GPU 使用
许多执行深度学习相关任务的工作负载都需要使用 GPU 进行计算,这些任务包括数据集的预处理、模型训练以及模型推理等等。平台支持目前所有主流的 GPU 设备,并且可以轻松扩展以支持更多设备类型。
使用模式
独占模式
独占模式指的是在特定时间段内,GPU 仅供单一工作负载使用。
适用场景:GPU 被满负荷使用,并且计算需要尽快完成。例如训练 AI 模型。
共享模式
共享模式指的是单个物理 GPU 被多个工作负载同时使用。
适用场景:对于有些计算任务,例如交互式的 Notebook,小规模或者低使用量的模型推理服务,经常只需要使用 GPU 的部分计算能力。在这些情况下,让多个计算任务共享使用 GPU,将能极大地提升 GPU 的利用率。
共享 NVIDIA GPU
下面介绍 NVIDIA 提供的多种 GPU 共享和并发使用的机制,以支持不同的场景。
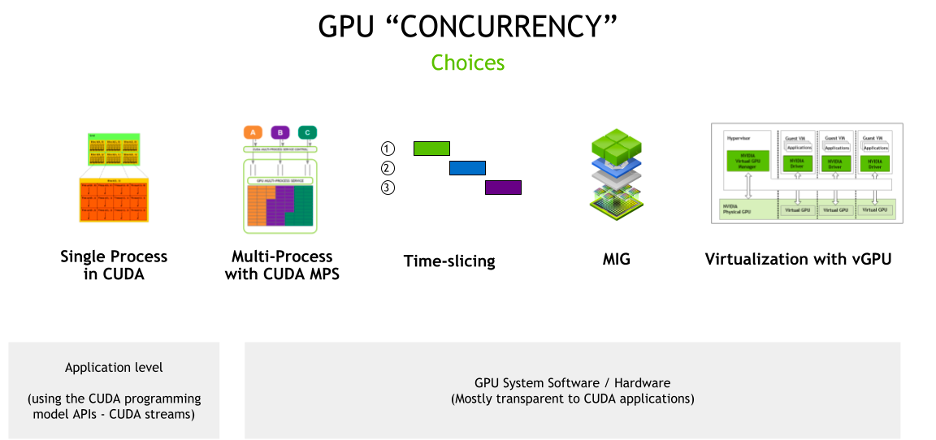
MPS
CUDA MPS(Multi-Process Service,多进程服务)是 CUDA API 的客户端-服务器架构的实现,用于提供同一 GPU 同时给多个进程使用。MPS 是一个 “AI 史前”(深度学习尚未在 GPU 上运行)的方案,是 NVIDIA 为了解决在科学计算领域单个 MPI 进程无法有效利用 GPU 的计算能力而推出的技术。
与时间切片(Time Slicing)相比,MPS 通过在多个客户端之间共享一个 CUDA Context 消除了多个 CUDA 应用之间上下文切换的开销,从而带来更好的计算性能。 此外,MPS 为每个 CUDA 程序提供了单独的内存地址空间,因而可以实现对单个 CUDA 程序实施内存大小使用限制,克服了 Time Slicing 机制在这方面的不足。
优点:
- 可以控制单个应用的内存大小使用限制。
- 由于消除了多个 CUDA 应用之间 context swtich 的代价,具有更好的性能。
- 是一个 CUDA 层面的方案,不依赖于 GPU 的特定架构,支持较早的 GPU 硬件。
缺点:
- CUDA 应用之间隔离不足:单个应用的错误可以导致整个 GPU 重置(reset)。
- NVIDIA 还未(截止2024/01)正式在 K8s 环境下提供支持。
Time Slicing
时间切片(Time Slicing),也称为时间共享(Temporal Sharing),是指将多个 CUDA 程序分配到同一个 GPU 上运行,即一个简单的超额订阅(oversubscription)策略。NVIDIA 在 Pascal 架构(GP100,2016 年首发)之上提供了对此技术的支持。这些 GPU 卡上的调度器提供了指令粒度(不再需要等待 CUDA kernel 执行完成)的计算抢占(Compute Premption)技术。当抢占发生时, 当前 CUDA 程序的执行上下文(execution context:寄存器、共享内存等)被交换(swapped)到 GPU DRAM,以便另一个 CUDA 程序运行。
优点:
- 非常容易设置。
- 对分区数量无限制。
- 可在众多 GPU 架构上部署。
缺点:
- 上下文切换引起的效率降低。
- 共享 GPU 设备导致的的隔离不足、潜在的 GPU OOM 等。
- 时间片周期恒定,且无法为每个工作负载设置可用资源的优先级或大小。
MIG
MIG 可以把一个 GPU 划分为最多 7 个独立的 GPU 实例,从而为多个 CUDA 程序提供专用的 GPU 资源,包括流式多处理器(Streaming Multiprocessors)和 GPU 引擎。这些 MIG 实例可以为不同的 GPU 客户端(例如进程、容器或 VM)提供更加高级的故障隔离能力和 QoS。
优点:
- 硬件隔离,并发进程安全运行且互不影响。
- 在分区级别提供监控和遥测(monitoring & telemetry)数据。
- 每个分区可以叠加使用其他共享技术,例如 vGPU、time-slicing、MPS。
缺点:
- 仅在最新的 GPU 架构(Ampere,Hopper)上提供。
- 重新配置分区布局需在 GPU 空闲(驱逐所有正在运行的进程)时。
- 一些分区配置会导致部分 SM / DRAM 无法被利用。
vGPU
NVIDIA vGPU 是 NVIDIA 在数据中心提供的 GPU 虚拟化技术,它对具有完整输入输出内存管理单元(IOMMU)保护的 VM 提供支持,使得这些 VM 能够同时、直接地访问单个物理 GPU。
