训练你的第一个模型
本教程带领你使用 Notebook,来构建和训练一个 AI 模型。
创建 Notebook
在 TensorStack AI 平台首页,点击模型构建进入构建控制台(Build Console)。
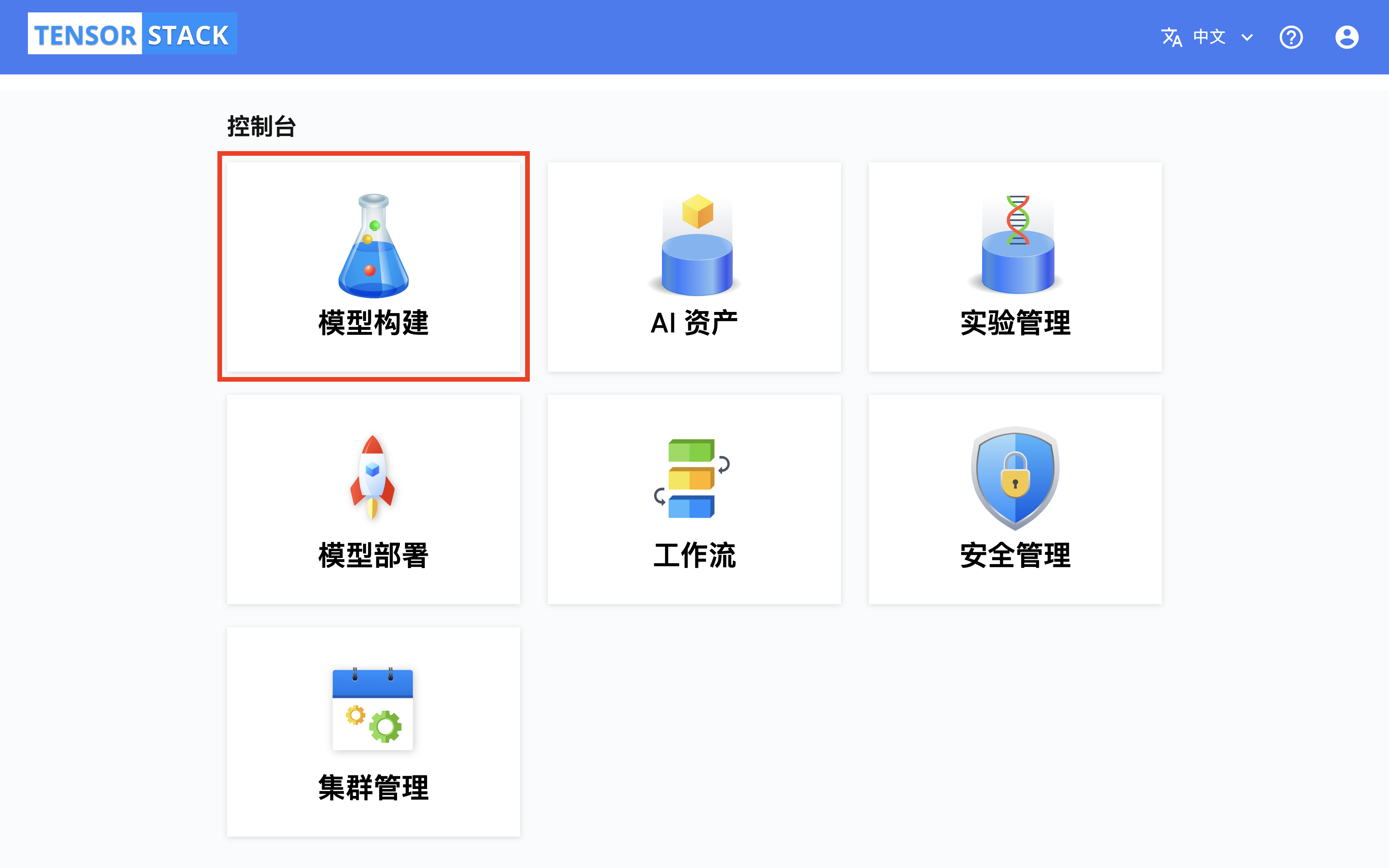
构建控制台(Build Console)的总览页面展示了多种 API 资源,你可以点击右上角的按钮切换 Project,也可以点击事件和配额标签页以查看当前 Project 最近发生的事件以及计算资源(CPU、内存、GPU 等)配额。
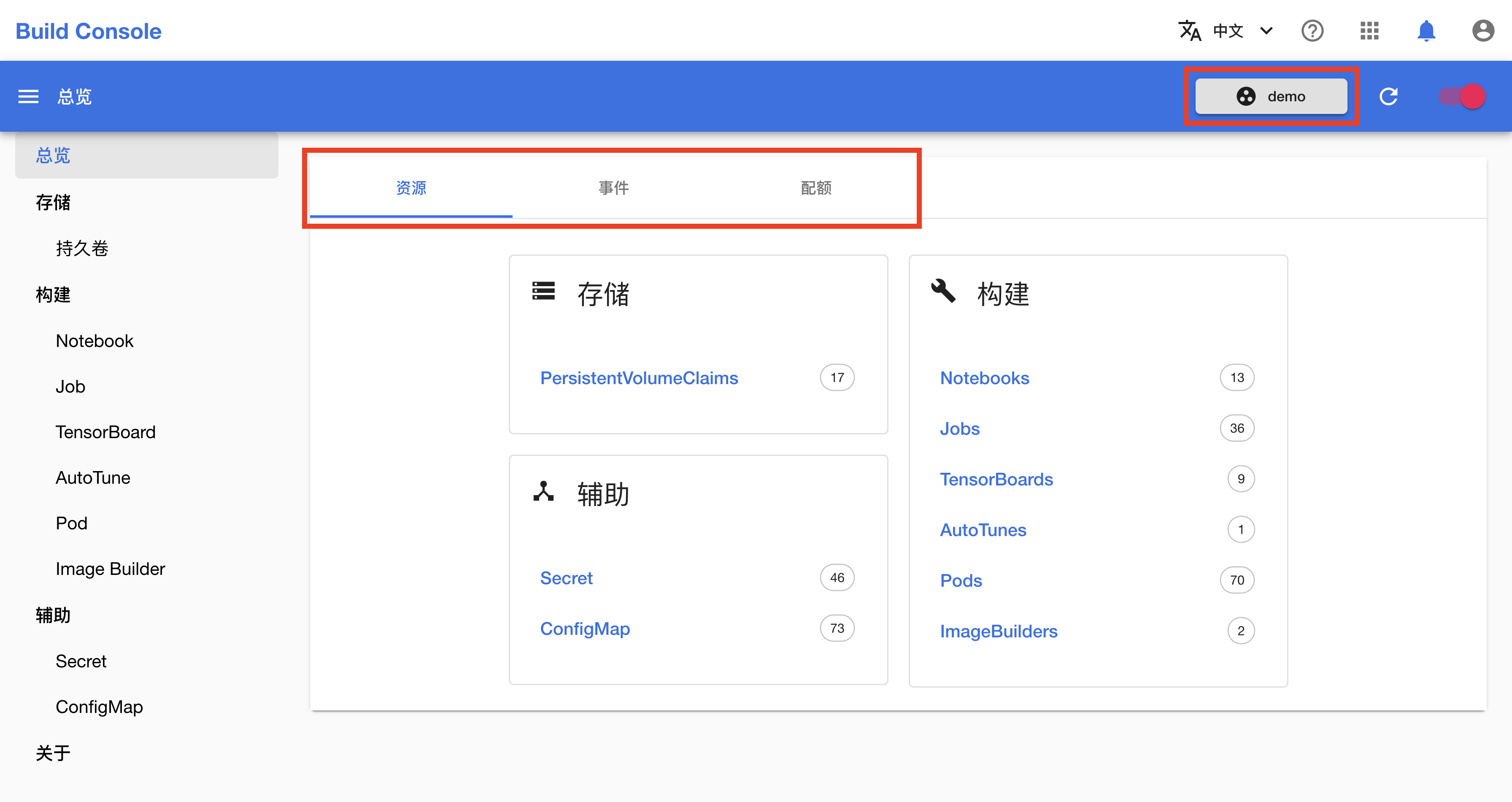
创建 PVC
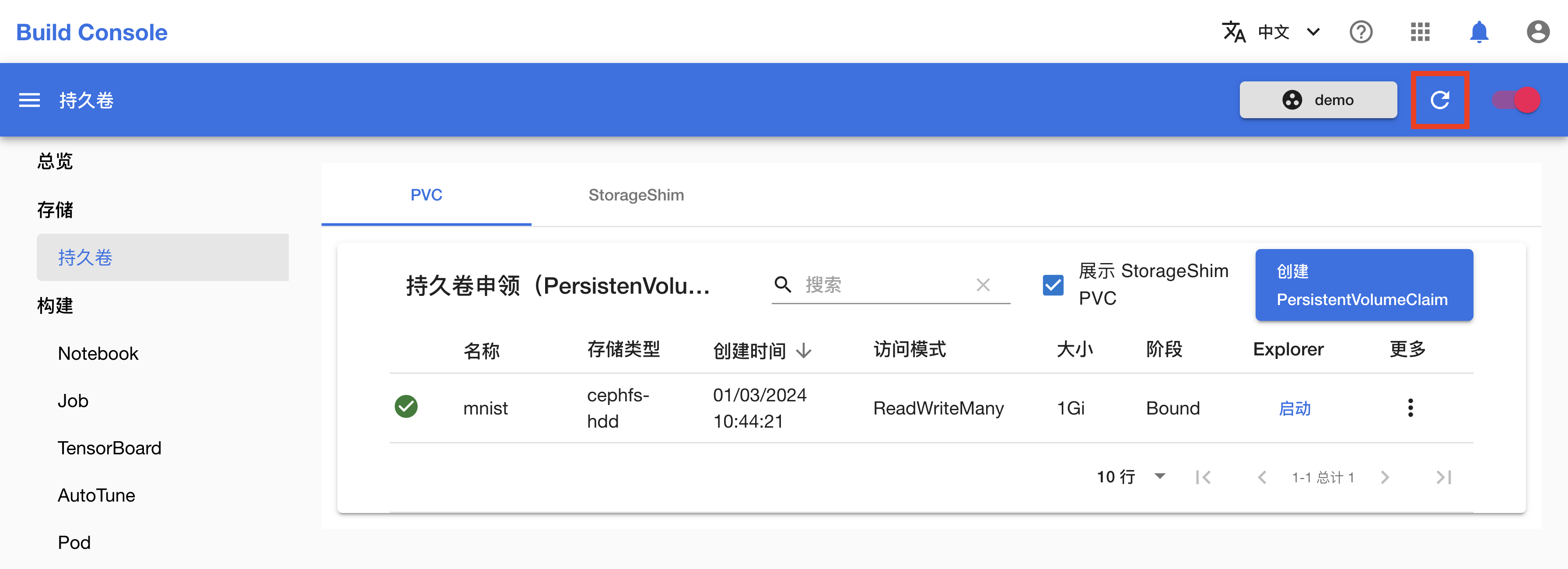
在创建 Notebook 之前,首先需要创建一个用于存储文件的 PVC(持久卷)。在左侧的导航菜单中点击存储 > 持久卷进入 PVC 管理页面,然后点击右上角的创建 PVC。
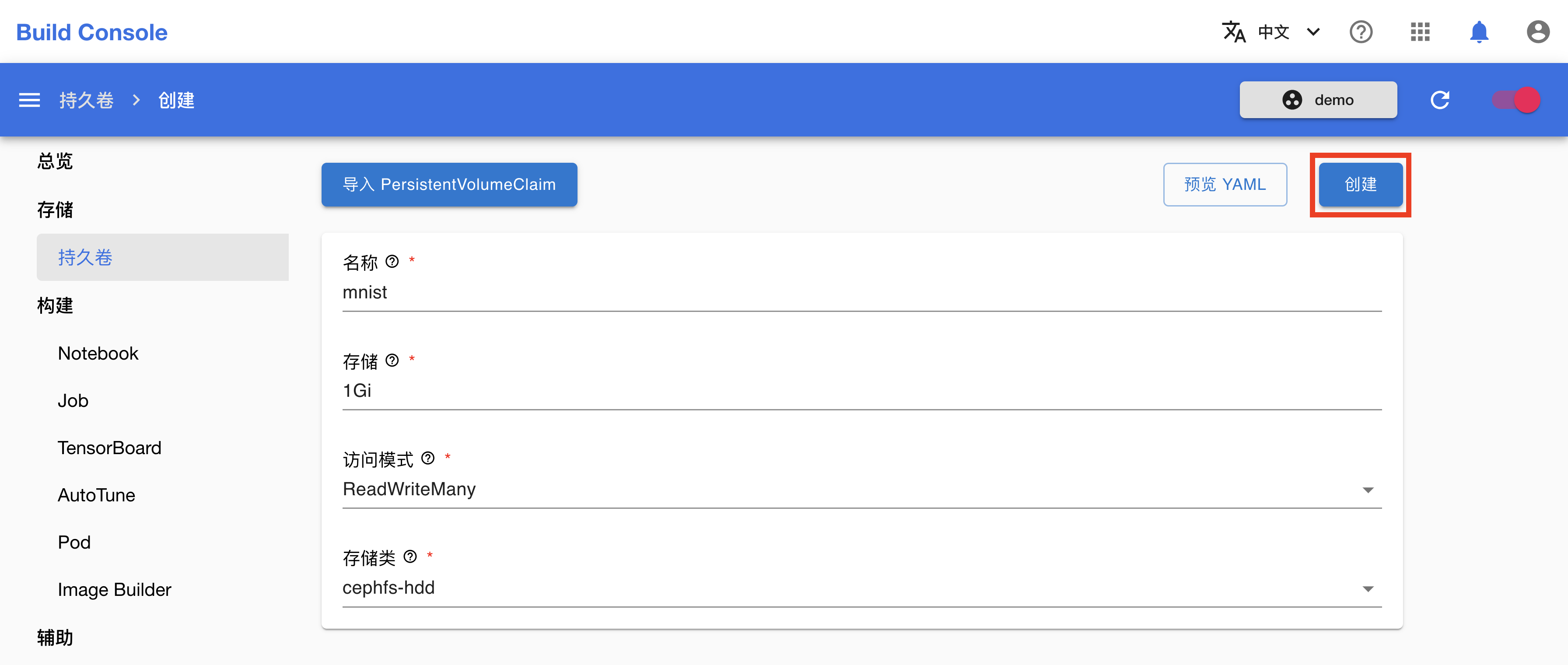
在 PVC 创建页面,如下填写各个参数:
- Name 填写
mnist。 - Size 填写
1Gi。
其他参数保持默认即可。完成之后,点击创建。
在跳转回到 PVC 管理页面之后,可点击右上角的刷新图标来手动刷新 PVC 状态。下图展示 PVC mnist 已经创建完成。
创建 Notebook
在左侧的导航菜单中点击构建 > Notebook 进入 Notebook 管理页面,然后点击右上角的创建 Notebook。
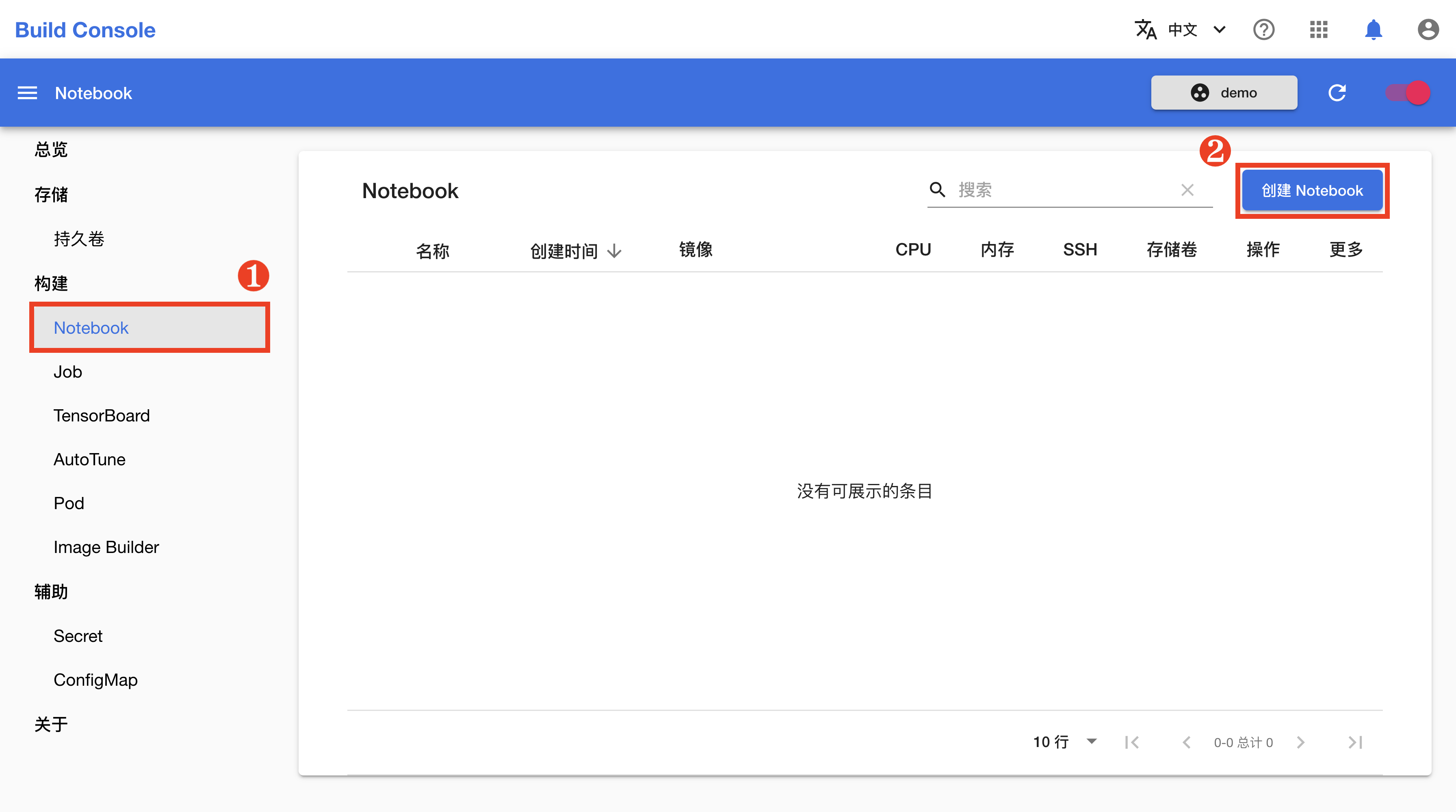
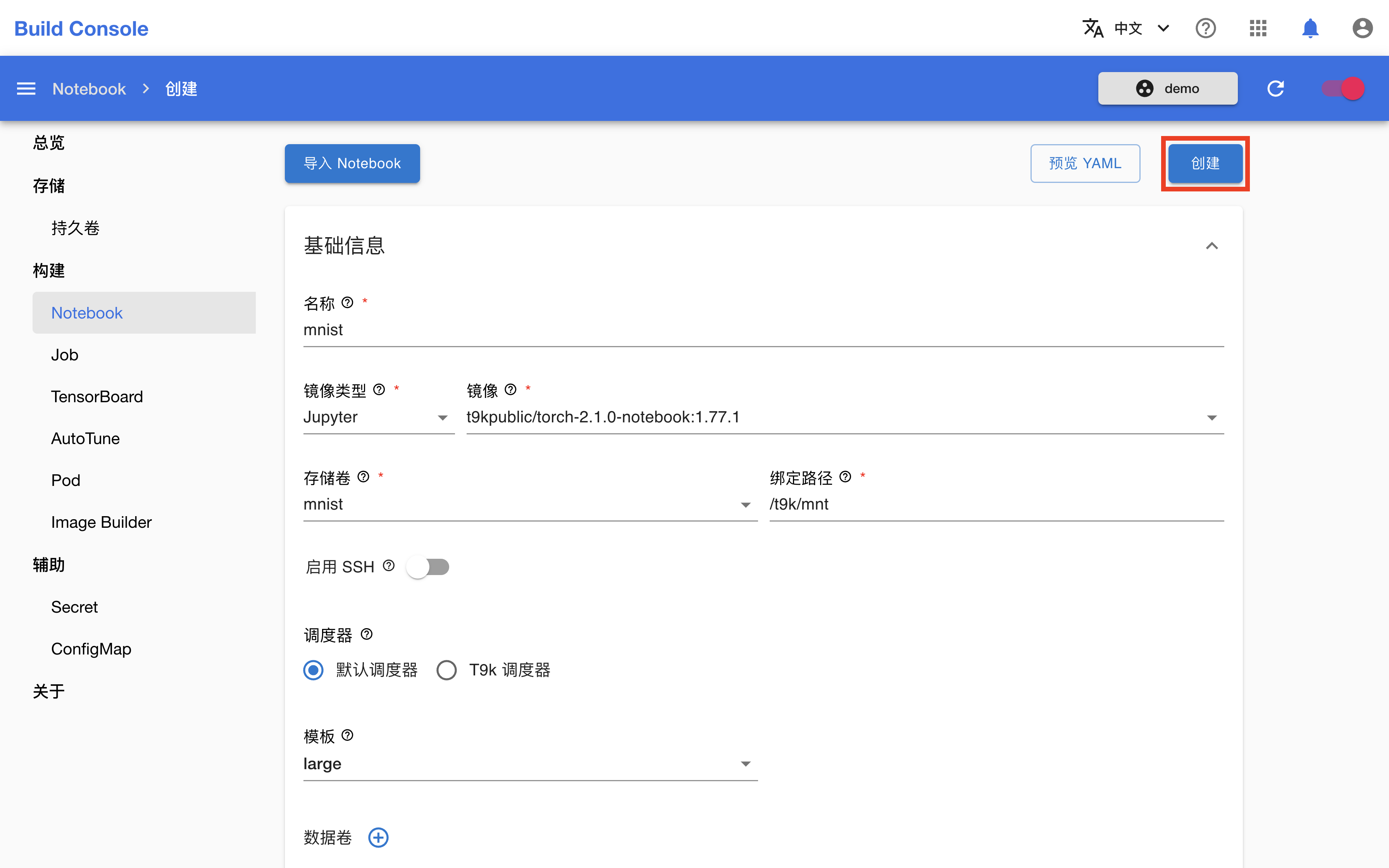
在 Notebook 创建页面,如下填写各个参数:
- 名称填写
mnist。 - 镜像类型选择
Jupyter,镜像选择t9kpublic/torch-2.1.0-notebook:1.77.1。 - 存储卷选择
mnist。 - 调度器选择默认调度器,模板选择 large。
完成之后,点击创建。
在跳转回到 Notebook 管理页面之后,等待刚才创建的 Notebook 准备就绪。第一次拉取镜像可能会花费较长的时间,具体取决于集群的网络状况。点击右上角的刷新图标以手动刷新 Notebook 状态,待 Notebook 开始运行之后,点击右侧的打开进入其前端页面。
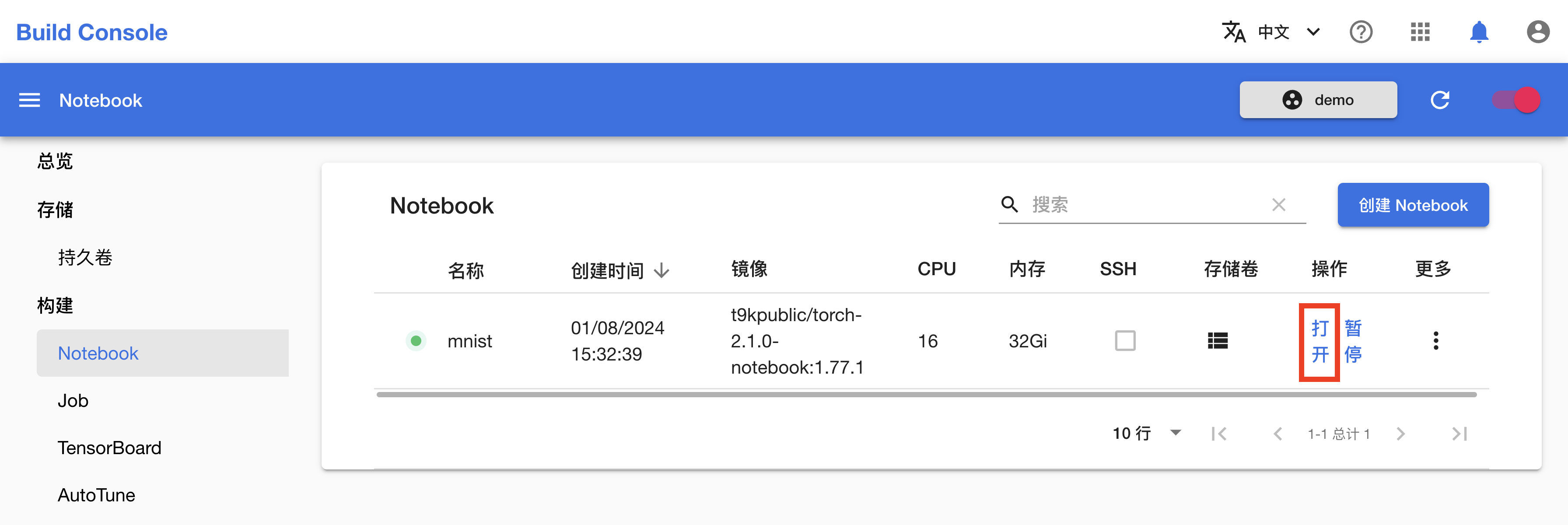
现在 Notebook 已经可以使用了,你可以在这里进行模型的开发与测试。
使用 Notebook 训练模型
在 Notebook 的前端页面,点击左上角的 +,然后点击 Notebook 下的 Python3 以新建一个 .ipynb 文件。
复制下面的训练脚本到该 .ipynb 文件的代码框中。该脚本基于 PyTorch 框架,建立一个简单的卷积神经网络模型,并使用 MNIST 数据集的手写数字图像进行训练和测试。
torch_mnist.py
import os
import shutil
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv3 = nn.Conv2d(64, 64, 3, 1)
self.pool = nn.MaxPool2d(2, 2)
self.dense1 = nn.Linear(576, 64)
self.dense2 = nn.Linear(64, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = torch.flatten(x, 1)
x = F.relu(self.dense1(x))
output = F.softmax(self.dense2(x), dim=1)
return output
def train():
global global_step
for epoch in range(1, epochs + 1):
model.train()
for step, (data, target) in enumerate(train_loader, 1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if step % 500 == 0:
train_loss = loss.item()
print('epoch {:d}/{:d}, batch {:5d}/{:d} with loss: {:.4f}'.
format(epoch, epochs, step, steps_per_epoch, train_loss))
global_step = (epoch - 1) * steps_per_epoch + step
writer.add_scalar('train/loss', train_loss, global_step)
scheduler.step()
global_step = epoch * steps_per_epoch
test(val=True, epoch=epoch)
def test(val=False, epoch=None):
label = 'val' if val else 'test'
model.eval()
running_loss = 0.0
correct = 0
with torch.no_grad():
loader = val_loader if val else test_loader
for data, target in loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
prediction = output.max(1)[1]
correct += (prediction == target).sum().item()
test_loss = running_loss / len(loader)
test_accuracy = correct / len(loader.dataset)
msg = '{:s} loss: {:.4f}, {:s} accuracy: {:.4f}'.format(
label, test_loss, label, test_accuracy)
if val:
msg = 'epoch {:d}/{:d} with '.format(epoch, epochs) + msg
print(msg)
writer.add_scalar('{:s}/loss'.format(label), test_loss, global_step)
writer.add_scalar('{:s}/accuracy'.format(label), test_accuracy,
global_step)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
kwargs = {
'num_workers': 1,
'pin_memory': True
} if torch.cuda.is_available() else {}
torch.manual_seed(1)
model = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.7)
dataset_path = './data'
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))])
train_dataset = datasets.MNIST(root=dataset_path,
train=True,
download=True,
transform=transform)
train_dataset, val_dataset = torch.utils.data.random_split(
train_dataset, [48000, 12000])
test_dataset = datasets.MNIST(root=dataset_path,
train=False,
download=True,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=32,
shuffle=True,
**kwargs)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=400,
shuffle=False,
**kwargs)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=1000,
shuffle=False,
**kwargs)
log_dir = './log'
if os.path.exists(log_dir):
shutil.rmtree(log_dir, ignore_errors=True)
writer = SummaryWriter(log_dir)
global_step = 0
epochs = 10
steps_per_epoch = len(train_loader)
train()
test()
torch.save(model.state_dict(), 'model_state_dict.pt')
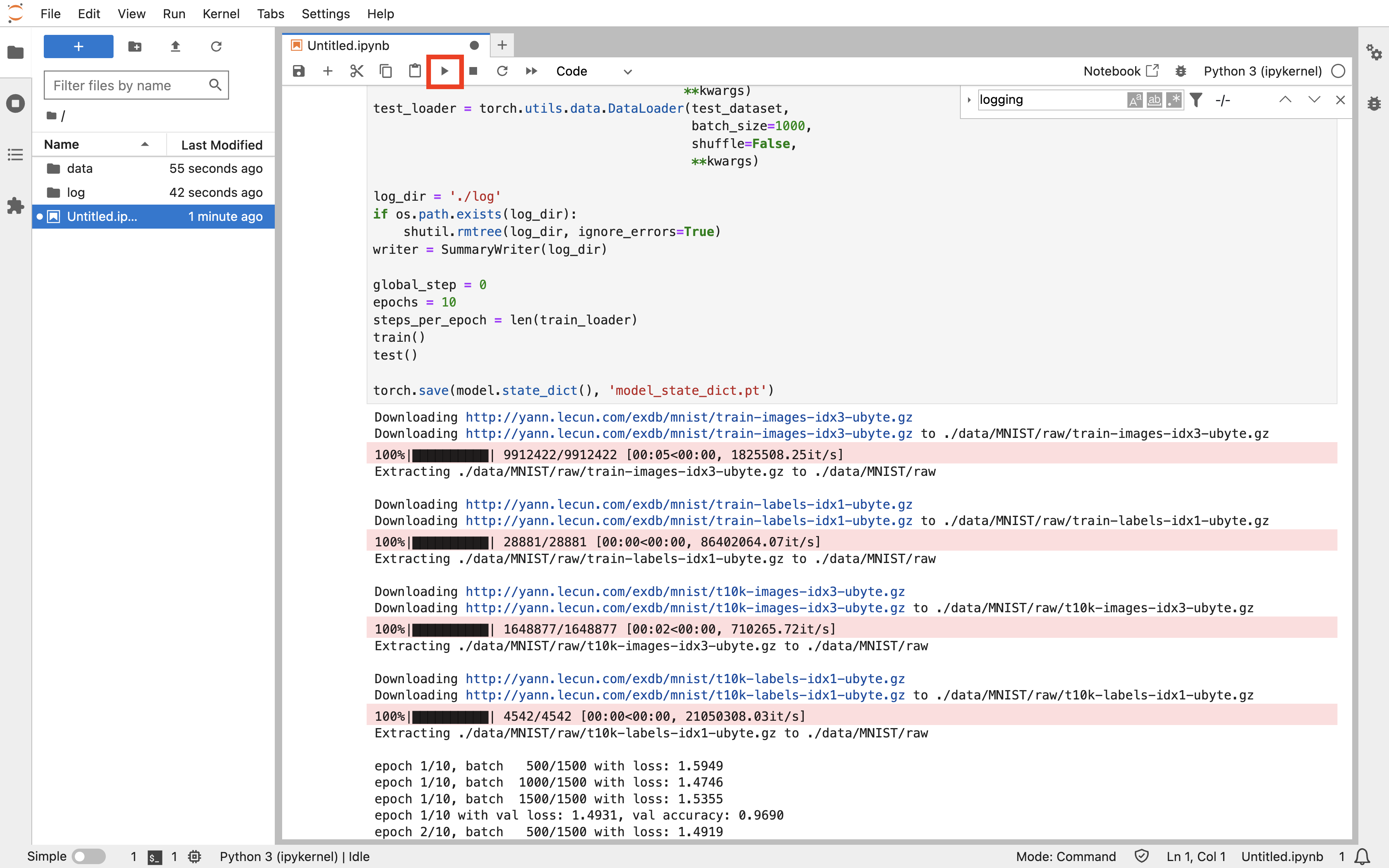
点击上方的运行按钮,可以看到训练开始进行:
训练结束后,点击左上角的新建文件夹按钮,为新文件夹命名 first-model,并将当前教程产生的所有文件拖拽移动到其中。
下一步
- 针对同样的模型,使用 Job 进行并行训练
- 全面了解模型构建