进行数据并行训练
本教程演示使用 PyTorchTrainingJob 对 PyTorch 模型进行多工作器同步训练(使用 torch.nn.parallel.DistributedDataParallel 分布式数据并行模块)。本教程对应示例使用 PyTorchTrainingJob 进行数据并行训练。
本教程的 Apps 架构如下图所示:

准备工作
创建一个名为 tutorial、大小 1 Gi 的 PVC,然后安装一个同样名为 tutorial 的 JupyterLab App 挂载该 PVC,镜像和资源不限。
进入 JupyterLab,启动一个终端,执行以下命令以克隆 t9k/tutorial-examples 仓库:
cd ~
git clone https://github.com/t9k/tutorial-examples.git
启动训练(创建 PyTorchTrainingJob)
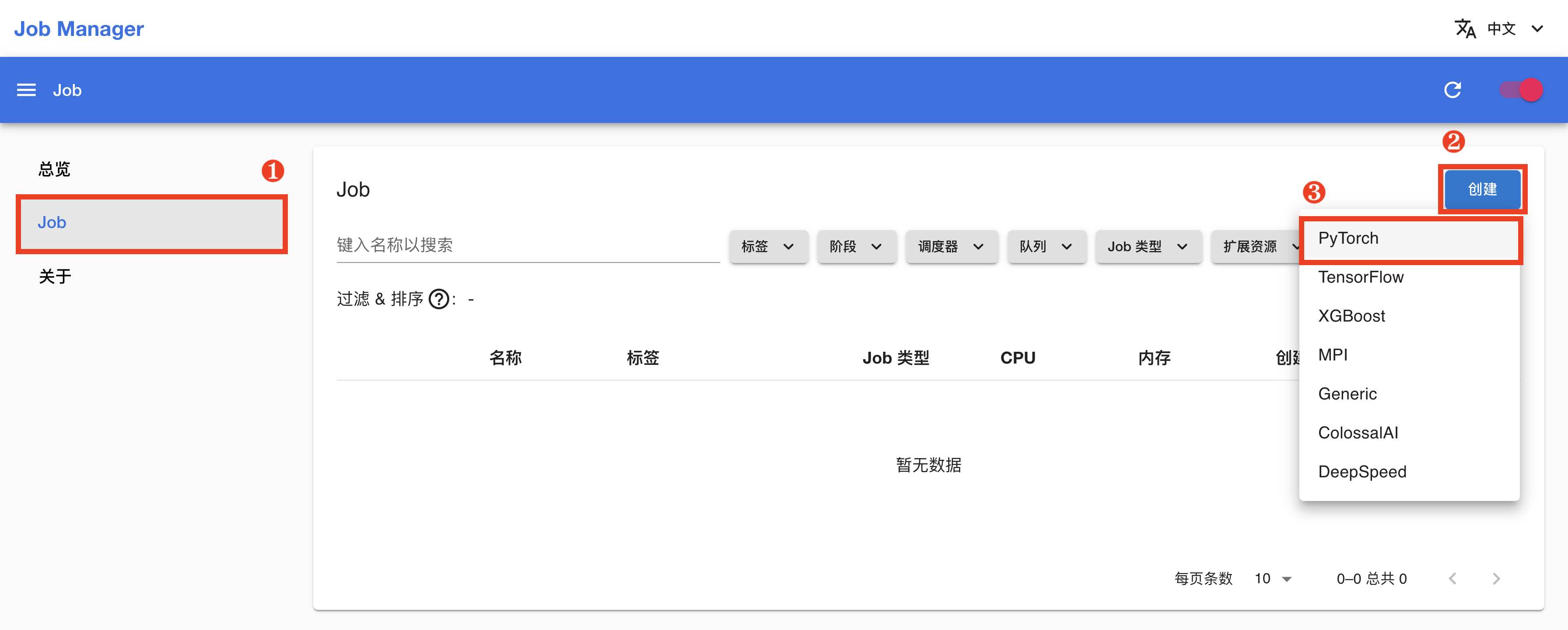
安装一个 Job Manager App(如有 Job Manager 则直接复用),进入 Job Manager 的网页 UI(控制台)。在左侧导航菜单点击 Job 进入 Job 管理页面,这里展示了所有已创建的 Job。