使用 Profiler 分析模型训练性能
概述
PyTorch 提供的 profiler 工具允许在训练和推理过程中收集性能指标,从而帮助用户更好地理解运算的代价和内存等资源消耗,测量 CPU 计算代价,CPU-GPU 之间数据复制成本,研究 GPU 内核程序性能并可视化执行追踪等。用户在 Notebook 中可以方便地使用这一工具。
本教程将介绍如何在 Notebook 中对启动 LLM 大规模预训练中的训练进行性能分析。
准备
在启动 LLM 大规模预训练给出的准备工作的基础上,还需要修改 Megatron-DeepSpeed 的训练代码,用 profiler 上下文管理器包装训练循环的代码。直接使用 Notebook 的文本编辑器修改代码即可。
# Megatron-DeepSpeed/megatron/training.py
...
profile_path = os.path.join(os.path.dirname(args.tensorboard_dir), 'profiling')
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=2),
on_trace_ready=torch.profiler.tensorboard_trace_handler(profile_path),
record_shapes=True,
profile_memory=True,
with_stack=True,
with_flops=True,
with_modules=True
) as prof: # profiler context manager
while iteration < args.train_iters and (args.train_tokens is None or \
args.consumed_train_tokens < args.train_tokens): # training loop
...
prof.step()
...
其中对于 profiler 的配置为:
- profiler 跳过 1 个 step,热身 1 个 step,然后记录 3 个 step;总共重复 2 次。
- 生成用于 TensorBoard 展示的结果文件,与 TensorBoard 日志文件保存到同一父目录下。
- 记录算子的源信息和输入形状,记录模块(module)的调用栈,估计 FLOPS,跟踪张量内存的分配和释放。
启动性能分析
以 4 个 GPU 训练 125M 参数的 GPT 模型,启动训练:
kubectl create -f \
examples/deepspeed/megatron-gpt/training/gpt-125m-4xdp.yaml
通过以下命令查看训练过程中打印的日志:
kubectl logs gpt-125m-4xdp-worker-0 -f
性能分析完成之后,结果文件被保存在 output/gpt-125m-4xdp/profiling 路径下,前往该路径并启动一个 TensorBoard 实例以查看可视化结果。
查看可视化结果
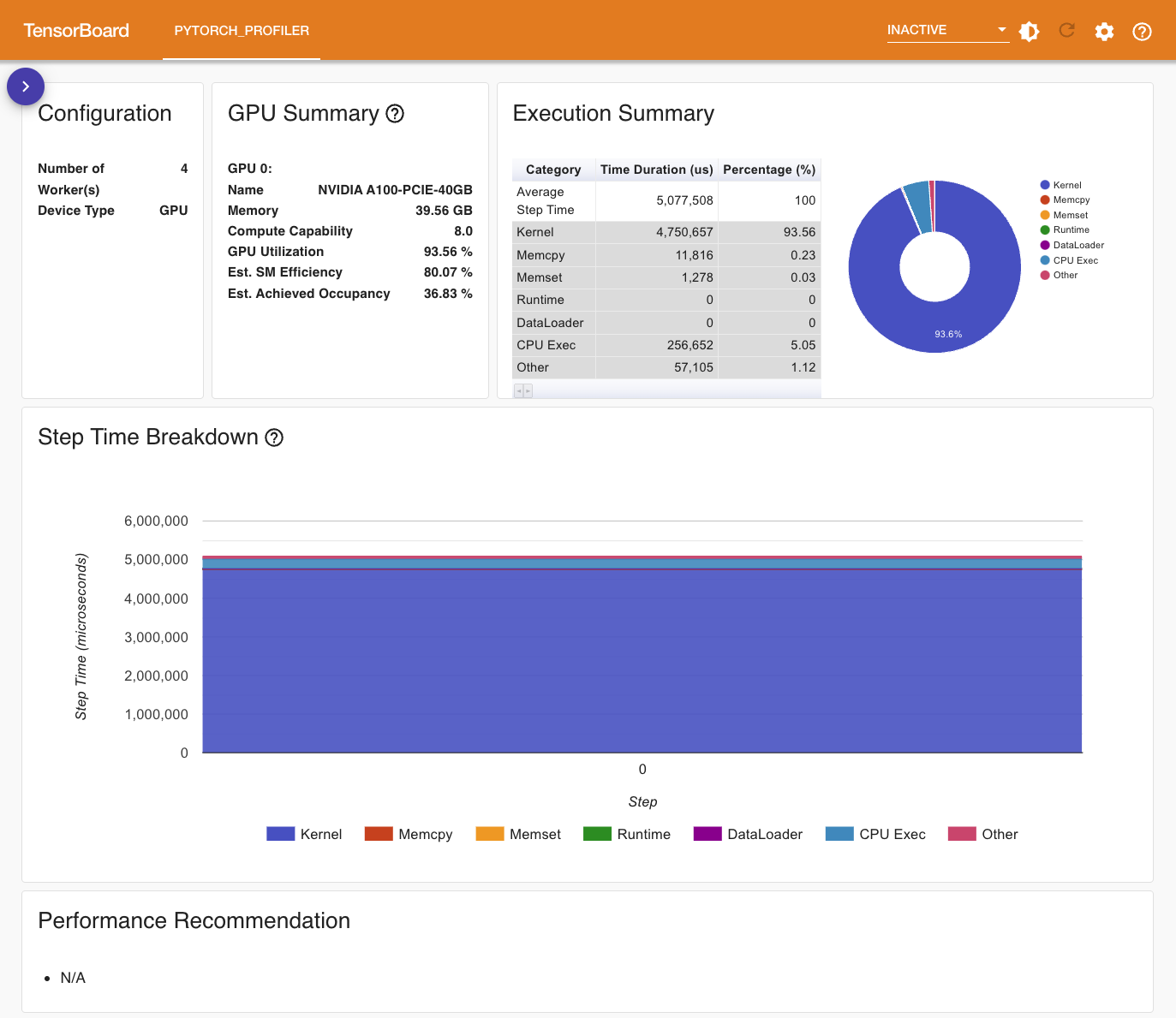
Overview 展示了训练性能的总体情况,包含 GPU 的总体情况、不同执行类别花费的时间和占比,以及自动生成的性能优化建议:
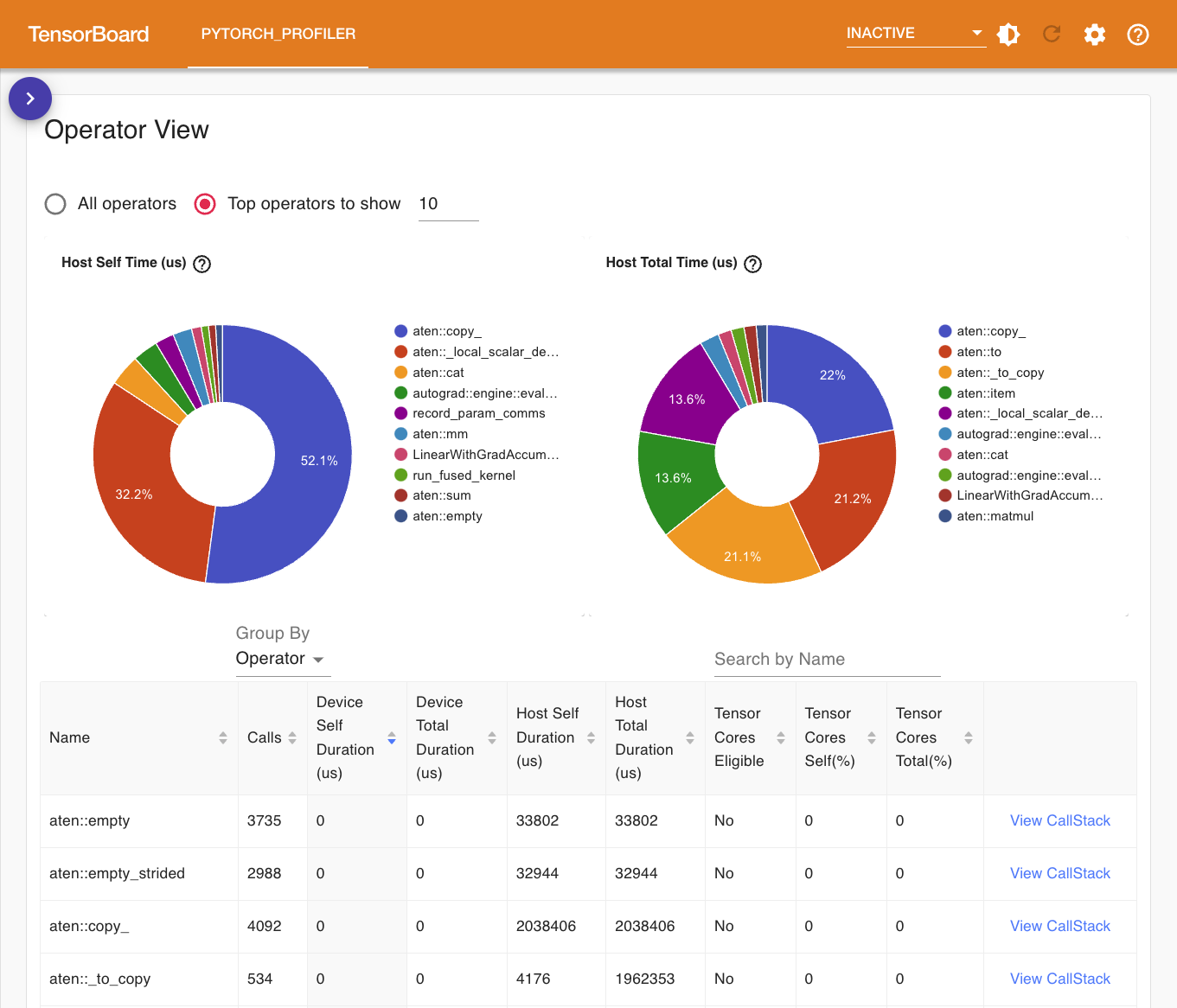
Operator View 展示了所有 PyTorch 算子被调用的次数、花费的时间以及它的调用栈:
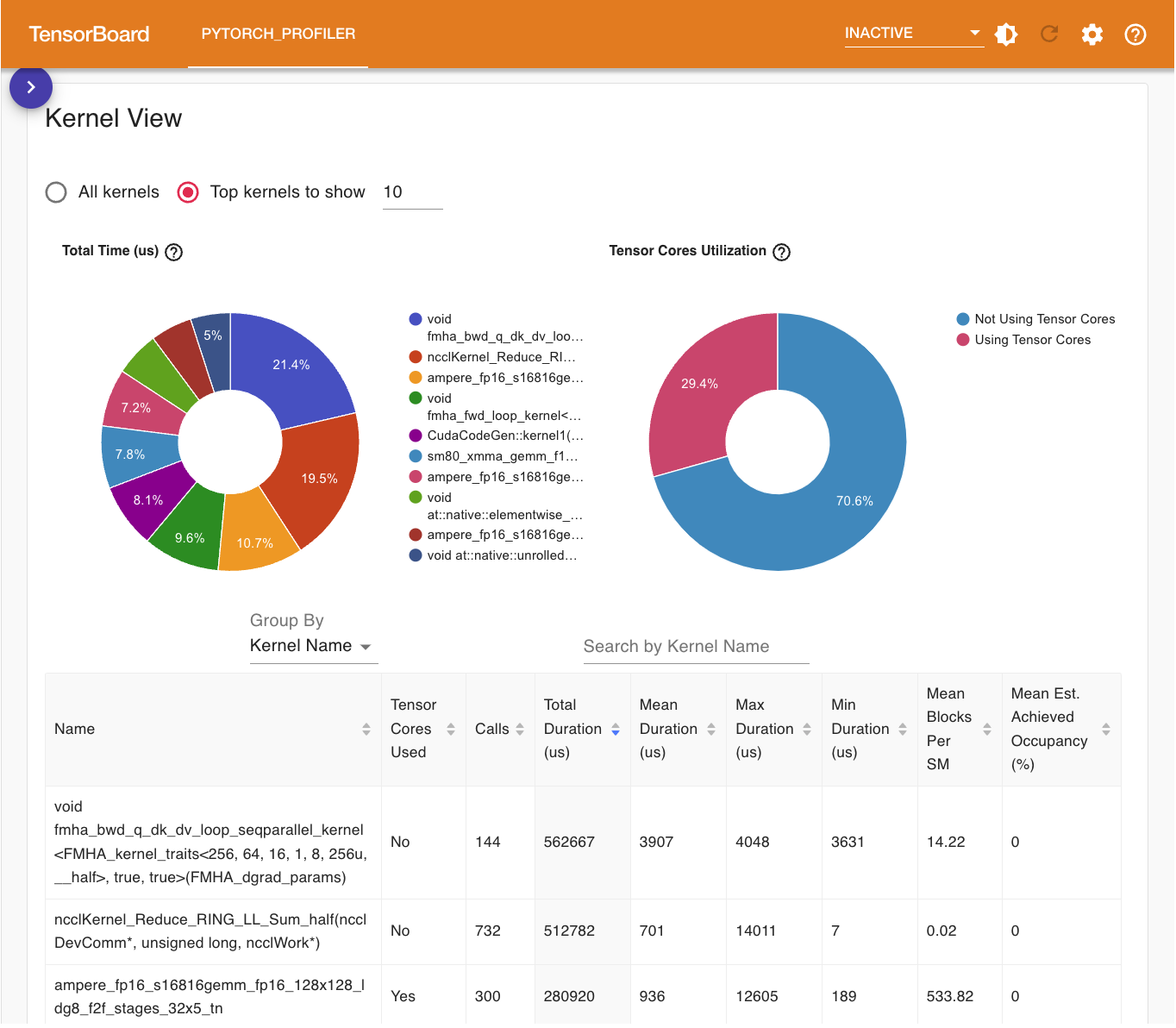
Kernel View 展示了所有 GPU 内核被调用的次数、花费的时间的统计以及它是否使用了 Tensor Core 等:
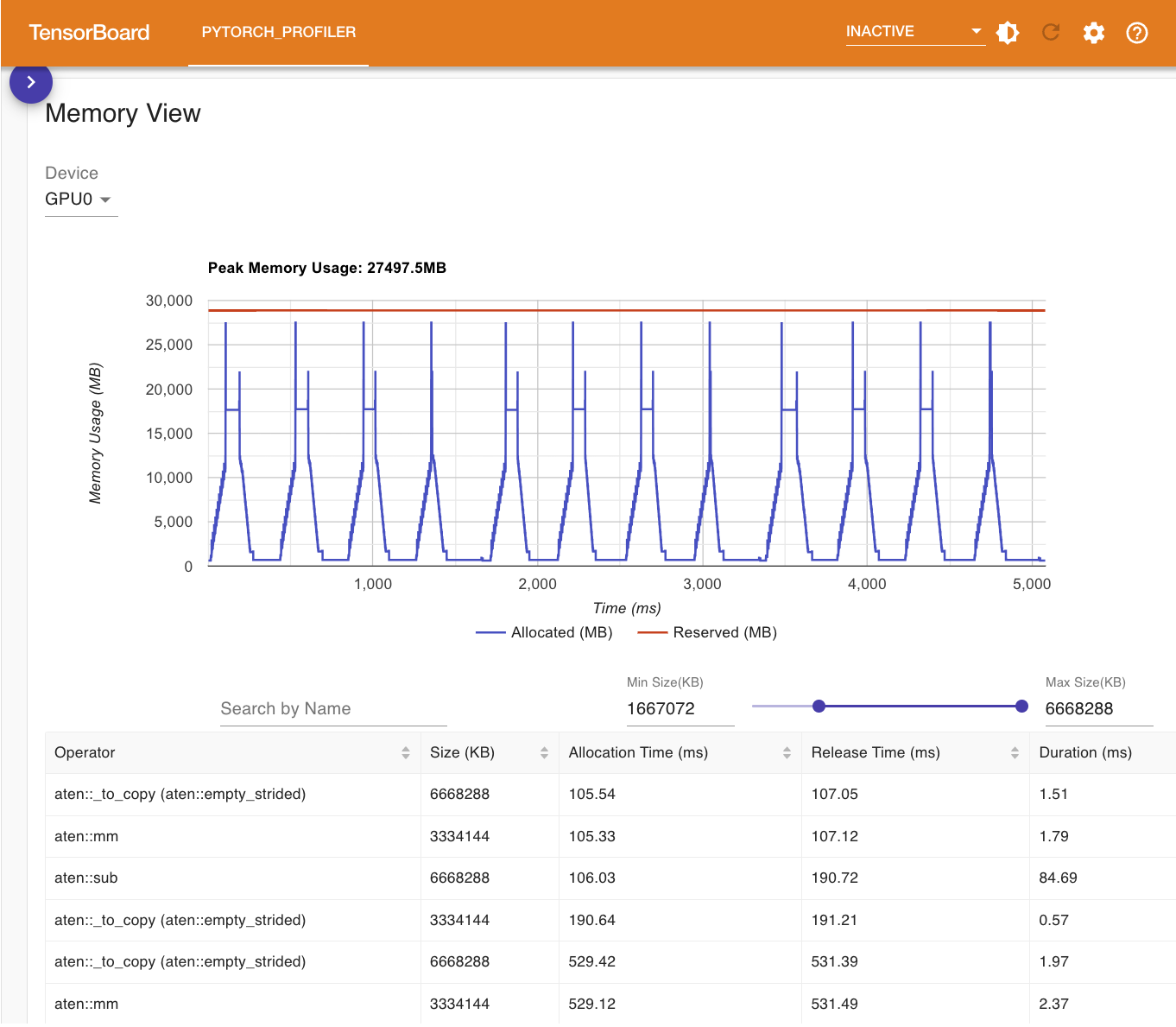
Memory View 展示了内存使用曲线图、内存事件(分配和释放)以及内存统计数据:
TensorBoard 所展示的数据和提供的功能还远不止这些,请参阅官方教程以了解更多。这些数据应当能为用户分析和改进性能提供非常有用的帮助。