除了安全性之外,NVIDIA vGPU 还有其他优势,例如:
- 支持实时虚拟机迁移(live VM migration)。
- 可设置不同的调度策略,包括 best-effort、equal-share 和 fixed-sharez:
- 当使用 fixed-share 调度器时可提供可预知的性能。
- 运行混合的 VDI(Virtual Desktop Infrastructure)和计算工作负载的能力。
- 与业界广泛使用的虚拟机管理程序(hypervisor,如 vmware)的集成能力。
缺点:
- 部署 vGPU 需要额外的软件授权费用。
- 分区仍然通过时间片(time-slicing)完成。
扩展资源名称
如果用户想要知道所使用的集群有哪些代表 GPU 的扩展资源名称,请咨询集群管理员。下面列举了一些常见的代表 GPU 的扩展资源名称。
NVIDIA GPU
当集群安装有 NVIDIA GPU 硬件资源时,通常有下列扩展资源名称:
nvidia.com/gpu:一个扩展资源对应一个 NVIDIA GPU 硬件资源。可以申请多个 GPU,例如当声明资源nvidia.com/gpu: 8时,会有 8 个 NVIDIA GPU 分配给这个工作负载使用。nvidia.com/gpu.shared:通过这个扩展资源,多个工作负载可以共享使用一个 NVIDIA GPU。需要注意的是,当共享机制是通过 Time Slicing 实现时,用户为工作负载设置nvidia.com/gpu.shared扩展资源的数量不能超过 1(参考)。
NVIDIA 还有其他形式的设备名称,例如,当部署了 MIG 技术时,常见的资源名称有:
nvidia.com/mig-3g.20gb:一个扩展资源对应的计算能力是物理 GPU 的 3/7,显存大小是 20GB。nvidia.com/mig-2g.10gb:一个扩展资源对应的计算能力是物理 GPU 的 2/7,显存大小是 10GB。nvidia.com/mig-1g.5gb:一个扩展资源对应的计算能力是物理 GPU 的 1/7,显存大小是 5GB。
AMD GPU
当集群安装有 AMD GPU 硬件资源时,通常有下列扩展资源名称:
amd.com/gpu:一个扩展资源对应一个 AMD GPU 硬件资源。同样地,可以申请多个 GPU,例如amd.com/gpu: 2。
其他
请参考对应厂商的 device plugin 文档。
使用示例
独占 GPU
下面是一个独占使用 GPU 的 PyTorchTrainingJob 示例:
apiVersion: batch.tensorstack.dev/v1beta1
kind: PyTorchTrainingJob
metadata:
name: pytorch-example
spec:
replicaSpecs:
- replicas: 4
restartPolicy: OnFailure
template:
spec:
containers:
- command:
- python
- dist_mnist.py
image: pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel
name: pytorch
resources:
limits:
nvidia.com/gpu: 4
requests:
cpu: 10
memory: 5Gi
type: worker
在该例中,spec.replicaSpecs[0].template.spec.containers[0].resources.limits 字段设置了资源量 nvidia.com/gpu: 4,表示一个 replica 会独占使用 4 个 NVIDIA GPU。同时又设置了 replica 的数量为 4,因此该 PyTorchTrainingJob 总共会占用 16 个 NVIDIA GPU。
共享 GPU
下面是一个以共享方式使用 GPU 的 Notebook 示例:
apiVersion: tensorstack.dev/v1beta1
kind: Notebook
metadata:
name: tutorial
spec:
type: jupyter
template:
spec:
containers:
- name: notebook