点击右上角的创建,然后点击 PyTorch 进入 PyTorchTrainingJob 创建页面:
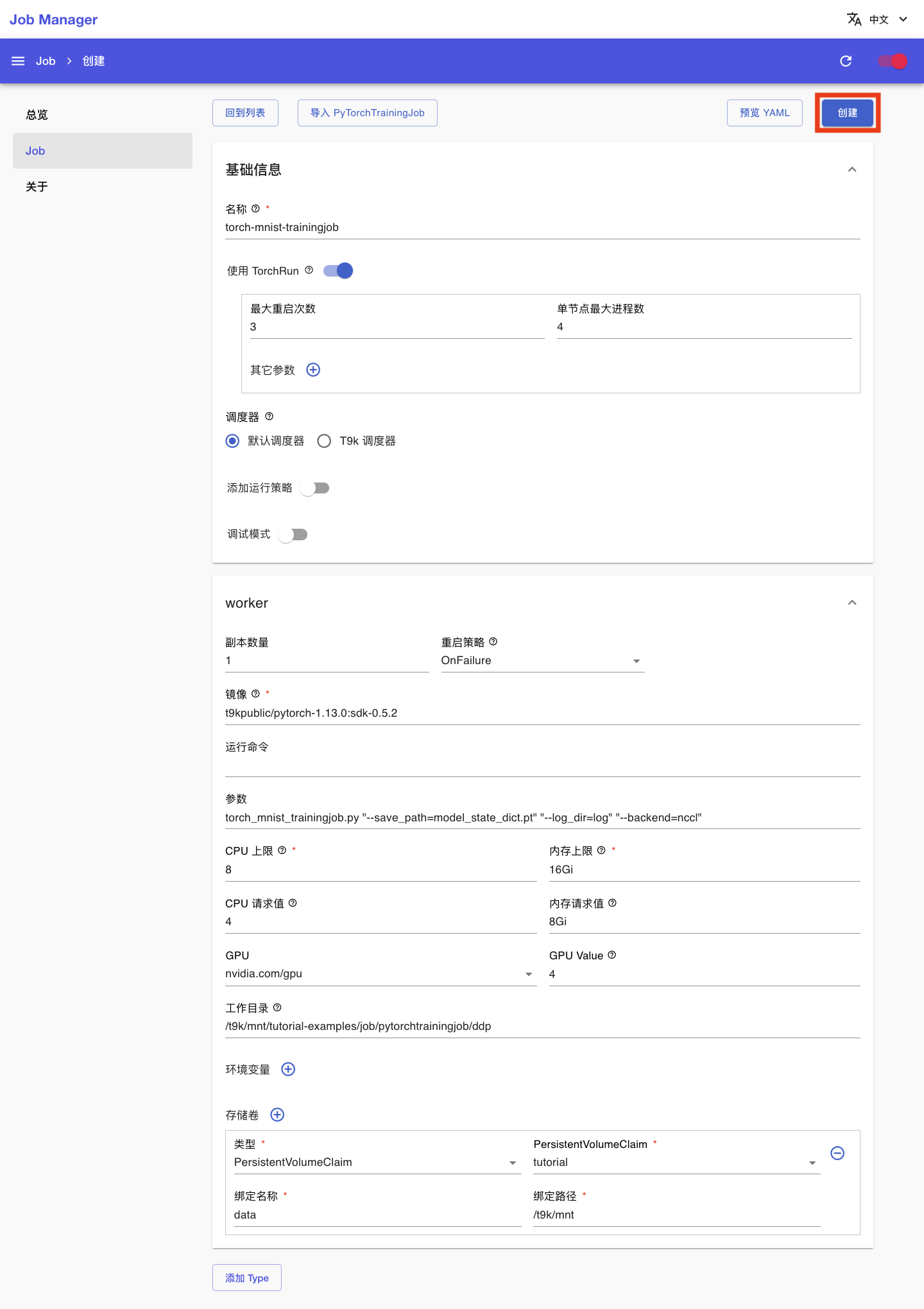
在 PyTorchTrainingJob 创建页面,填写配置如下:
- 基本信息部分:
- 名称填写
torch-mnist-trainingjob - 打开使用 TorchRun,最大重启次数填写
3,单节点最大进程数填写4
- 名称填写
- worker 部分:
- 镜像填写
t9kpublic/pytorch-1.13.0:sdk-0.5.2 - 参数填写
torch_mnist_trainingjob.py "--save_path=model_state_dict.pt" "--log_dir=log" "--backend=nccl" - CPU 上限和内存上限分别填写
8和16Gi,CPU 请求值和内存请求值分别填写4和8Gi - GPU 选择
nvidia.com/gpu,GPU Value 填写4 - 工作目录填写
/t9k/mnt/tutorial-examples/job/pytorchtrainingjob/ddp - 添加一个存储卷,PersistentVolumeClaim 选择
tutorial,绑定名称填写data,绑定路径填写/t9k/mnt
- 镜像填写
然后点击创建:
查看训练信息(查看 PyTorchTrainingJob 详情)
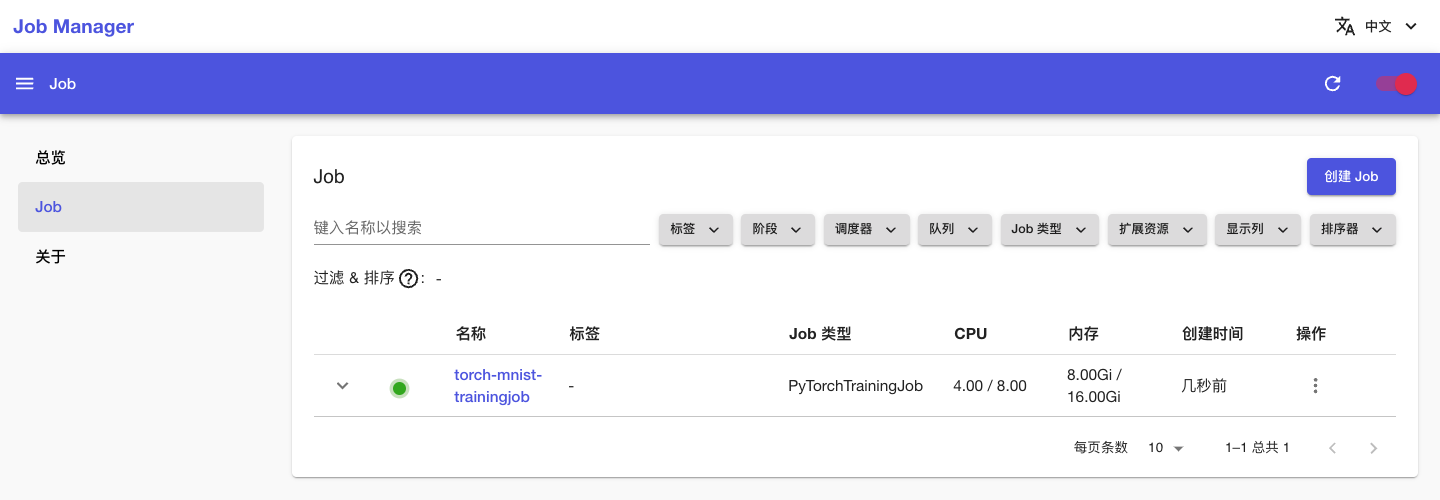
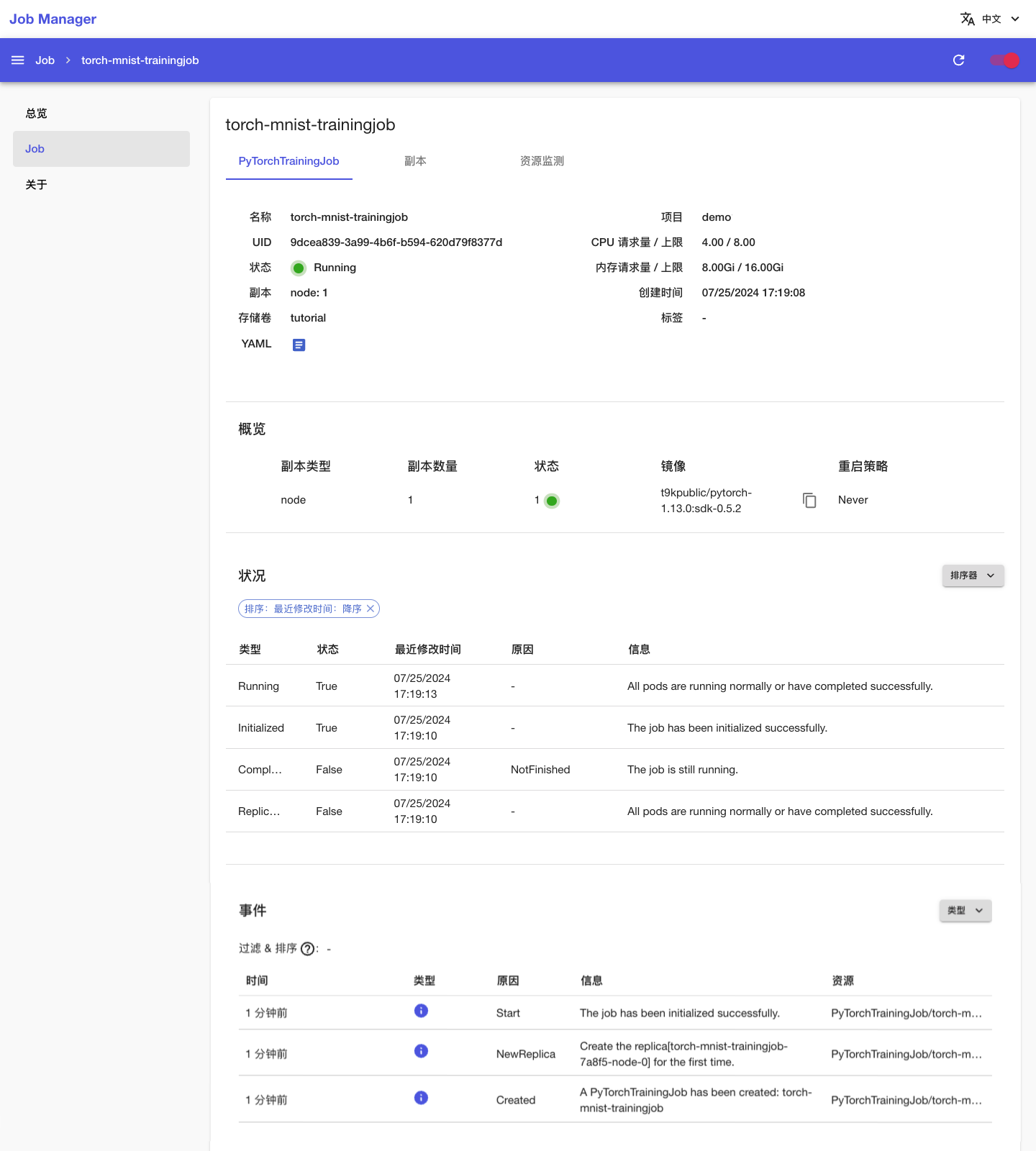
回到 Job 管理页面,可以看到名为 torch-mnist-trainingjob 的 PyTorchTrainingJob 正在运行,点击其名称进入详情页面:
可以看到刚才创建的 PyTorchTrainingJob 的基本信息,以及状况和事件信息:
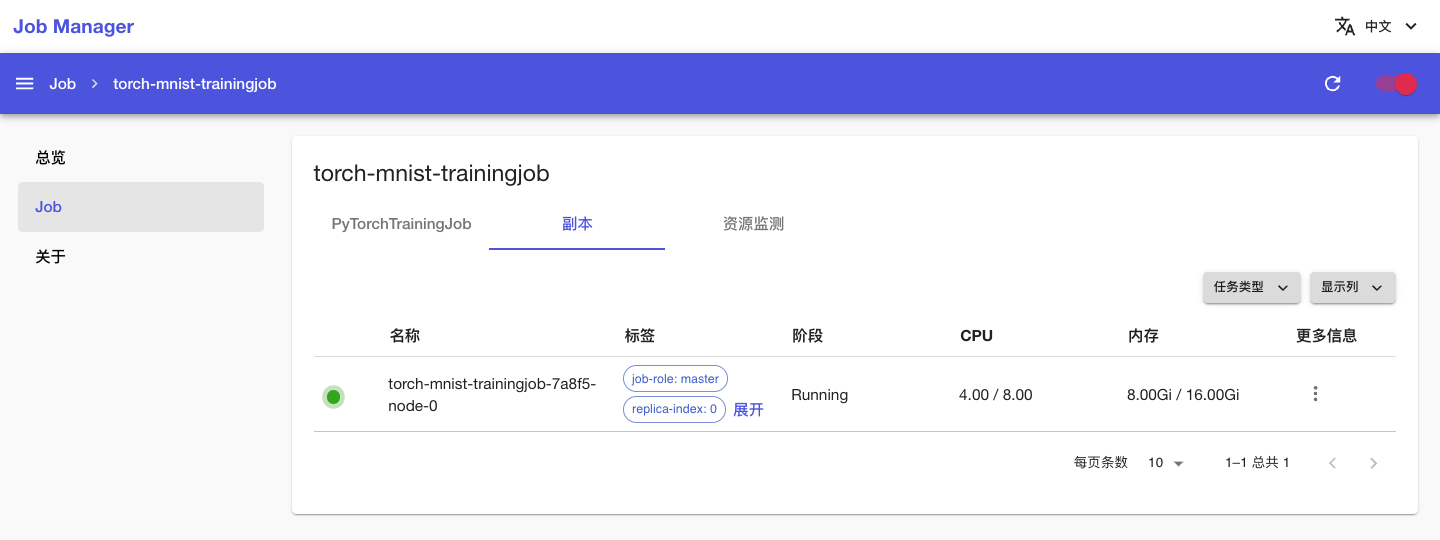
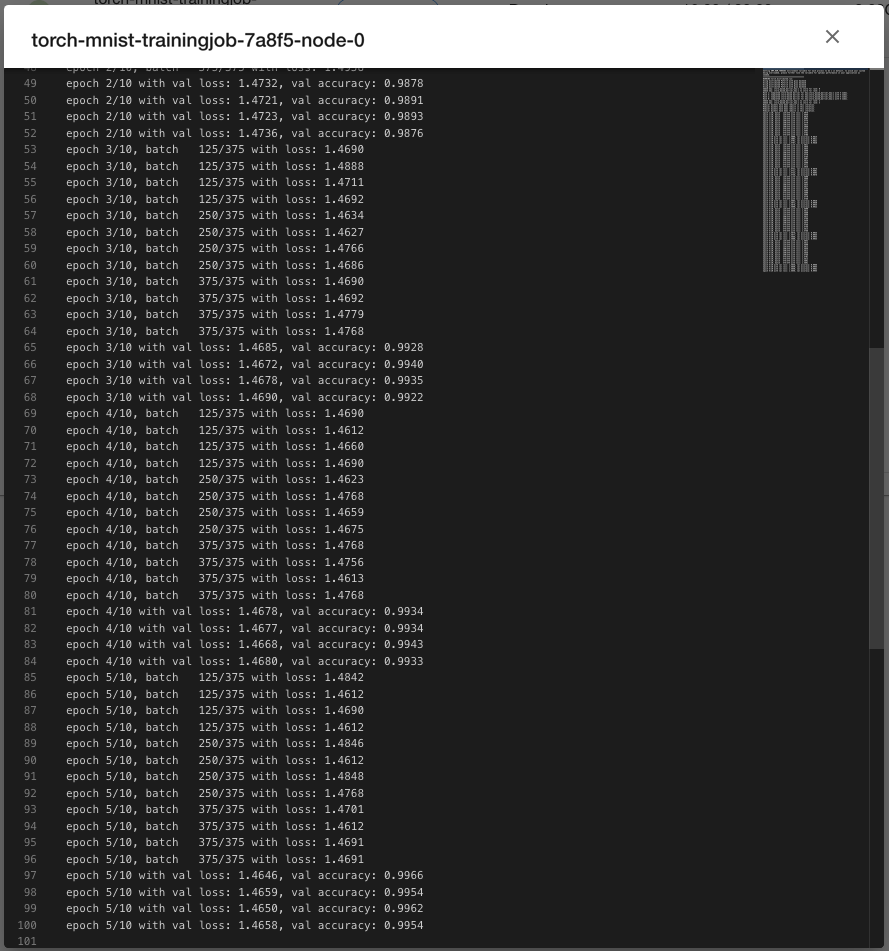
点击上方的副本标签页,查看 PyTorchTrainingJob 的 Pod 信息;点击副本右侧的 > 日志以查看训练脚本执行过程中的日志输出:
点击上方的资源监测标签页,查看 PyTorchTrainingJob 运行过程中使用集群计算资源、网络资源和存储资源的情况:
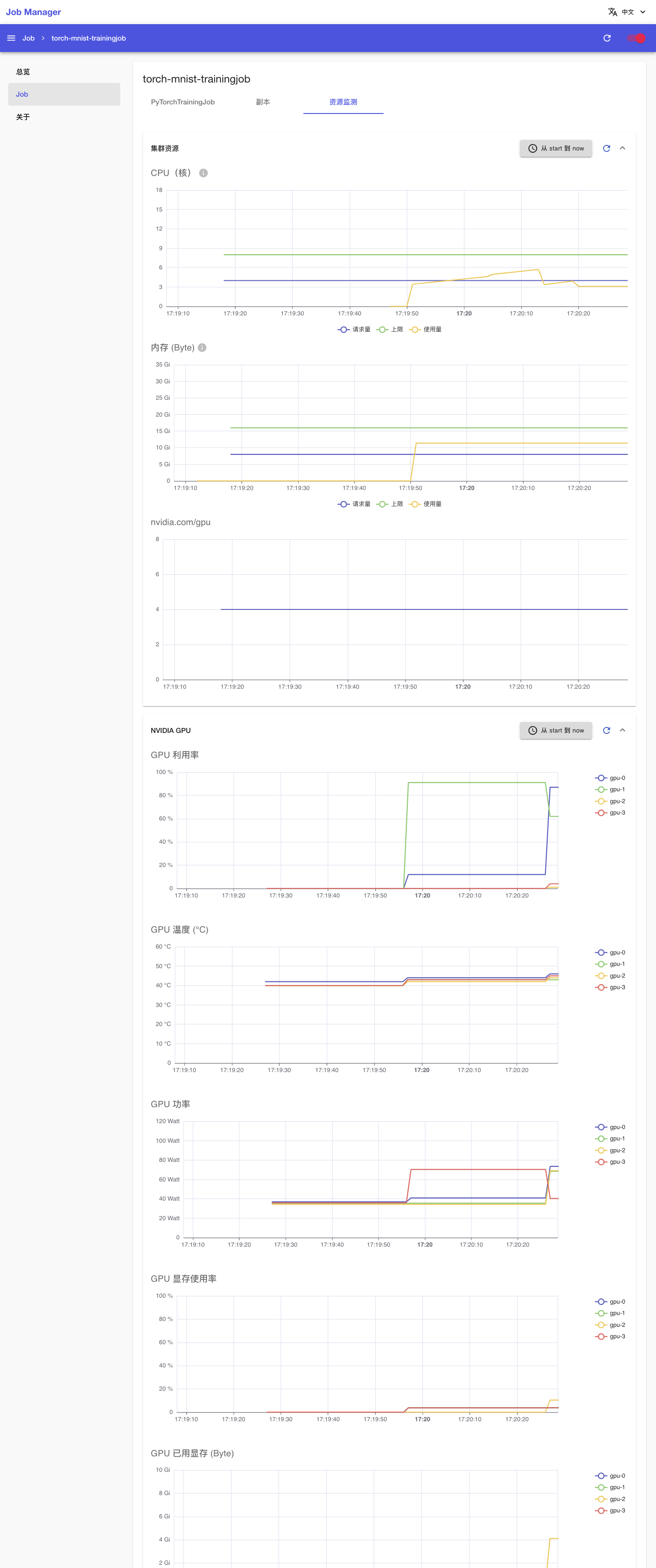
一段时间之后,PyTorchTrainingJob 的状态变为 Succeeded,表示训练成功完成。
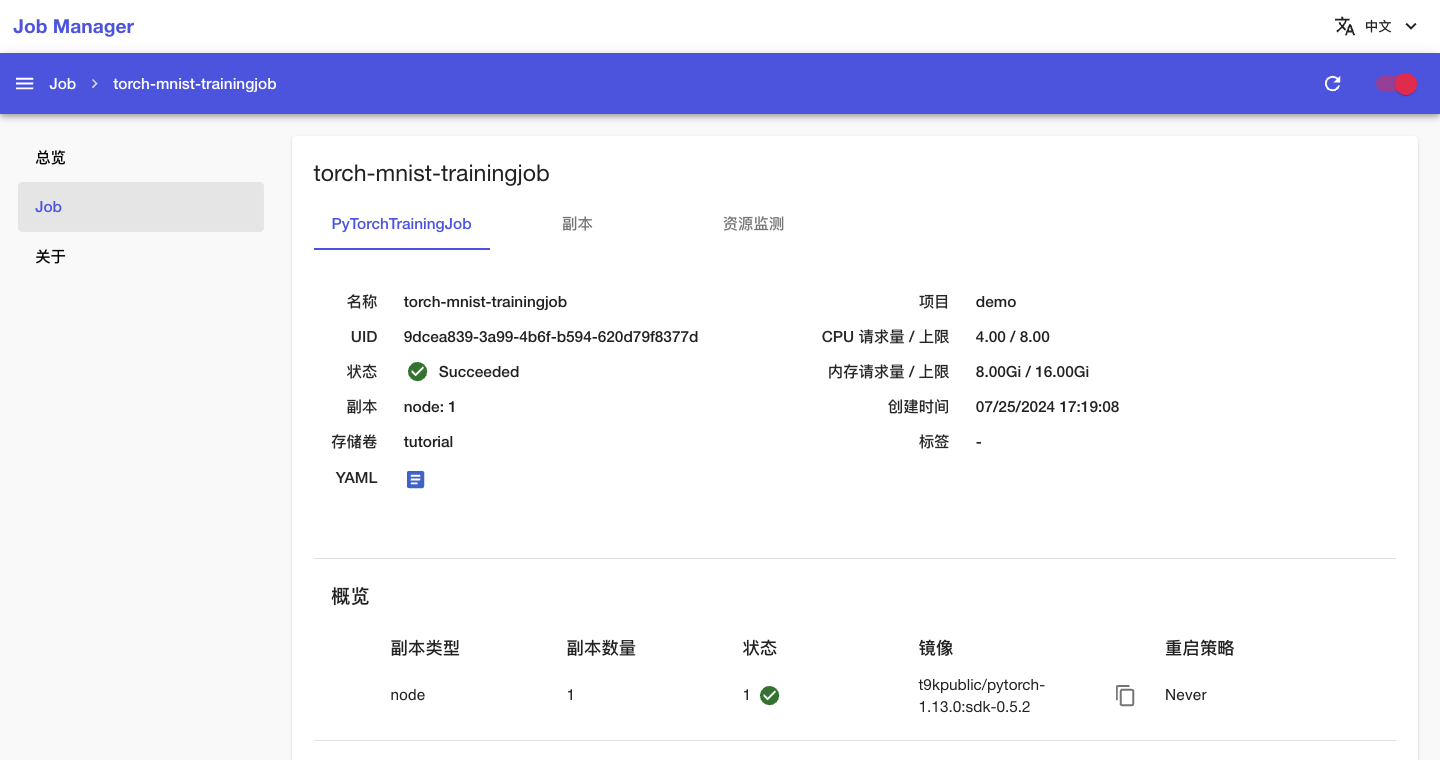
若 PyTorchTrainingJob 在运行过程中出错,其状态会变为 Error,并在事件信息和 Pod 信息部分显示错误信息,此时需要根据给出的错误信息进行问题排查。
查看训练指标
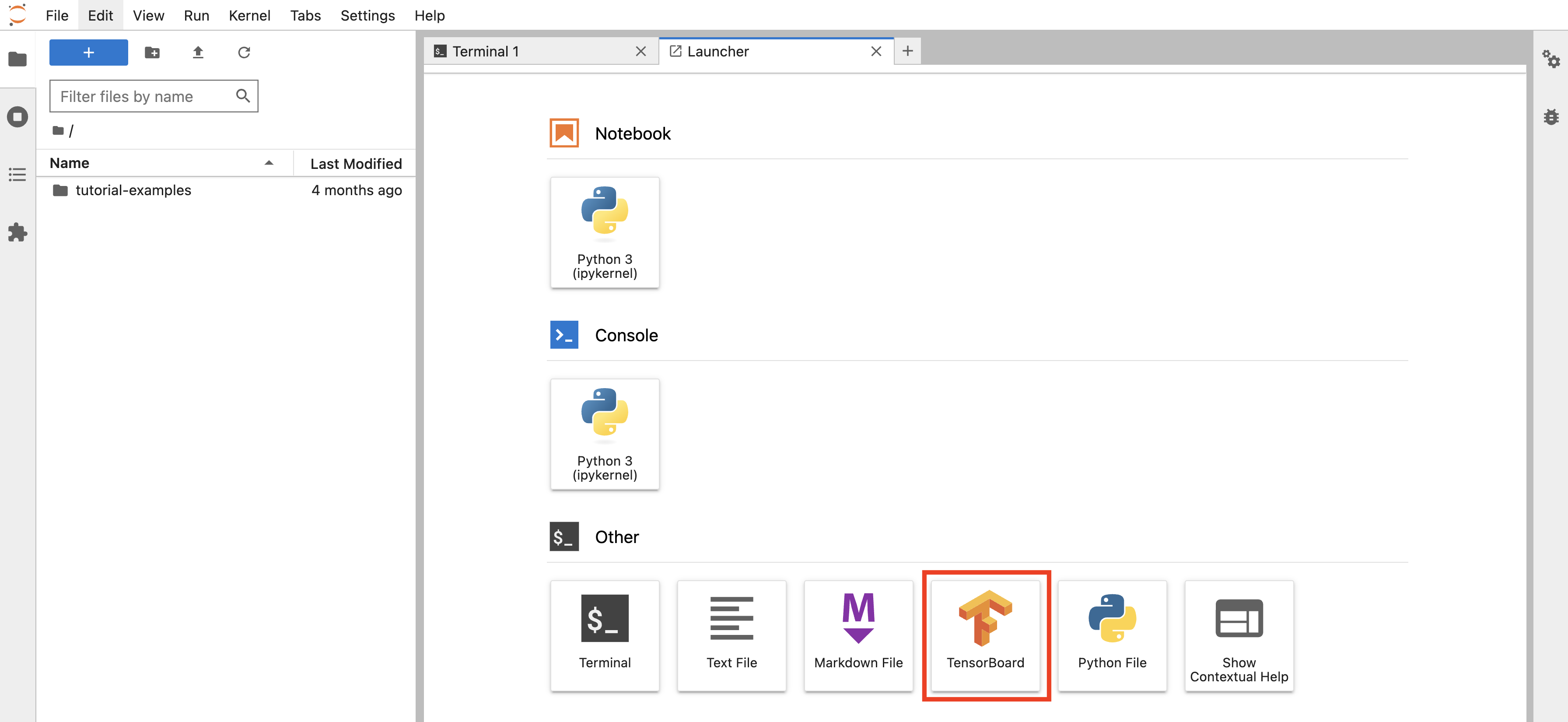
训练产生的 tfevents 文件保存在 PVC 中。回到 JupyterLab,创建一个 TensorBoard 实例。点击 TensorBoard 图标:
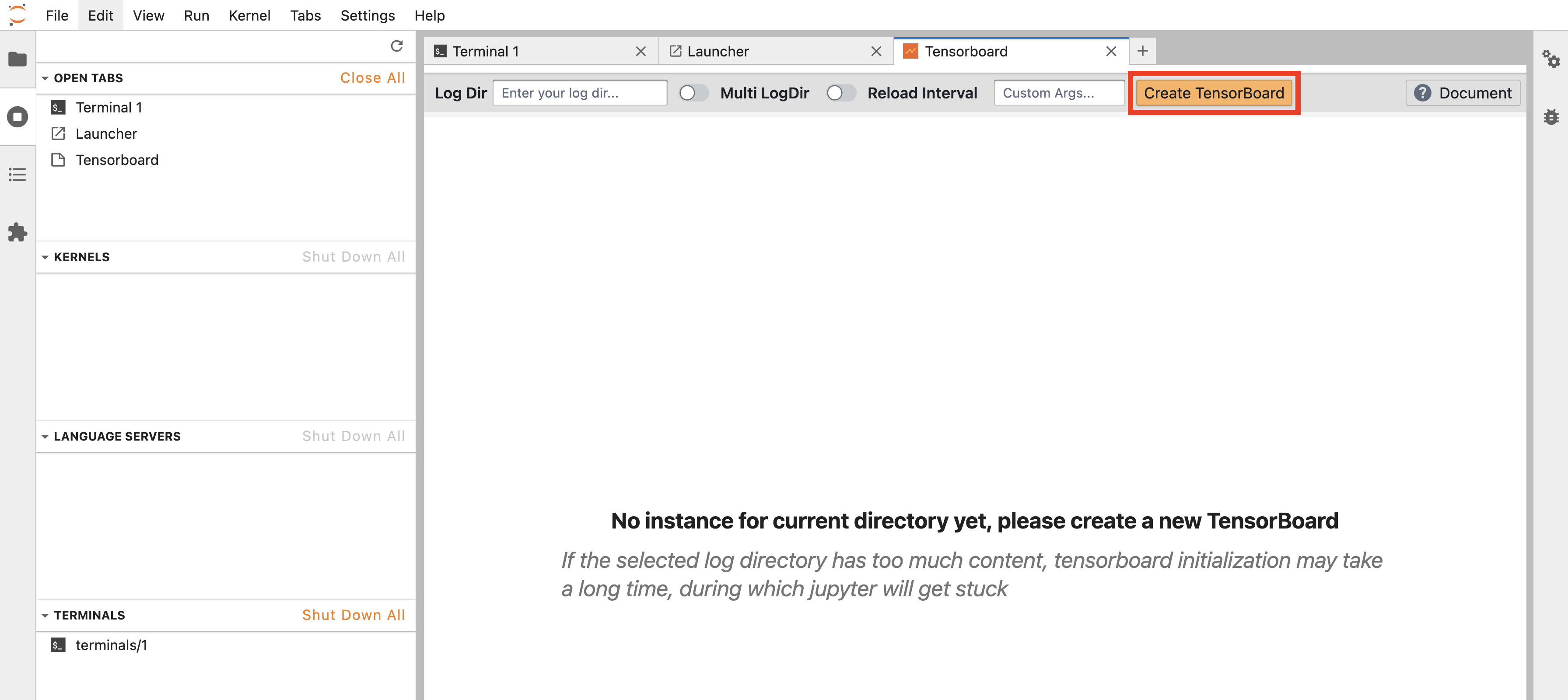
直接点击 Create TensorBoard:
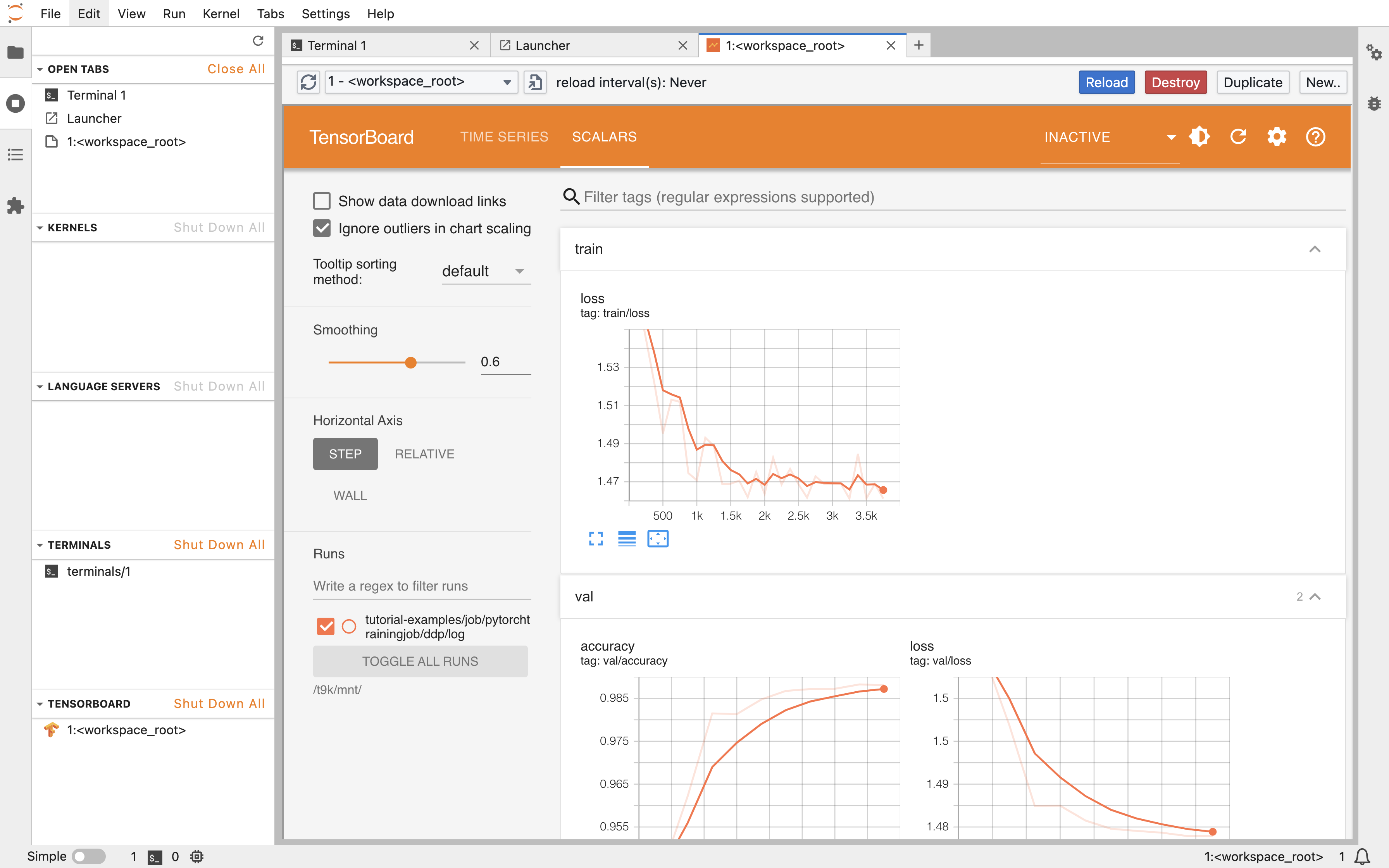
可以查看可视化展示的训练和验证指标:
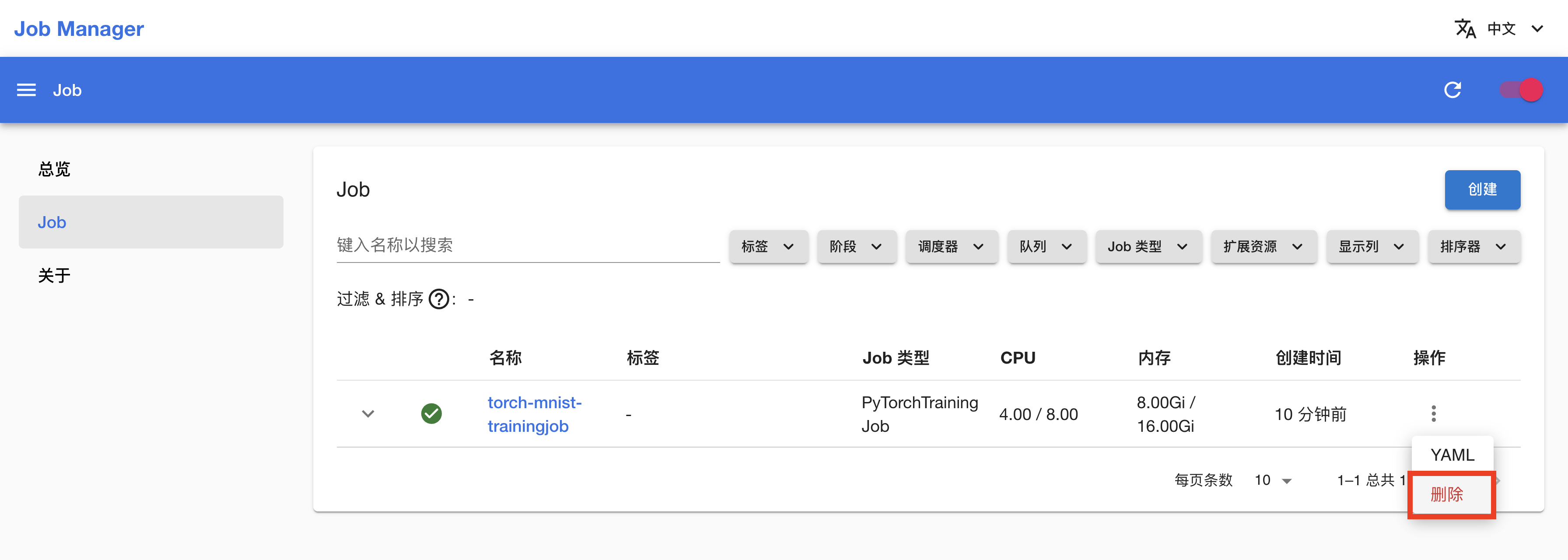
删除 PyTorchTrainingJob
回到 Job 管理页面,点击 PyTorchTrainingJob 右侧的 > 删除,确认以删除 PyTorchTrainingJob: