分布式训练场景
本教程演示如何记录并展示 PyTorchTrainingJob 分布式训练场景下的训练产生的信息、指标和文件(以 PyTorch 模型的数据并行训练为例)。
运行示例
请按照使用方法准备环境,然后前往本教程对应的示例,参照其 README 文档运行。
下面介绍训练脚本进行了哪些修改以追踪训练。该方法是通用的,可以推广到任意类型的 TrainingJob、DeepSpeedJob、ColossalAIJob、MPIJob 或 GenericJob。
准备训练脚本
准备一个 PyTorch 训练脚本,其模型对 MNIST 数据集的图像进行分类,使用 DistributedDataParallel(DDP)模块进行分布式训练,具体代码如下所示(这里使用与使用 PyTorchTrainingJob 进行数据并行训练相同的脚本)。接下来将在此脚本的基础上进行简单的修改以进行追踪。
torch_mnist_trainingjob_em.py
import argparse
import logging
import os
import shutil
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
parser = argparse.ArgumentParser(
description='Distributed training of Keras model for MNIST with DDP.')
parser.add_argument(
'--backend',
type=str,
help='Distributed backend',
choices=[dist.Backend.GLOO, dist.Backend.NCCL, dist.Backend.MPI],
default=dist.Backend.GLOO)
parser.add_argument('--log_dir',
type=str,
default='/mnt/log',
help='Path of the TensorBoard log directory.')
parser.add_argument('--no_cuda',
action='store_true',
default=False,
help='Disable CUDA training.')
logging.basicConfig(format='%(message)s', level=logging.INFO)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv3 = nn.Conv2d(64, 64, 3, 1)
self.pool = nn.MaxPool2d(2, 2)
self.dense1 = nn.Linear(576, 64)
self.dense2 = nn.Linear(64, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = torch.flatten(x, 1)
x = F.relu(self.dense1(x))
output = F.softmax(self.dense2(x), dim=1)
return output
def train(scheduler):
global global_step
for epoch in range(1, epochs + 1):
model.train()
for step, (data, target) in enumerate(train_loader, 1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if step % (500 // world_size) == 0:
train_loss = loss.item()
logging.info(
'epoch {:d}/{:d}, batch {:5d}/{:d} with loss: {:.4f}'.
format(epoch, epochs, step, steps_per_epoch, train_loss))
global_step = (epoch - 1) * steps_per_epoch + step
if args.log_dir and rank == 0:
writer.add_scalar('train/loss', train_loss, global_step)
scheduler.step()
global_step = epoch * steps_per_epoch
test(val=True, epoch=epoch)
def test(val=False, epoch=None):
label = 'val' if val else 'test'
model.eval()
running_loss = 0.0
correct = 0
with torch.no_grad():
loader = val_loader if val else test_loader
for data, target in loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
prediction = output.max(1)[1]
correct += (prediction == target).sum().item()
test_loss = running_loss / len(loader)
test_accuracy = correct / len(loader.dataset)
msg = '{:s} loss: {:.4f}, {:s} accuracy: {:.4f}'.format(
label, test_loss, label, test_accuracy)
if val:
msg = 'epoch {:d}/{:d} with '.format(epoch, epochs) + msg
logging.info(msg)
if args.log_dir and rank == 0:
writer.add_scalar('{:s}/loss'.format(label), test_loss, global_step)
writer.add_scalar('{:s}/accuracy'.format(label), test_accuracy,
global_step)
if __name__ == '__main__':
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
if use_cuda:
logging.info('Using CUDA')
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
logging.info('Using distributed PyTorch with {} backend'.format(
args.backend))
dist.init_process_group(backend=args.backend)
rank = dist.get_rank()
world_size = dist.get_world_size()
torch.manual_seed(1)
model = Net().to(device)
model = DDP(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001 * world_size)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.7)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))])
train_dataset = datasets.MNIST(root='./data',
train=True,
download=False,
transform=transform)
train_dataset, val_dataset = torch.utils.data.random_split(
train_dataset, [48000, 12000])
test_dataset = datasets.MNIST(root='./data',
train=False,
download=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=32 * world_size,
shuffle=True,
**kwargs)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=400,
shuffle=False,
**kwargs)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=1000,
shuffle=False,
**kwargs)
if args.log_dir and rank == 0:
log_dir = args.log_dir
if os.path.exists(log_dir):
shutil.rmtree(log_dir, ignore_errors=True)
writer = SummaryWriter(log_dir)
global_step = 0
epochs = 10
steps_per_epoch = len(train_loader)
train(scheduler)
test()
创建 Run
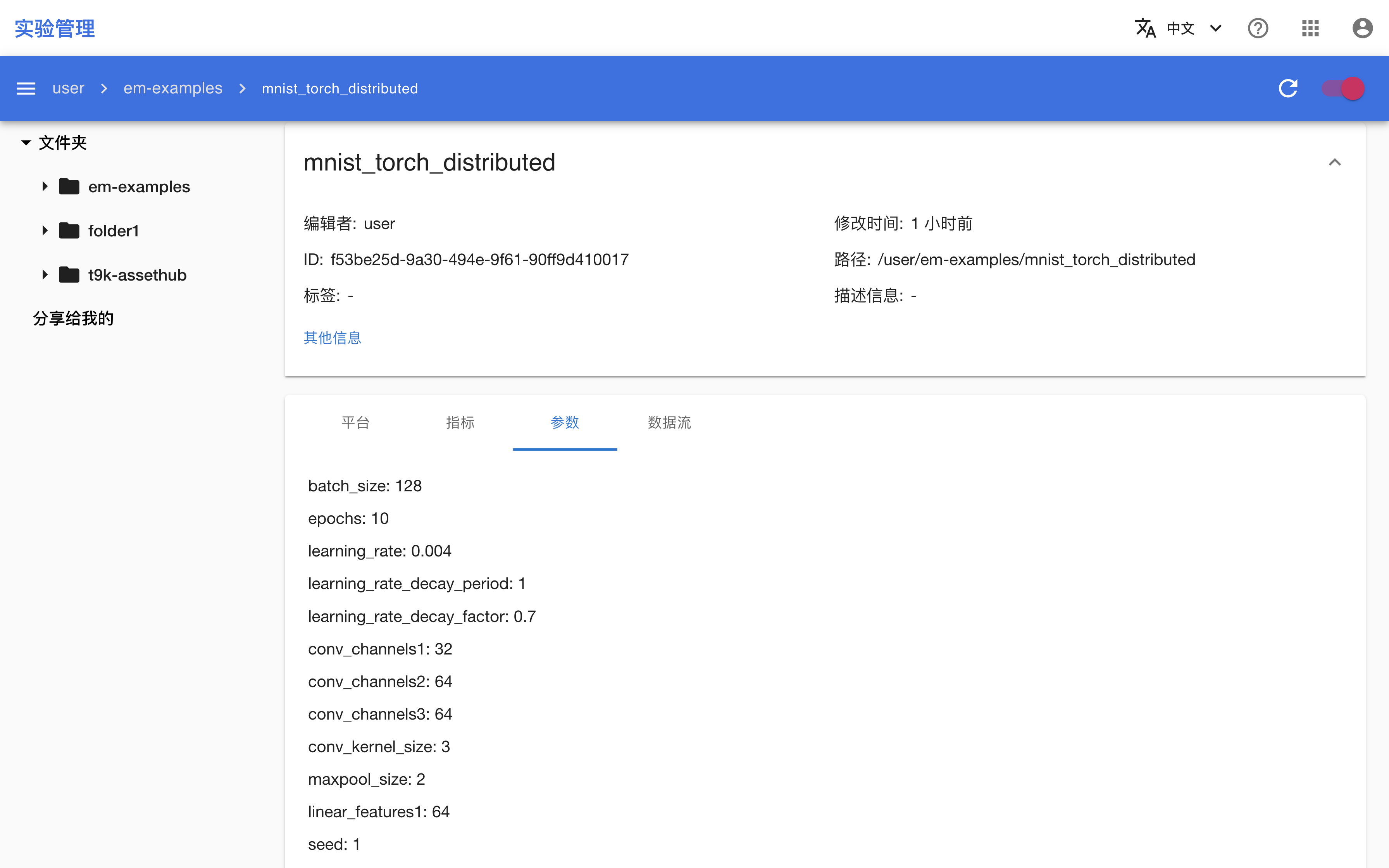
创建一个包含所有(想要记录的)超参数的 Python 字典。
from t9k import em
if __name__ == '__main__':
...
hparams = {
'batch_size': 32 * world_size,
'epochs': 10,
'learning_rate': 0.001 * world_size,
'learning_rate_decay_period': 1,
'learning_rate_decay_factor': 0.7,
'conv_channels1': 32,
'conv_channels2': 64,
'conv_channels3': 64,
'conv_kernel_size': 3,
'maxpool_size': 2,
'linear_features1': 64,
'seed': 1,
}
...
指定一个工作器负责在建立模型之前创建并初始化一个 Run 实例,传入名称和上面的超参数字典。
if __name__ == '__main__':
...
if rank == 0:
run = em.create_run(name='mnist_torch_distributed', hparams=hparams)
...
使用设定的超参数配置模型
使用上面的超参数字典的值替换直接提供的超参数值,以配置模型各层、数据集、优化器、训练流程等。
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, hparams['conv_channels1'],
hparams['conv_kernel_size'], 1)
self.conv2 = nn.Conv2d(hparams['conv_channels1'],
hparams['conv_channels2'],
hparams['conv_kernel_size'], 1)
self.conv3 = nn.Conv2d(hparams['conv_channels2'],
hparams['conv_channels3'],
hparams['conv_kernel_size'], 1)
self.pool = nn.MaxPool2d(hparams['maxpool_size'],
hparams['maxpool_size'])
self.dense1 = nn.Linear(576, hparams['linear_features1'])
self.dense2 = nn.Linear(hparams['linear_features1'], 10)
...
if __name__ == '__main__':
...
torch.manual_seed(hparams['seed'])
...
optimizer = optim.Adam(model.parameters(), lr=hparams['learning_rate'])
scheduler = optim.lr_scheduler.StepLR(
optimizer,
step_size=hparams['learning_rate_decay_period'],
gamma=hparams['learning_rate_decay_factor'])
...
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=hparams['batch_size'],
shuffle=True,
**kwargs)
...
epochs = hparams['epochs']
...
记录指标
在模型的训练和测试过程中,被指定的工作器调用 Run 实例的 log() 方法以记录模型在此期间产生的指标。
def train(scheduler):
...
if step % (500 // world_size) == 0:
train_loss = loss.item()
logging.info(
'epoch {:d}/{:d}, batch {:5d}/{:d} with loss: {:.4f}'.
format(epoch, epochs, step, steps_per_epoch, train_loss))
global_step = (epoch - 1) * steps_per_epoch + step
if rank == 0:
run.log(type='train', # 记录训练指标
metrics={'loss': train_loss}, # 指标名称及相应值
step=global_step, # 当前全局步数
epoch=epoch) # 当前回合数
...
def test(val=False, epoch=None):
...
test_loss = running_loss / len(loader)
test_accuracy = correct / len(loader.dataset)
msg = '{:s} loss: {:.4f}, {:s} accuracy: {:.4f}'.format(
label, test_loss, label, test_accuracy)
if val:
msg = 'epoch {:d}/{:d} with '.format(epoch, epochs) + msg
logging.info(msg)
if rank == 0:
run.log(type=label, # 记录验证/测试指标
metrics={
'loss': test_loss,
'accuracy': test_accuracy,
},
step=global_step,
epoch=epoch)
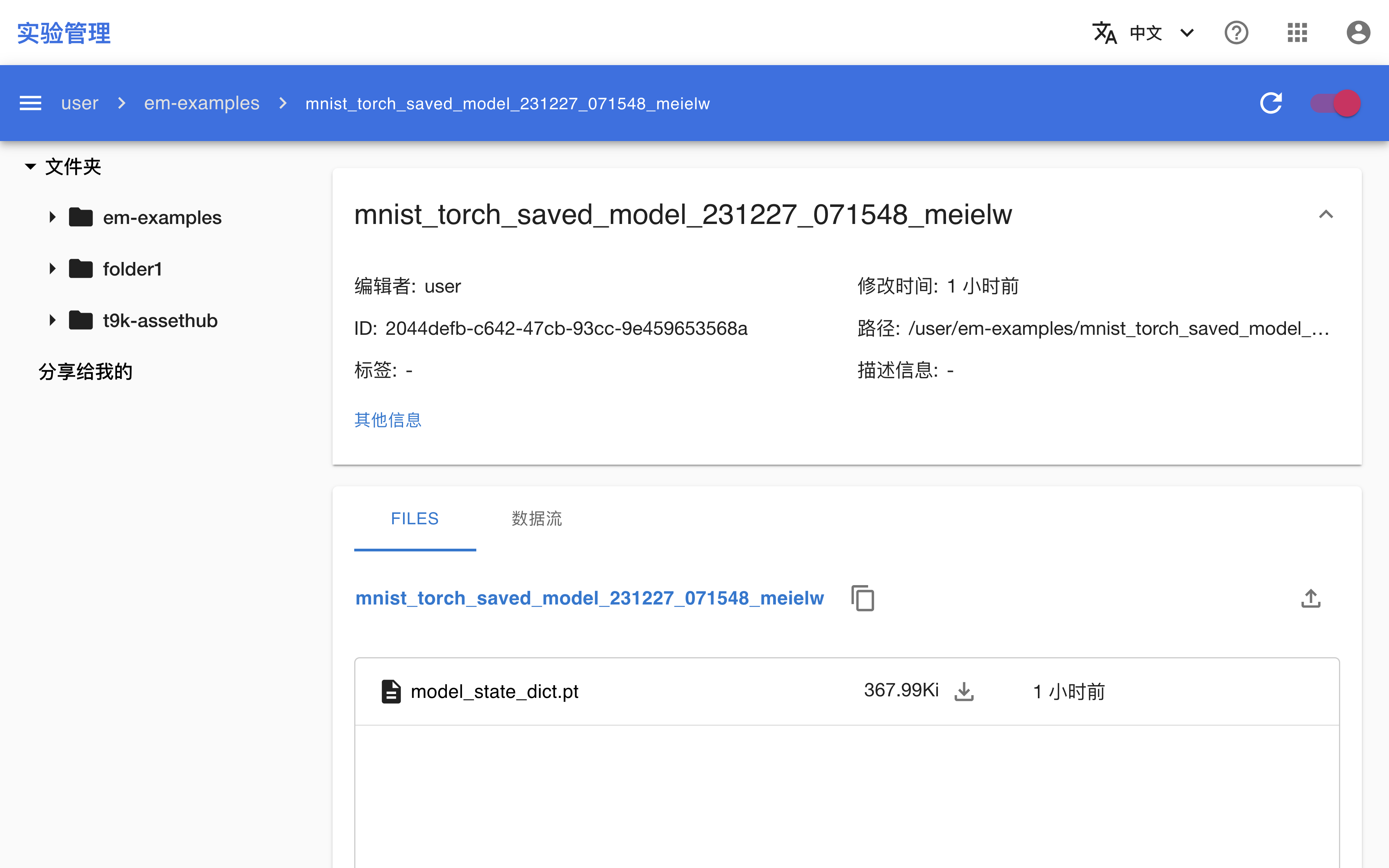
创建 Artifact 并添加模型检查点文件
在保存模型检查点文件之后,被指定的工作器创建并初始化一个新的 Artifact 实例,为其添加该检查点文件,并标记为 Run 的输出。
if __name__ == '__main__':
...
if rank == 0:
torch.save(model.state_dict(), 'model_state_dict.pt')
model_artifact = em.create_artifact(name='mnist_torch_saved_model')
model_artifact.add_file('model_state_dict.pt')
run.mark_output(model_artifact)
...
结束和上传试验
模型的训练和测试结束后,被指定的工作器调用 Run 实例的 finish() 和 upload() 方法以结束和上传 Run(Artifact 也会被一并上传)。在上传之前需要调用 em.login() 函数以登录到服务器。
if __name__ == '__main__':
...
if rank == 0:
run.finish()
em.login()
run.upload(folder='em-examples', make_folder=True)
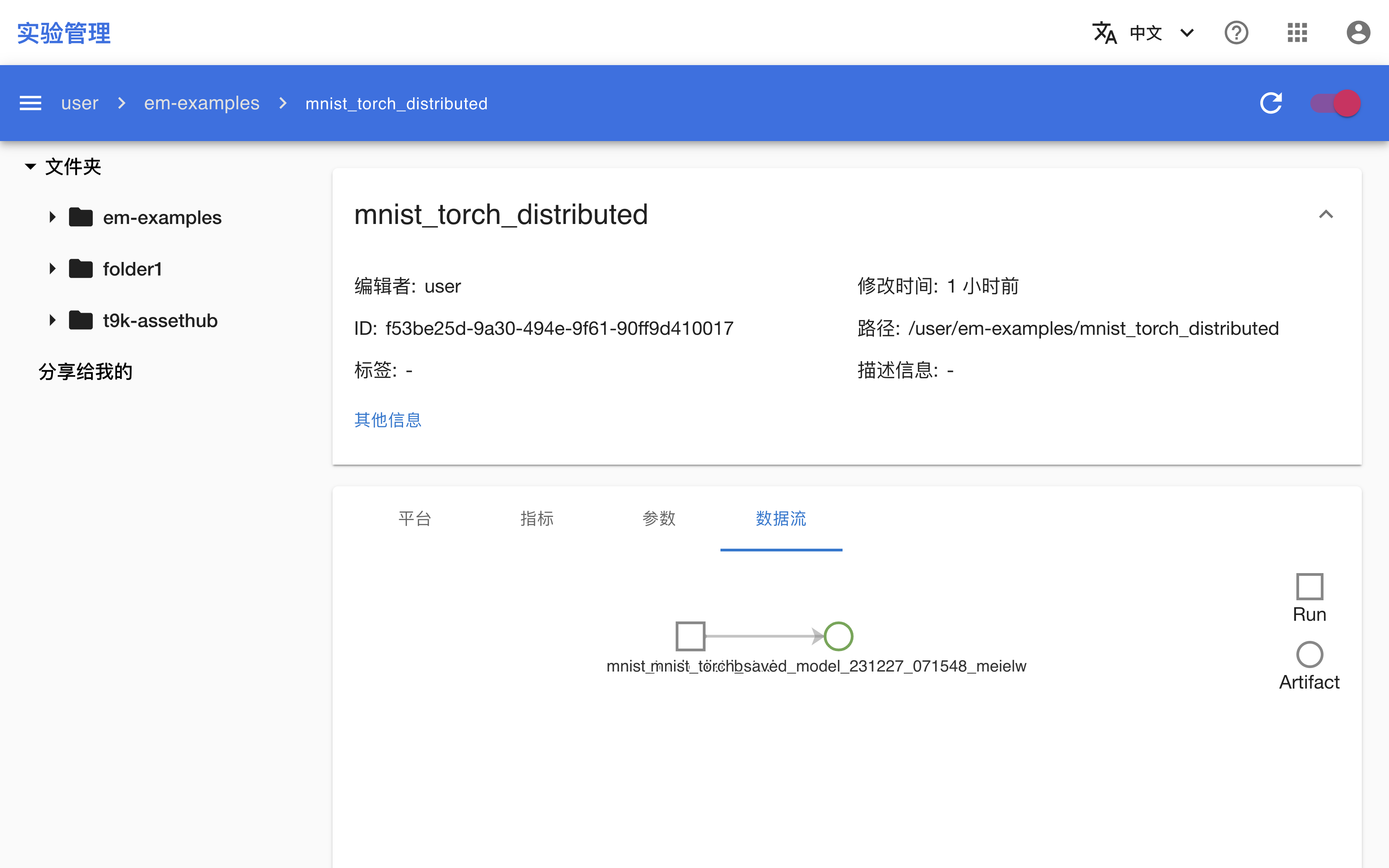
检查 Run 和 Artifact
训练结束后,进入实验管理控制台,可以看到名为 mnist_torch_distributed 的 Run 及其输出的 Artifact 被上传:
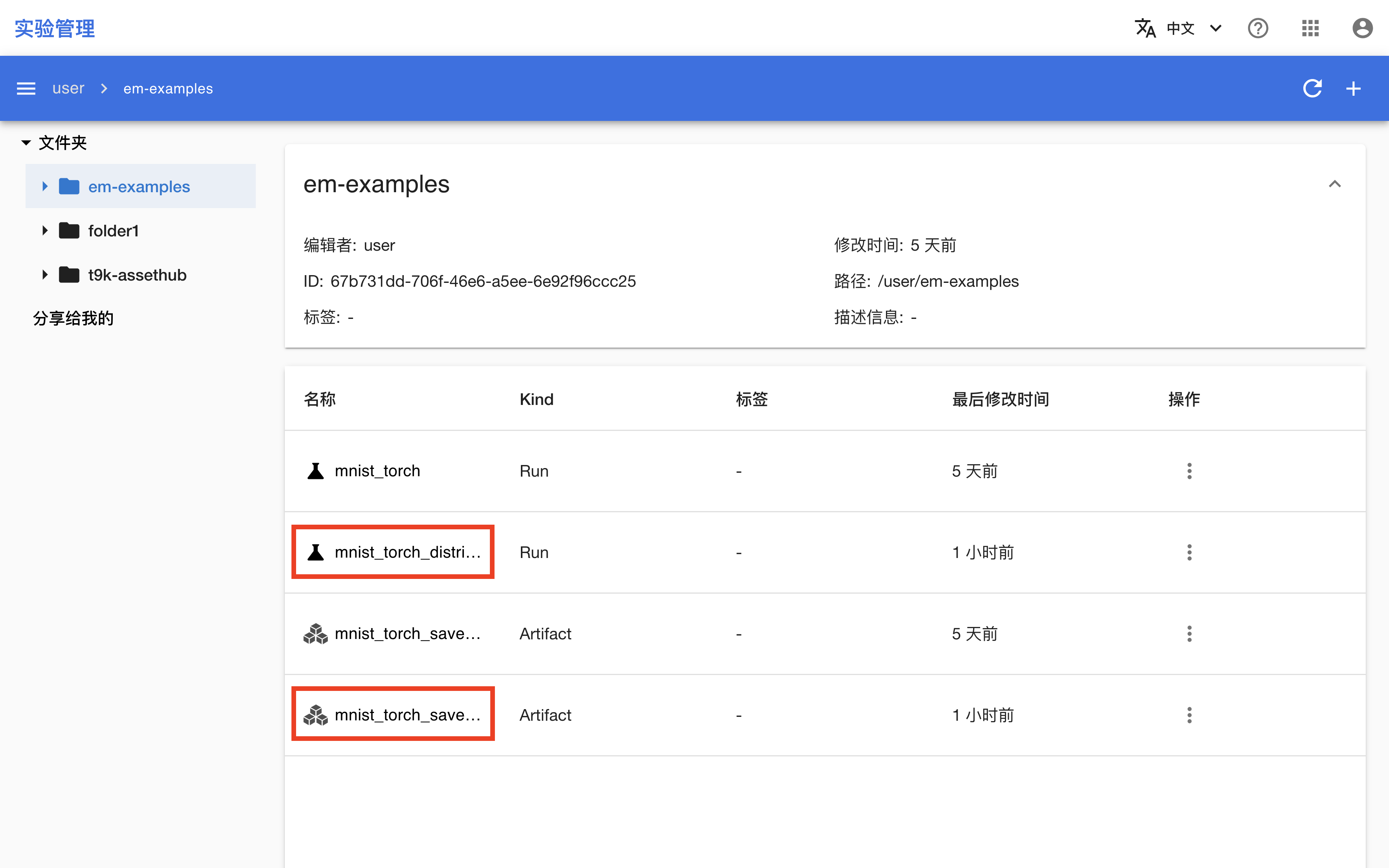
点击 Run 或 Artifact 的名称进入其详情页面,可以看到 Run 的平台信息、指标、超参数和数据流,以及 Artifact 的文件和数据流。并且它们的数据流是连通的。