image: t9kpublic/torch-2.1.0-notebook:1.77.1
volumeMounts:
- name: workingdir
mountPath: /t9k/mnt
resources:
requests:
cpu: '8'
memory: 16Gi
nvidia.com/gpu.shared: 1
limits:
cpu: '16'
memory: 32Gi
nvidia.com/gpu.shared: 1
volumes:
- name: workingdir
persistentVolumeClaim:
claimName: tutorial
在该例中,spec.template.spec.containers[0].resources.limits 字段设置了资源量 nvidia.com/gpu.shared: 1,表示这个 Notebook 以共享方式使用一个 NVIDIA GPU。
指定 GPU 型号
不同节点上安装的 GPU 型号经常是不同的,而同一厂家的 GPU 对应的扩展资源名称常常是相同的,例如对于 NVIDIA GPU,在不考虑共享 GPU 的情况下,A100 和 A40 型号对应的扩展资源名称都是 nvidia.com/gpu。
调度器为工作负载分配资源时会忽略型号信息,如果用户想让工作负载使用特定型号的 GPU,例如 NVIDIA A100-80GB、NVIDIA A40,可以参考下列方式设置工作负载,使其能被分配到安装有特定型号 GPU 的节点上。
设置 nodeSelector 字段
安装有 GPU 硬件的节点会通过节点标签来表明其安装的 GPU 型号。如果用户将工作负载的 nodeSelector 字段设置为指定型号 GPU 对应的节点标签,并且为工作负载设置了代表 GPU 的扩展资源,那么工作负载就可以使用指定型号的 GPU。
常见的节点标签
如果用户想要知道所使用的集群有哪些表明 GPU 型号的节点标签,请咨询管理员。下面是一些表明 GPU 型号的节点标签示例:
| GPU 型号 | 节点标签 |
|---|---|
| NVIDIA A100-40GB | nvidia.com/gpu.product: NVIDIA-A100-PCIE-40GB |
| NVIDIA A100-80GB | nvidia.com/gpu.product: NVIDIA-A100-PCIE-80GB |
| NVIDIA GTX 1070 | nvidia.com/gpu.product: NVIDIA-GeForce-GTX-1070 |
| NVIDIA TITAN-X | nvidia.com/gpu.product: NVIDIA-TITAN-X |
常见工作负载的 nodeSelector 字段
下面列举了常见的工作负载,以及工作负载用于设置 nodeSelector 的字段:
| 工作负载 | 字段 |
|---|---|
| GenericJob | spec.replicaSpecs[*].template.spec.nodeSelector |
| PyTorchTrainingJob | spec.replicaSpecs[*].template.spec.nodeSelector |
| TensorFlowTrainingJob | spec.replicaSpecs[*].template.spec.nodeSelector |
| XGBoostTrainingJob | spec.replicaSpecs[*].template.spec.nodeSelector |
| DeepSpeedJob | spec.worker.template.spec.nodeSelector |
| ColossalAIJob | spec.worker.template.spec.nodeSelector |
| MPIJob | spec.worker.template.spec.nodeSelector |
| BeamJob | spec.jobTemplate.spec.template.spec.nodeSelector |
| Notebook | spec.template.spec.nodeSelector |
| SimpleMLService | 只有使用自定义框架时,才能通过字段 spec.custom.nodeSelector 设置 nodeSelector |
| MLService predictor | spec.releases[*].predictor.template.spec.nodeSelector |
| MLService transformer | spec.transformer.template..spec.nodeSelector |
| Pod | spec.nodeSelector |
示例
下面是一个设置了 nodeSelector 字段的 Notebook 示例:
apiVersion: tensorstack.dev/v1beta1
kind: Notebook
metadata:
name: tutorial-nodeselector
spec:
type: jupyter
template:
spec:
containers:
- name: notebook
image: t9kpublic/torch-2.1.0-notebook:1.77.1
volumeMounts:
- name: workingdir
mountPath: /t9k/mnt
resources:
limits:
cpu: '16'
memory: 32Gi
nvidia.com/gpu: 1
nodeSelector:
nvidia.com/gpu.product: NVIDIA-A100-PCIE-40GB
volumes:
- name: workingdir
persistentVolumeClaim:
claimName: tutorial
在该例中:
- Notebook 的资源量设置了
nvidia.com/gpu: 1,表示 Notebook 使用一个 GPU。 - Notebook 的
nodeSelector被设置为nvidia.com/gpu.product: NVIDIA-A100-PCIE-40GB,因此 Notebook 的 Pod 会被分配到含有标签nvidia.com/gpu.product: NVIDIA-A100-PCIE-40GB的节点上运行,从而 Notebook 会被分配一个 NVIDIA A100-40GB。
设置队列
通过 nodeSelector 机制指定 GPU 型号的过程繁琐,并且管理员也缺乏对 GPU 使用权限的方便控制。平台提供了更加便捷的队列机制方便用户使用特定类型的资源。
当满足以下条件时,可以通过设置队列来使用特定型号的 GPU:
在创建工作负载时,进行下列操作以使用特定型号的 GPU:
- 使用 T9k Scheduler。
- 设置队列名称,例如
a100。 - 设置代表 GPU 的扩展资源,例如
nvidia.com/gpu。
示例
假设管理员创建并设置了两个队列,名称分别是:
a100:队列可以使用的节点上都安装了 NVIDIA A100-80GB。a40:队列可以使用的节点上都安装了 NVIDIA A40-40GB。
并且用户有它们的使用权限。那么如果用户想要创建一个使用一个 NVIDIA A100-80GB 的 Notebook,则可以使用以下 YAML 配置文件:
apiVersion: tensorstack.dev/v1beta1
kind: Notebook
metadata:
name: tutorial
spec:
type: jupyter
scheduler:
t9kScheduler:
queue: a100
template:
spec:
containers:
- name: notebook
image: t9kpublic/torch-2.1.0-notebook:1.77.1
volumeMounts:
- name: workingdir
mountPath: /t9k/mnt
resources:
limits:
cpu: '16'
memory: 32Gi
nvidia.com/gpu: 1
volumes:
- name: workingdir
persistentVolumeClaim:
claimName: tutorial
在该例中:
- Notebook 的资源量设置了
nvidia.com/gpu: 1,表示 Notebook 使用一个 GPU。 - 字段
spec.scheduler.t9kScheduler.queue被设置为a100,表示 Notebook 使用 T9k Scheduler 进行资源调度,并且使用队列a100。