephfsplugin-mxjh2 csi-cephfsplugin
如果仍然无法找到问题原因,可尝试重启该 Ceph CSI Plugin Pod:
kubectl delete -n cephfs csi-cephfsplugin-mxjh2
如果上述删除命令卡住,可通过以下命令强行删除该 Ceph CSI Plugin Pod:
kubectl delete -n cephfs csi-cephfsplugin-mxjh2 --force
PVC 备份
为了支持 PVC 备份,首先需要在 K8s 中启用 Volume Snapshot 功能;其次,需要针对不同的 PVC Provisioner 创建 VolumeSnapshotClass。
Ceph CSI 提供了对应的 VolumeSnapshotClass 资源,其 YAML 如下(来源):
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-cephfsplugin-snapclass
driver: cephfs.csi.ceph.com
parameters:
# String representing a Ceph cluster to provision storage snapshot from.
# Should be unique across all Ceph clusters in use for provisioning,
# cannot be greater than 36 bytes in length, and should remain immutable for
# the lifetime of the StorageClass in use.
# Ensure to create an entry in the configmap named ceph-csi-config, based on
# csi-config-map-sample.yaml, to accompany the string chosen to
# represent the Ceph cluster in clusterID below
clusterID: 47f20cbc-914f-24ed-93dc-9f2800951ba2
# Prefix to use for naming CephFS snapshots.
# If omitted, defaults to "csi-snap-".
# snapshotNamePrefix: "foo-bar-"
csi.storage.k8s.io/snapshotter-secret-name: csi-cephfs-secret
csi.storage.k8s.io/snapshotter-secret-namespace: default
deletionPolicy: Delete
与配置 Ceph CSI 一节类似,YAML 中需要填入 Ceph File System 的 fsid。
针对创建 PVC 并绑定 Pod 一节中所创建的名为 cephfs-pvc 的 PVC,我们创建一个 VolumeSnapshot 来对其进行备份,YAML 如下(来源):
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: cephfs-pvc-snapshot
spec:
volumeSnapshotClassName: csi-cephfsplugin-snapclass
source:
persistentVolumeClaimName: cephfs-pvc
查看所创建的备份:
kubectl describe volumesnapshot cephfs-pvc-snapshot
基于该备份创建一个新的 PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc-restore
spec:
storageClassName: tsz-cephfs
dataSource:
name: cephfs-pvc-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
然后创建一个新的 Pod 绑定该 PVC:
apiVersion: v1
kind: Pod
metadata:
name: cephfs-restore-demo-pod
spec:
containers:
- name: web-server
image: nginx:latest
resources:
limits:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: cephfs-pvc-restore
mountPath: /var/lib/www
volumes:
- name: cephfs-pvc-restore
persistentVolumeClaim:
claimName: cephfs-pvc-restore
最后,进入 Pod 查看 PVC 中的内容是否与之前相同:
kubectl exec -it cephfs-restore-demo-pod -- /bin/bash
ls /var/lib/www
在 K8s 中启用 Volume Snapshot 功能
根据官方博客,Volume Snapshot 特性从 K8s 1.20 版本开始 GA。
通过以下命令查看 K8s 版本:
kubectl version
通过以下命令查看 K8s 中是否已经安装 Volume Snapshot 相关组件:
kubectl get deploy -n kube-system snapshot-controller
kubectl api-resouces | grep volumesnapshot
如果尚未安装,可以根据官方文档,手动安装 CRD、controller、webhook 等组件:
git clone https://github.com/kubernetes-csi/external-snapshotter.git
cd external-snapshotter
kubectl kustomize client/config/crd | kubectl create -f -
kubectl -n kube-system kustomize deploy/kubernetes/snapshot-controller | kubectl create -f -
配额管理
PVC 能够使用的最大存储空间由其 spec 指定,K8s 集群中所有基于 Ceph 的 PVC 总共能够使用的最大存储空间可通过 Ceph File System 的底层 Pool 来限制。
在任意管理节点上运行以下命令列举所有 Pool:
$ sudo ceph osd pool ls
.mgr
cephfs.demo-fs.meta
cephfs.demo-fs.data
其中,名为 cephfs.demo-fs.data 的 Pool 就是名为 demo-fs 的 Ceph File System 存储数据的 Pool,通过以下命令限制该 Pool 能够使用的最大存储空间:
sudo ceph osd pool set-quota cephfs.demo-fs.data max_bytes 10000000
参考文档:
S3 集成
创建 S3 服务
在管理节点上运行以下命令创建一个名为 cephs3 的 RGW 服务(RadosGateWay,用于对外提供兼容 S3 的对象存储服务):
sudo ceph orch apply rgw cephs3
然后创建一个能够访问该 RGW 服务的用户,名为 demo-s3-user:
$ sudo radosgw-admin user create --uid=demo-s3-user --display-name=demo-s3-user --system
{
"user_id": "demo-s3-user",
"display_name": "demo-s3-user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "t9k",
"access_key": "ZVXDTZLORTYJHM8KMY4A",
"secret_key": "T94j1EqxXZ3pc0jPbm3kNREcLfZADMMYDiim4UOq"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"system": "true",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
注意,上面生成的 access_key 和 secret_key 即可用于通过 S3 协议访问对象存储服务。
配置 Web UI 能够展示对象存储服务的详细信息:
sudo ceph dashboard set-rgw-api-access-key -i <file-containing-access-key>
sudo ceph dashboard set-rgw-api-secret-key -i <file-containing-secret-key>
参考文档:
配置 erasure code
如果需要节省存储空间,可以配置 rgw 使用 erasure code pool 来存储数据。
注意,需要在 rgw 尚未被使用时完成此操作。
首先,列举 rgw 所使用的 pool,rgw 通常会创建名称以 default.rgw 开头的多个 pool:
$ sudo ceph osd lspools
...
8 default.rgw.log
9 default.rgw.control
10 default.rgw.meta
11 default.rgw.buckets.index
12 default.rgw.buckets.data
...
其中,default.rgw.buckets.data 是主要用来存储数据的 pool,它默认是 replicate 类型。由于 replicate pool 不能直接转换为 erasure code pool,我们需要停止 rgw daemon,删除 data pool,重新创建 data pool 为 erasure code 类型,最后重新创建 rgw daemon。
sudo ceph orch rm rgw.cephs3.us-east-1
sudo ceph config set mon mon_allow_pool_delete true
sudo ceph osd pool rm default.rgw.buckets.data default.rgw.buckets.data --yes-i-really-really-mean-it
sudo ceph osd pool create default.rgw.buckets.data erasure ecprofile-k2-m1-hdd
sudo ceph osd pool application enable default.rgw.buckets.data rgw
sudo ceph orch apply rgw cephs3
参考文档:
配置 S3 服务
如果需要指定 rgw 服务的详细配置,可以通过应用 yaml 配置文件来实时修改 rgw 服务。
通过以下命令导出 rgw 服务的详细配置:
sudo ceph orch ls --service_type rgw --export > rgw.yaml
rgw.yaml 示例如下:
service_type: rgw
service_id: cephs3
service_name: rgw.cephs3
placement:
hosts:
- host1
修改 rgw.yaml 为以下内容:
service_type: rgw
service_id: cephs3
service_name: rgw.cephs3
placement:
count: 2
hosts:
- host1
- host2
networks:
- 172.0.0.0/24
spec:
rgw_frontend_port: 8081
其中:
- 配置 rgw daemon 为 2 个,host1 节点、host2 节点各一个
- 配置 rgw daemon 使用 172.0.0.0/24 网络
- 配置 rgw daemon 使用 8081 端口
通过以下命令应用该配置文件:
sudo ceph orch apply -i ./rgw.yaml
使用 S3 服务
首先您需要获取 rgw 服务的地址。
参考查看 daemon 状态,查看 rgw 服务的配置,示例如下:
$ ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
rgw.cephs3 ?:8081 2/2 6m ago 2w host1;host2;count:2
可以看到 rgw 服务运行在 host1 和 host2 节点的 8081 端口。
参考查看节点,查看节点的 ip 地址,示例如下:
$ ceph orch host ls
HOST ADDR LABELS STATUS
host1 172.0.0.1
host2 172.0.0.2
因此,rgw 服务的地址为 http://172.0.0.1:8081 和 http://172.0.0.1:8081,任选其中一个访问即可。
运行以下命令通过 S3 协议访问 rgw 服务:
$ cat > ~/.s3cfg << EOF
host_base = http://172.0.0.1:8081
host_bucket = http://172.0.0.1:8081
bucket_location = us-east-1
use_https = False
access_key = ZVXDTZLOFRTJHM8KMY4A
secret_key = T94j1EqxXZ3pl9jkjm3kNREcLfZADMMYDiim4UOq
signature_v2 = False
EOF
$ s3cmd ls
$ s3cmd mb s3://mybucket
$ s3cmd ls
配额管理
对于对象存储服务,Ceph 支持针对 bucket 或者 user 进行配额管理。
在任意管理节点运行以下命令,对名为 demo-s3-user 的 user 设置配额:
sudo radosgw-admin quota set --quota-scope=user --uid=demo-s3-user --max-size=1024B
sudo radosgw-admin quota enable --quota-scope=user --uid=demo-s3-user
对名为 demo-s3-user 的 user 所创建的所有 bucket 设置配额:
sudo radosgw-admin quota set --quota-scope=bucket --uid=demo-s3-user --max-size=1024B
sudo radosgw-admin quota enable --quota-scope=bucket --uid=demo-s3-user
查看 demo-s3-user 的配额设置:
sudo radosgw-admin user info --uid=demo-s3-user
参考文档:
常见故障
PVC 创建/绑定失败
K8s 节点网络断开后恢复,但是运行在节点上的 Pod 仍然报错
如果 K8s 集群网络断开后恢复,但是 Pod 出现如下报错:
$ k describe po -n aim-yyx managed-notebook-c26a6-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11m t9k-scheduler Successfully assigned demo/managed-notebook-c26a6-0 to node1
Warning FailedMount 7m38s (x2 over 9m54s) kubelet Unable to attach or mount volumes: unmounted volumes=[datadir], unattached volumes=[pep-config workingdir datadir managed-notebook-c26a6 kube-api-access-2wbpn]: timed out waiting for the condition
Warning FailedMount 3m2s (x2 over 5m20s) kubelet Unable to attach or mount volumes: unmounted volumes=[datadir], unattached volumes=[pep-config workingdir datadir managed-notebook-c26a6 kube-api-access-2wbpn]: timed out waiting for the condition
Warning FailedMount 99s (x13 over 11m) kubelet MountVolume.SetUp failed for volume "pvc-003a5630-b230-406f-9493-2f66653f768c" : rpc error: code = Internal desc = stat /var/lib/kubelet/plugins/kubernetes.io/csi/cephfs.csi.ceph.com/d542aa1dad943aea439969def75da7d1ded28a5fcdbae0657f2b7bd0dd98c694/globalmount: permission denied
Warning FailedMount 48s kubelet Unable to attach or mount volumes: unmounted volumes=[datadir], unattached volumes=[pep-config workingdir datadir managed-notebook-c26a6 kube-api-access-2wbpn]: timed out waiting for the condition
根据 GitHub issue,原因是因为 ceph-csi 没有正确处理 mount point 由于长时间没有响应被 linux kernel 驱逐的情况。
暂时的解决办法是重启 Pod 所在的节点:
kubectl drain <node>
# reboot <node>
kubectl uncordon <node>
mpath 设备所在节点重启后,OSD 报错
参考集群安装 - mpath 设备,当 mpath 设备所在的节点重启时,lv 可能变为 unavailable 状态,导致 osd 异常,需要通过以下命令重新激活 lv:
sudo lvchange -ay /dev/vgmpatha/lv0