使用 FastChat 部署 LLM 推理服务
平台提供的 SimpleMLService 和 MLService 资源可以让用户方便地部署各种基于 LLM 的服务和应用。
FastChat 是一个训练、伺服和评估基于 LLM 的聊天机器人的开放平台,其提供多种伺服方式,包括命令行、Web UI、兼容 OpenAI 的 RESTful API 等。
本示例使用 SimpleMLService 和 FastChat 框架部署一个 LLM 推理服务。模型存储使用 PVC。
准备
在项目中创建一个名为 fastchat、大小 50 GiB 以上的 PVC,然后创建一个同样名为 fastchat 的 Notebook 挂载该 PVC(镜像类型和模板不限)。
进入 Notebook 或远程连接到 Notebook,启动一个终端,执行以下命令以克隆 t9k/examples 仓库:
cd ~
git clone https://github.com/t9k/examples.git
然后从 Hugging Face Hub 或魔搭社区下载要部署的模型,这里以 chatglm3-6b 模型为例:
# 方法 1:如果可以直接访问 huggingface
huggingface-cli download THUDM/chatglm3-6b \
--local-dir chatglm3-6b --local-dir-use-symlinks False
# 方法 2:对于国内用户,访问 modelscope 网络连通性更好
pip install modelscope
python -c \
"from modelscope import snapshot_download; snapshot_download('ZhipuAI/chatglm3-6b')"
mv .cache/modelscope/hub/ZhipuAI/chatglm3-6b .
部署
这里使用 FastChat 部署兼容 OpenAI API 的服务器。
使用以下 YAML 配置文件创建 SimpleMLService:
cd examples/deployments/fastchat
kubectl create -f simplemlservice.yaml
监控服务是否准备就绪:
kubectl get -f simplemlservice.yaml -w
