上传和下载文件
通过 PVC 使用集群存储非常方便,它可作为存储卷被挂载到 Notebook、Job、MLService 等各种工作负载的 Pod 中。例如在进行模型训练时,你可以把训练脚本以及训练数据存放到 PVC,然后挂载在 Job 的 Pod 中。
本教程将分场景介绍从集群外部下载/上传文件到 PVC,以及从 PVC 上传/下载文件到集群外部的若干方法。
由于下面的部分方法需要使用到命令行工具,而 Notebook 提供了终端并且 Notebook 的镜像中预装了这些命令行工具,因此我们推荐把 PVC 挂载到一个 Notebook 上,然后在 Notebook 中进行操作。
本地文件系统
Notebook
把 PVC 挂载到 Notebook 上,本地文件系统和 PVC 之间的文件传输,可以直接在 Notebook 的前端页面上操作:
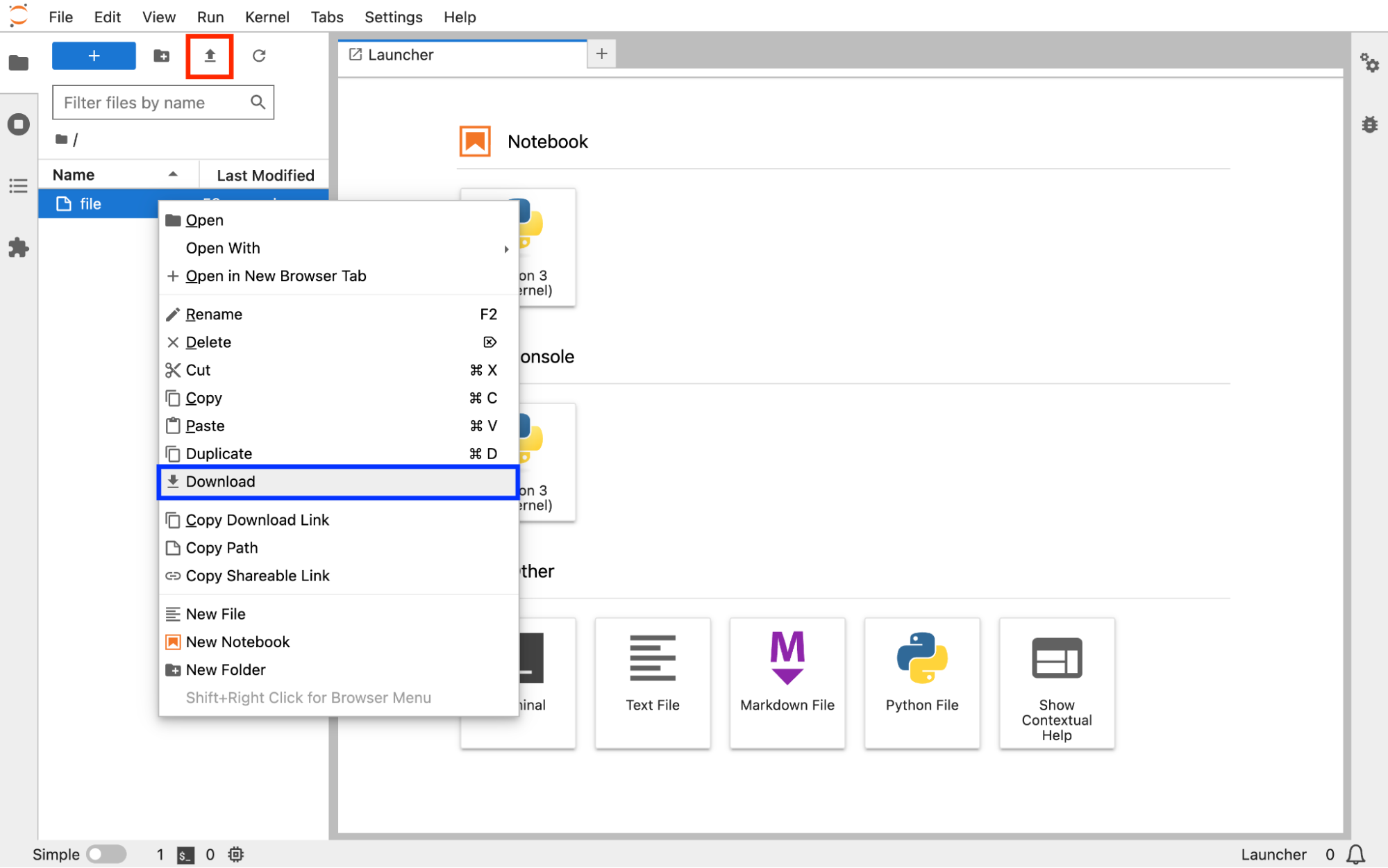
File Browser
在 PVC 上启动 Explorer 之后,则可以通过 File Browser :
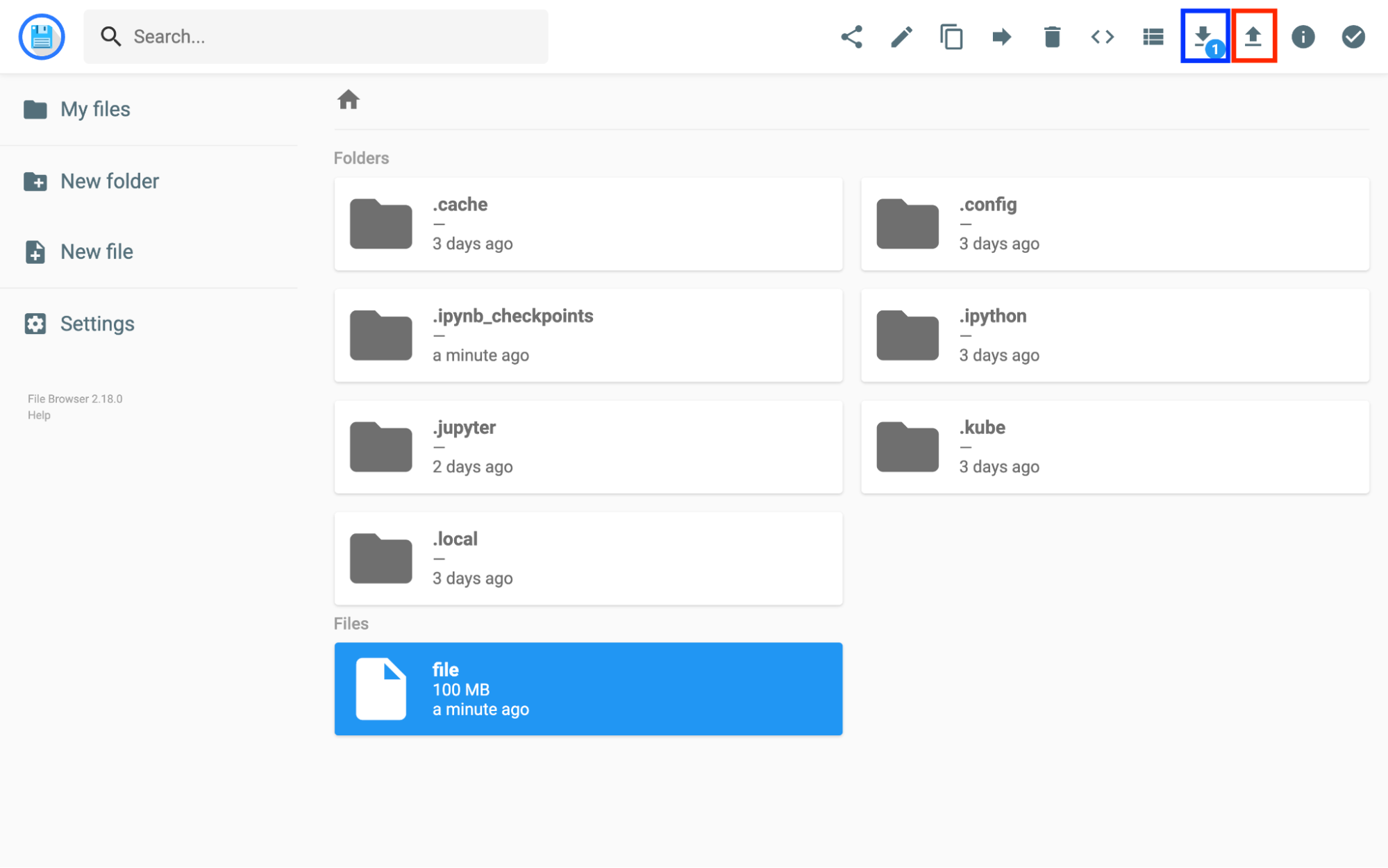
云存储中转
也可以通过其他云存储服务进行中转,即本地 -> 云存储 -> 集群 PVC:
- 本地与云存储之间的文件传输方法请参阅相应云存储的文档;
- 云存储与 PVC 之间的文件传输方法请参阅云存储服务。
云存储服务
rclone 命令
要在云存储与 PVC 之间复制或同步文件,可以在 Notebook 的终端中使用命令行工具 rclone。这里以 Amazon S3 为例,首先参照 Amazon S3 Config 进行配置,完成后执行以下命令:
rclone copy <REMOTE>:<BUCKET>/path/to/the/file . # 从 S3 存储下载
rclone copy ./file <REMOTE>:<BUCKET>/path/to/the/ # 上传到 S3 存储
rclone sync <REMOTE>:<BUCKET>/path/to/the/dir . # 从 S3 存储同步
rclone sync . <REMOTE>:<BUCKET>/path/to/the/dir # 同步到 S3 存储
对于 Amazon S3,除了 rclone 之外还有其他命令行工具可供使用,例如 s3cmd、s5cmd 等。
DataCube
对于 Amazon S3 也可以使用平台提供的 DataCube。使用以下 YAML 配置文件创建 DataCube(修改 PVC 名称、PVC 路径、Secret 名称和 S3 URL)以下载和上传文件:
download-s3.yaml
apiVersion: tensorstack.dev/v1beta1
kind: DataCube
metadata:
name: download-s3
spec:
source:
type: s3
options:
- name: s3-endpoint
valueFrom:
secretKeyRef:
name: <S3ENV_SECRET_NAME> # s3-env 类型的 Secret
key: endpoint
- name: s3-access-key-id
valueFrom:
secretKeyRef:
name: <S3ENV_SECRET_NAME>
key: accessKeyID
- name: s3-secret-access-key
valueFrom:
secretKeyRef:
name: <S3ENV_SECRET_NAME>
key: secretAccessKey
- name: s3-uri
value: s3://<BUCKET>/path/to/the/dir # 下载目录下的所有子目录和文件
# value: s3://<BUCKET>/path/to/the/file # 下载文件
sink:
type: pvc
pvc:
name: <PVC_NAME>
subPath: save/path
# executor:
# options:
# sync: true # 完全同步,会删除多余的文件
upload-s3.yaml
apiVersion: tensorstack.dev/v1beta1
kind: DataCube
metadata:
name: upload-s3
spec:
source:
type: pvc
pvc:
name: <PVC_NAME>
subPath: path/to/the/dir # 上传目录下的所有子目录和文件
# subPath: path/to/the/file # 上传文件
sink:
type: s3
options:
- name: s3-endpoint
valueFrom:
secretKeyRef:
name: <S3ENV_SECRET_NAME> # s3-env 类型的 Secret
key: endpoint
- name: s3-access-key-id
valueFrom:
secretKeyRef:
name: <S3ENV_SECRET_NAME>
key: accessKeyID
- name: s3-secret-access-key
valueFrom:
secretKeyRef:
name: <S3ENV_SECRET_NAME>
key: secretAccessKey
- name: s3-uri
value: s3://<BUCKET>/save/path # 目标 S3 路径
kubectl create -f download-s3.yaml
kubectl create -f upload-s3.yaml
HTTP/FTP 服务
要通过 HTTP(S)、(S)FTP 等协议从网络下载文件到 PVC,可以在 Notebook 的终端中使用 wget(或 curl)命令进行下载:
wget <URL>
# 或
curl -O <URL>
Git 仓库
git 命令
可以在 Notebook 的终端中使用 git 命令,从 GitHub 等代码托管平台克隆或拉取 Git 仓库,并在提交修改后推送回去:
git clone <REPO_URL>
git pull
git fetch
git push
DataCube
也可以使用平台提供的 DataCube。使用以下 YAML 配置文件创建 DataCube(修改 PVC 名称、PVC 路径、Secret 名称和 S3 URL)以克隆(或拉取)和推送提交到 Git 仓库:
download-git.yaml
apiVersion: tensorstack.dev/v1beta1
kind: DataCube
metadata:
name: download-git
spec:
source:
type: git
options:
# - name: token # 个人访问令牌
# valueFrom:
# secretKeyRef:
# name: <CUSTOM_SECRET_NAME> # custom 类型的 Secret
# key: token # 引用键 token 的值
- name: url
value: <GIT_REPO_URL> # 克隆(或拉取)的 Git 仓库
# value: https://$(TOKEN)@github.com/<OWNER>/<REPO_NAME>.git # GitHub 仓库
- name: ref
value: <BRANCH_TAG_OR_COMMIT> # 切换到此 ref
sink:
type: pvc
pvc:
name: <PVC_NAME>
subPath: save/path
upload-git.yaml
apiVersion: tensorstack.dev/v1beta1
kind: DataCube
metadata:
name: upload-git
spec:
source:
type: pvc
pvc:
name: <PVC_NAME>
subPath: path/to/the/parent/dir # 若目标 Git 仓库为 https://github.com/owner/repo.git,
sink: # 则推送的本地 Git 仓库为 path/to/the/parent/dir/repo
type: git
options:
- name: token # 个人访问令牌
valueFrom:
secretKeyRef:
name: <CUSTOM_SECRET_NAME> # custom 类型的 Secret
key: token # 引用键 token 的值
- name: url
value: <GIT_REPO_URL> # 目标 Git 仓库
# value: https://$(TOKEN)@github.com/<OWNER>/<REPO_NAME>.git # GitHub 仓库
kubectl create -f download-git.yaml
kubectl create -f upload-git.yaml
Hugging Face
Hugging Face 是一个 AI 开源社区,其提供的 Git 仓库托管了大量流行的开源模型和数据集。
这里介绍从 Hugging Face 下载模型文件到 PVC(以模型 facebook/opt-125m 为例),以及从 PVC 上传模型文件到 Hugging Face(以用户自己创建的模型 user/llm 为例)的若干方法。数据集类似。
git 命令
Hugging Face 模型或数据集本身就是一个 Git 仓库,因此可以参照 Git 仓库的方法。需要注意的是:
-
Git 仓库的 HTTPS URL 为
https://huggingface.co/<OWNER>/<MODEL_OR_DATASET_NAME>,例如模型facebook/opt-125m的 HTTPS URL 为https://huggingface.co/facebook/opt-125m。 -
Git LFS 被用于管理大于 10MB 的文件(Notebook 的镜像已经安装了 Git LFS,并在启动时进行了初始化)。如要推送大于 10MB 的文件,请先通过 Git LFS 追踪该文件:
git lfs track large_file git add large_file git commit -m "Add the large file" git push -
如要访问受保护的模型或数据集(例如模型
meta-llama/Meta-Llama-3-8B),访问私有模型或数据集,或推送提交到模型或数据集,则需要提供拥有相应权限的用户的用户名和 token:# 克隆受保护的模型的 Git 仓库 git clone https://<HF_USERNAME>:<HF_TOKEN>@huggingface.co/meta-llama/Meta-Llama-3-8B # 克隆私有模型的 Git 仓库 git clone https://<HF_USERNAME>:<HF_TOKEN>@huggingface.co/user/private-llm # 克隆模型的 Git 仓库并在提交修改后推送回去 git clone https://<HF_USERNAME>:<HF_TOKEN>@huggingface.co/user/llm git add ... git commit ... git push
transformers 库和 datasets 库
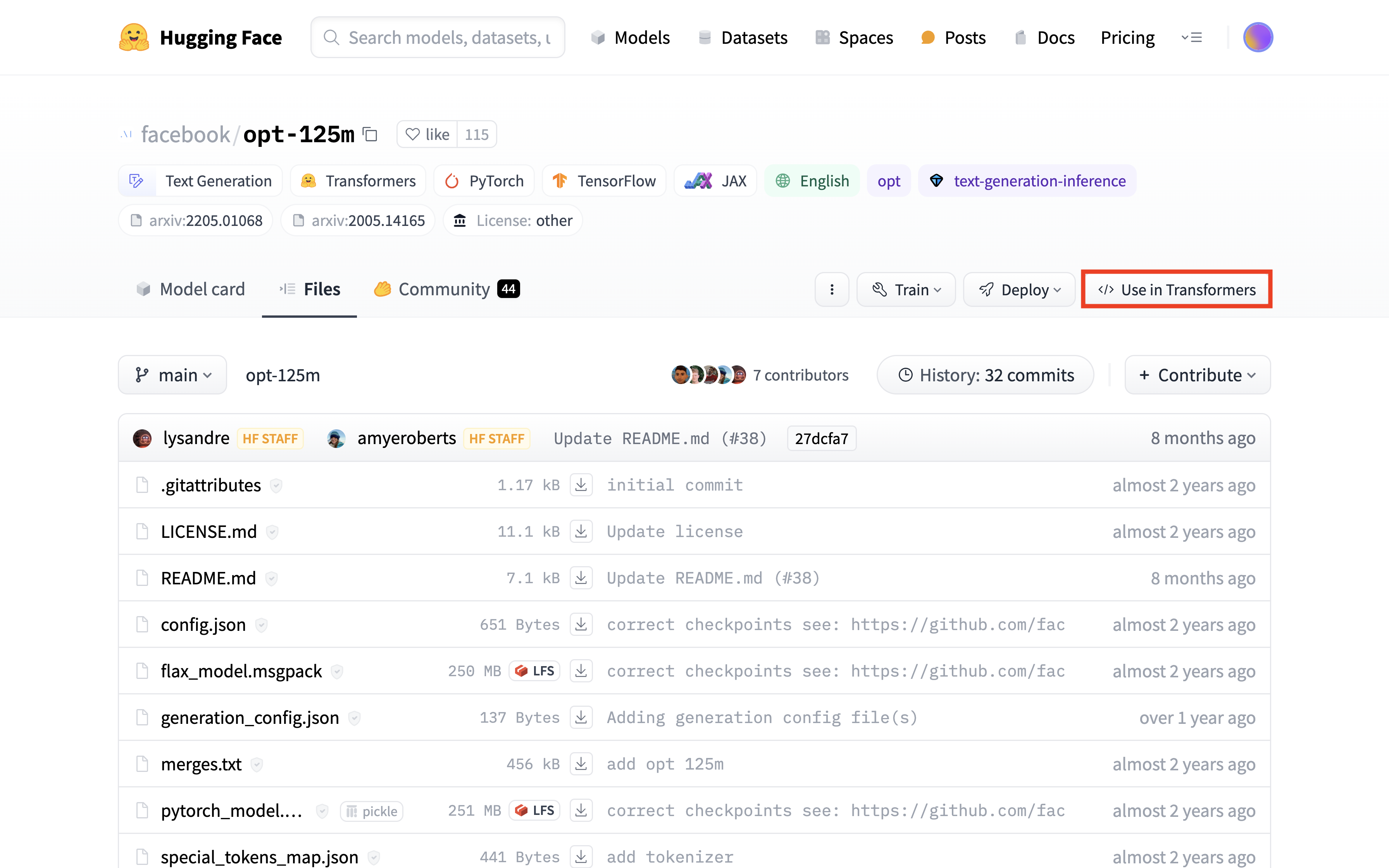
可以使用 transformers 库下载和上传模型文件以及 tokenizer 文件。使用浏览器访问模型 facebook/opt-125m 的 Files 标签页。点击 Use in Transformers,按照提示进行操作,即在 Python 程序中调用 transformers 库加载模型。首次加载时,仓库中的模型文件和 tokenizer 文件会被下载到缓存目录下,即 PVC 的 .cache/huggingface/hub/models--facebook--opt-125m/ 路径下。
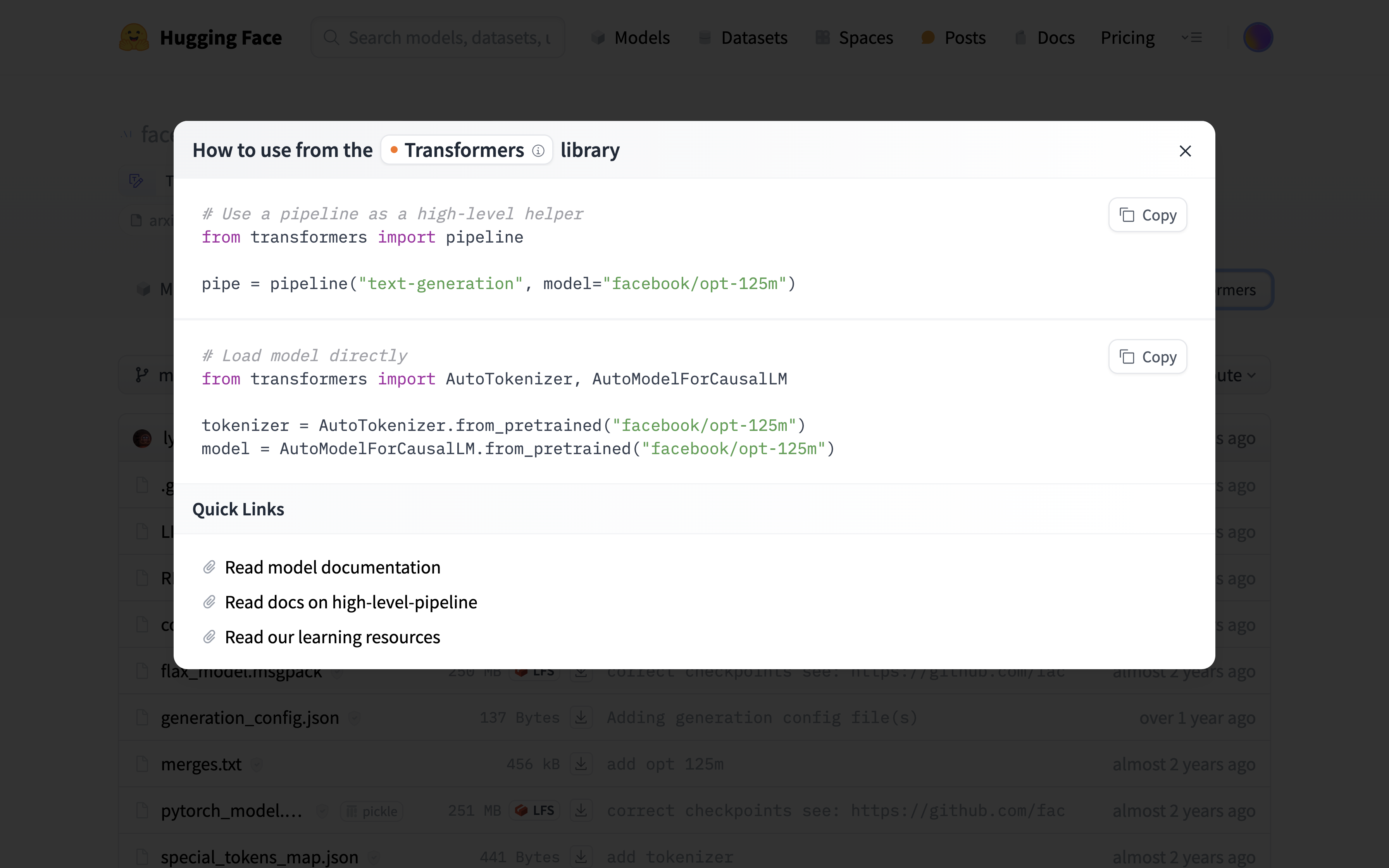
from transformers import pipeline
pipe = pipeline("text-generation", model="facebook/opt-125m")
# 或
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-125m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
对于受保护的或私有的模型或数据集(例如模型 meta-llama/Meta-Llama-3-8B),需要提供拥有访问权限的用户的 token:
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Meta-Llama-3-8B", token="<HF_TOKEN>")
# 或
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B", token="<HF_TOKEN>")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B", token="<HF_TOKEN>")
使用 datasets 库下载和上传数据集文件。相比加载模型,加载数据集要更加复杂一些,请直接参阅教程
Load a dataset 和 Load。
调用模型对象、tokenizer 对象或数据集对象的 push_to_hub() 方法以将其文件上传到仓库:
huggingface-cli login --token <HF_TOKEN> # 登录到 Hugging Face
...
model.push_to_hub("user/llm")
tokenizer.push_to_hub("user/llm")
dataset.push_to_hub("user/data")
huggingface-cli 命令和 huggingface_hub 库
可以使用 huggingface-cli download 命令下载仓库中的所有文件或指定文件。文件会被下载到与 transformers 库相同的缓存目录下。
huggingface-cli download facebook/opt-125m # 下载所有文件
huggingface-cli download facebook/opt-125m pytorch_model.bin # 下载单个指定文件
huggingface-cli download facebook/opt-125m pytorch_model.bin generation_config.json # 下载多个指定文件
huggingface-cli download facebook/opt-125m --include="*.bin" # 模式匹配
huggingface-cli download facebook/opt-125m --cache-dir . # 指定缓存目录
huggingface-cli download cais/mmlu all/test-00000-of-00001.parquet --repo-type=dataset # 下载数据集文件
对于受保护的或私有的模型或数据集(例如模型 meta-llama/Meta-Llama-3-8B),需要提供拥有访问权限的用户的 token:
huggingface-cli login --token <HF_TOKEN> # 登录到 Hugging Face
huggingface-cli download meta-llama/Meta-Llama-3-8B
# 或
huggingface-cli download meta-llama/Meta-Llama-3-8B --token <HF_TOKEN>
使用 huggingface-cli upload 命令上传文件或整个目录到仓库:
# Usage: huggingface-cli upload <REPO_ID> <LOCAL_PATH> [REPO_PATH]
huggingface-cli login --token <HF_TOKEN> # 登录到 Hugging Face
huggingface-cli upload user/llm . . # 上传整个目录
huggingface-cli upload user/llm ./pytorch_model.bin # 上传单个指定文件
huggingface-cli upload user/llm . . --exclude="/logs/*" # 模式匹配
huggingface-cli upload user/data . . --repo-type=dataset # 上传数据集文件
# 或
huggingface-cli upload user/llm . . --token <HF_TOKEN>
实际上,huggingface-cli 是 huggingface_hub 库的命令行工具。huggingface-cli download 命令在内部调用了该库的 hf_hub_download() 和 snapshot_download() 函数,huggingface-cli upload 命令在内部调用了该库的 upload_file() 和 upload_folder() 函数。我们同样可以在 Python 程序中调用该库的这些函数来下载和上传文件,这里不再展开,请直接参阅教程 Download files 和 Upload files。
wget 命令
如果只需要下载个别文件,那么也可以复制相应文件的下载链接,然后在终端中使用 wget(或 curl)命令下载:
wget https://huggingface.co/facebook/opt-125m/resolve/main/pytorch_model.bin?download=true -O pytorch_model.bin
# 或
curl -L https://huggingface.co/facebook/opt-125m/resolve/main/pytorch_model.bin?download=true -o pytorch_model.bin
对于受保护的或私有的模型或数据集(例如模型 meta-llama/Meta-Llama-3-8B),需要提供拥有访问权限的用户的 token:
wget --header="Authorization: Bearer <HF_TOKEN>" https://huggingface.co/meta-llama/Meta-Llama-3-8B/resolve/main/model-00001-of-00004.safetensors?download=true -O model-00001-of-00004.safetensors
# 或
curl --header "Authorization: Bearer <HF_TOKEN>" -L https://huggingface.co/meta-llama/Meta-Llama-3-8B/resolve/main/model-00001-of-00004.safetensors?download=true -o model-00001-of-00004.safetensors
DataCube
也可以使用平台提供的 DataCube,其在内部调用的就是 huggingface-cli 命令。使用以下 YAML 配置文件创建 DataCube(修改 PVC 名称、PVC 路径、Secret 名称和 S3 URL)以下载和上传文件:
download-hf.yaml
apiVersion: tensorstack.dev/v1beta1
kind: DataCube
metadata:
name: download-hf
spec:
source:
type: huggingface
options:
# - name: token # Hugging Face token
# valueFrom:
# secretKeyRef:
# name: <CUSTOM_SECRET_NAME> # custom 类型的 Secret
# key: token # 引用键 token 的值
- name: repo
value: <OWNER>/<MODEL_OR_DATASET_NAME> # 下载的 Hugging Face 仓库 ID
# - name: files
# value: <FILE1>, <FILE2>, ... # 下载的文件列表,默认为所有文件
sink:
type: pvc
pvc:
name: <PVC_NAME>
subPath: save/path
# executor:
# env:
# - name: HTTPS_PROXY
# value: <host>:<port> # HTTPS 代理
upload-hf.yaml
apiVersion: tensorstack.dev/v1beta1
kind: DataCube
metadata:
name: upload-hf
spec:
source:
type: pvc
pvc:
name: <PVC_NAME>
subPath: path/to/the/dir # 上传目录下的所有子目录和文件
# subPath: path/to/the/file # 上传文件
sink:
type: huggingface
options:
- name: token # Hugging Face token
valueFrom:
secretKeyRef:
name: <CUSTOM_SECRET_NAME> # custom 类型的 Secret
key: token # 引用键 token 的值
- name: repo
value: <OWNER>/<MODEL_OR_DATASET_NAME> # 上传的 Hugging Face 仓库 ID
- name: path-in-repo
value: upload/path # 目标路径
- name: commit-message
value: <COMMIT_MESSAGE> # 提交消息
# executor:
# env:
# - name: HTTPS_PROXY
# value: <host>:<port> # HTTPS 代理
kubectl create -f download-hf.yaml
kubectl create -f upload-hf.yaml
ModelScope
ModelScope 是一个中文 AI 开源社区,可以视作中国版的 Hugging Face。ModelScope 上托管的模型和数据集相比 Hugging Face 要少得多,但对于国内用户,访问 ModelScope 的网络连通性更好。
这里介绍从 ModelScope 下载模型文件到 PVC(以模型 AI-ModelScope/opt-125 为例),以及从 PVC 上传模型文件到 ModelScope(以用户自己创建的模型 user/llm 为例)的若干方法。数据集类似。
git 命令
与 Hugging Face 类似,除了:
-
Git 仓库的 HTTPS URL 为
https://www.modelscope.cn/<OWNER>/<MODEL_OR_DATASET_NAME>.git,例如模型AI-ModelScope/opt-125的 HTTPS URL 为https://www.modelscope.cn/AI-ModelScope/opt-125.git。 -
Git LFS 被用于管理大于 100MB 的文件(Notebook 的镜像已经安装了 Git LFS,并在启动时进行了初始化)。如要推送大于 100MB 的文件,请先通过 Git LFS 追踪该文件:
git lfs track large_file git add large_file git commit -m "Add the large file" git push -
如要访问受保护的模型或数据集,访问私有模型或数据集,或推送提交到模型或数据集,则需要提供拥有相应权限的用户的 token:
# 克隆私有模型的 Git 仓库 git clone http://oauth2:<MODELSCOPE_TOKEN>@www.modelscope.cn/user/private-llm.git # 克隆模型的 Git 仓库并在提交修改后推送回去 git clone http://oauth2:<MODELSCOPE_TOKEN>@www.modelscope.cn/user/llm.git git add ... git commit ... git push
modelscope 库
可以使用 modelscope 库下载和上传文件。第一种下载模型文件的方法类似于 transformers 库(在内部也调用了 transformers 库)。首次加载时,仓库中的所有文件会被下载到缓存目录下,即 PVC 的 .cache/modelscope/hub/AI-ModelScope/opt-125/ 路径下。
from modelscope.models import Model
model = Model.from_pretrained("AI-ModelScope/opt-125")
第二种下载模型文件的方法类似于 huggingface_hub 库。文件会被下载到与第一种方法相同的缓存目录下。
from modelscope import snapshot_download
from modelscope.hub.file_download import model_file_download
snapshot_download("AI-ModelScope/opt-125") # 下载所有文件
model_file_download("AI-ModelScope/opt-125", file_path="pytorch_model.bin") # 下载单个指定文件
snapshot_download("AI-ModelScope/opt-125", cache_dir=".") # 指定缓存目录
下载数据集文件的方法类似于 datasets 库。这里以数据集 MMLU 的子集 Abstract Algebra 为例,注意不同的数据集拥有不同的可用子集。首次加载时,仓库中的数据集文件会被下载到缓存目录下,即 PVC 的 .cache/modelscope/hub/datasets/mmlu/abstract_algebra/ 路径下。
from modelscope.msdatasets import MsDataset
dataset = MsDataset.load("mmlu", subset_name="abstract_algebra")
对于受保护的或私有的模型或数据集,需要提供拥有访问权限的用户的 token:
from modelscope import HubApi
api=HubApi()
api.login("<MODELSCOPE_TOKEN>") # 登录到 ModelScope
# 然后参照上面的方法下载
上传模型文件的方法如下所示。modelscope 库暂不支持上传数据集文件。
from modelscope.hub.api import HubApi
api = HubApi()
api.login("<MODELSCOPE_TOKEN>") # 登录到 ModelScope
api.push_model(
model_id="<OWNER>/<MODEL_NAME>",
model_dir="<LOCAL_PATH>" # 本地模型目录,要求目录中必须包含 configuration.json
)
大规模数据
在处理大规模数据(如 100TB 级别)的导入和导出时,根据数据源的不同,我们采用不同的策略以确保数据传输的效率和安全性。以下是针对不同数据源的一些方法:
数据源为云存储时:
- 参照云存储服务操作。
数据源为 HDD/SDD 外置驱动器或类似设备时:
- 将驱动器连接到集群外的与集群网络连接速度较快的计算机上,然后参照本地文件系统继续操作。
- 或者,请求管理员操作,将驱动器连接到存储集群的节点上,直接使用存储系统的工具进行数据传输。这种方法的数据传输速度一般较快,但需要能够访问存储集群的工具和接口。