待其 READY 值变为 true 后,便可开始使用该服务。第一次拉取镜像可能会花费较长的时间,具体取决于集群的网络状况。
使用推理服务
继续使用 Notebook 的终端,使用 curl 命令发送聊天或生成文本的请求:
address=$(kubectl get -f simplemlservice.yaml -ojsonpath='{.status.address.url}')
# 聊天
curl ${address}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "chatglm3-6b",
"messages": [{"role": "user", "content": "你好"}],
"temperature": 0.5
}'
# 当前生成文本存在错误
返回的响应类似于:
响应
{
"id": "chatcmpl-3NXy9QnaD8FzH3PJrjaNVL",
"object": "chat.completion",
"created": 1708941050,
"model": "chatglm3-6b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"total_tokens": 38,
"completion_tokens": 30
}
}
为聊天增加 UI 界面
为了让聊天有一个简洁而美观的 UI 界面,我们可以使用 ChatGPT-Next-Web 提供的桌面客户端,在这里下载相应平台的安装包并进行安装。
继续使用 Notebook 的终端,获取 SimpleMLService 创建的服务的名称:
echo ${address} | cut -d'.' -f1
然后打开本地的终端,使用 t9k-pf 命令行工具,将该服务的 80 端口转发到本地的 8000 端口:
t9k-pf service <SERVICE_NAME> 8000:80 -n <PROJECT_NAME>
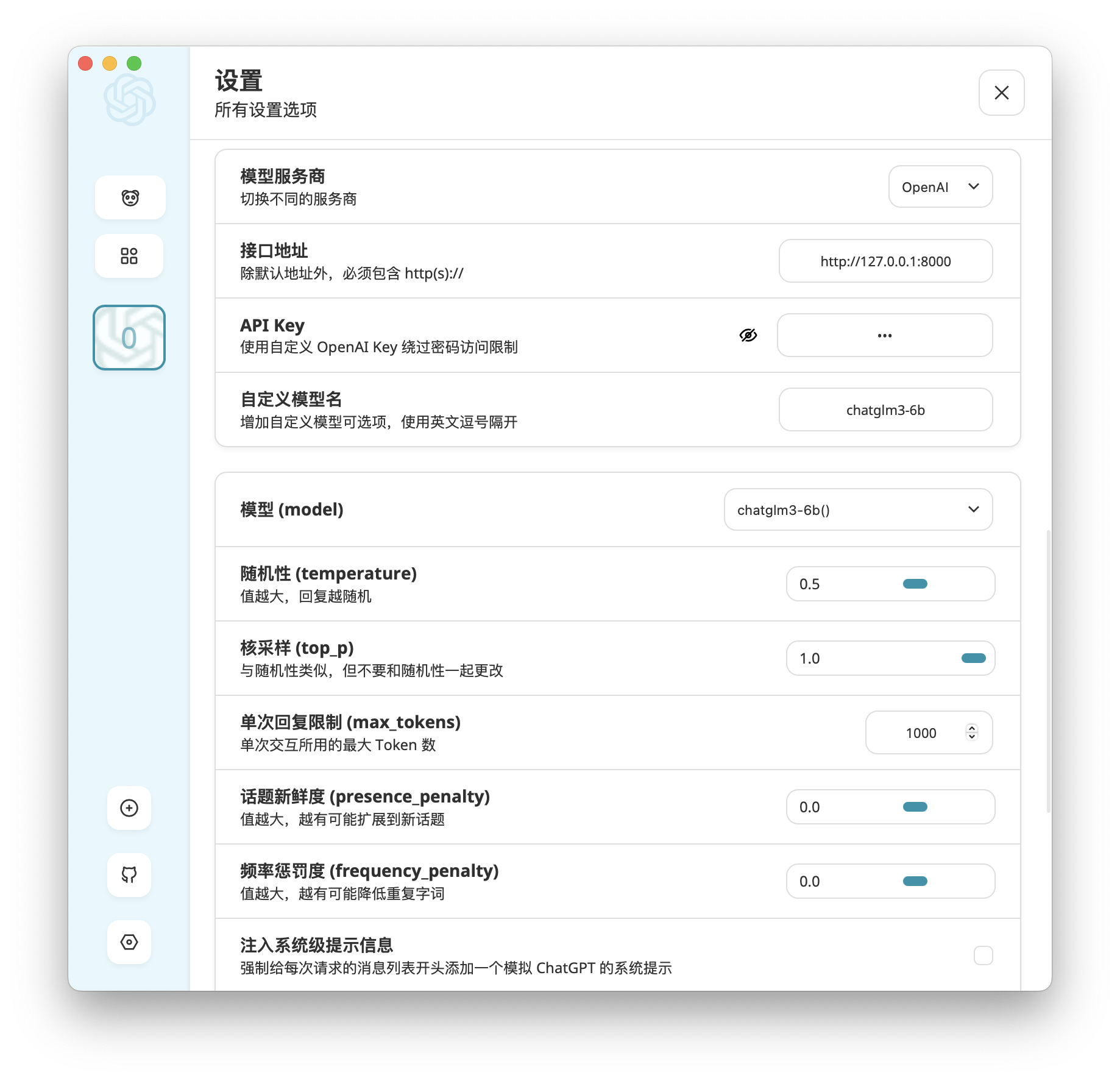
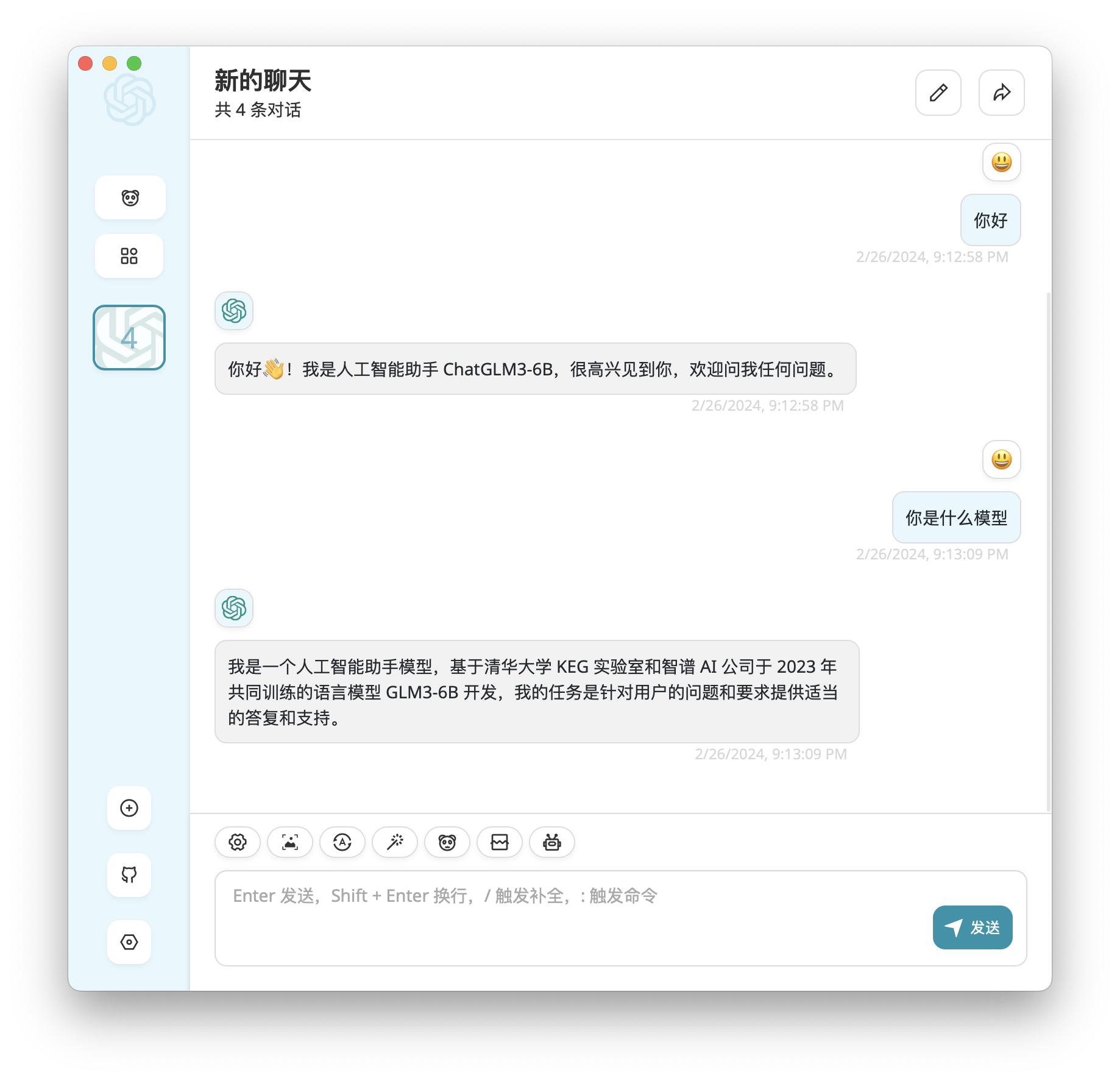
在桌面客户端的设置中,接口地址填写 http://127.0.0.1:8000,自定义模型名填写 chatglm3-6b 并选择该模型,其他设置保持不变,就可以开始聊天了:
扩展:部署其他 LLM
我们可以使用同样的方法部署其他支持的模型,例如要将本示例部署的模型从 ChatGLM3-6B 换成 LLaMA2-7B-chat,只需:
- 下载 LLaMA2-7B-chat 的模型文件:
# 方法 1:如果可以直接访问 huggingface
# 需要登录
huggingface-cli download meta-llama/Llama-2-7b-chat-hf \
--local-dir Llama-2-7b-chat-hf --local-dir-use-symlinks False
# 方法 2:对于国内用户,访问 modelscope 网络连通性更好
pip install modelscope
python -c \
"from modelscope import snapshot_download; snapshot_download('shakechen/Llama-2-7b-chat-hf')"
mv .cache/modelscope/hub/shakechen/Llama-2-7b-chat-hf .
- 对 SimpleMLService 的 YAML 配置文件作以下修改,再次创建即可:
$ diff --color -u simplemlservice.yaml simplemlservice-llama2.yaml
--- simplemlservice.yaml
+++ simplemlservice-llama2.yaml
@@ -10,8 +10,8 @@
storage:
pvc:
name: fastchat
- subPath: chatglm3-6b
- containerPath: /workspace/chatglm3-6b
+ subPath: Llama-2-7b-chat-hf
+ containerPath: /workspace/llama2-7b-chat
service:
type: ClusterIP
ports:
@@ -23,7 +23,7 @@
- name: server
image: t9kpublic/fastchat-openai:20240227
args:
- - "chatglm3-6b"
+ - "llama2-7b-chat"
ports:
- containerPort: 80
resources: