进行并行训练
本教程带领你使用 PyTorchTrainingJob,将教程训练你的第一个模型中的模型训练改进为使用 GPU 加速的数据并行训练。
在 Notebook 中准备并行训练
回到 Notebook mnist,在 HOME 目录(即左侧边栏文件浏览器显示的根目录 /)下,点击左上角的 +,然后点击 Other 下的 Python File 以新建一个 Python 脚本文件。

向该文件复制以下代码,并将其命名为 torch_mnist_trainingjob.py。该脚本在上一篇教程的脚本的基础上进行了修改以支持数据并行训练。
torch_mnist_trainingjob.py
import argparse
import logging
import os
import shutil
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
parser = argparse.ArgumentParser(
description='DDP training of PyTorch model for MNIST.')
parser.add_argument(
'--backend',
type=str,
help='Distributed backend',
choices=[dist.Backend.GLOO, dist.Backend.NCCL, dist.Backend.MPI],
default=dist.Backend.GLOO)
parser.add_argument('--log_dir',
type=str,
help='Path of the TensorBoard log directory.')
parser.add_argument('--save_path',
type=str,
help='Path of the saved model.')
parser.add_argument('--no_cuda',
action='store_true',
default=False,
help='Disable CUDA training.')
logging.basicConfig(format='%(message)s', level=logging.INFO)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv3 = nn.Conv2d(64, 64, 3, 1)
self.pool = nn.MaxPool2d(2, 2)
self.dense1 = nn.Linear(576, 64)
self.dense2 = nn.Linear(64, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = torch.flatten(x, 1)
x = F.relu(self.dense1(x))
output = F.softmax(self.dense2(x), dim=1)
return output
def train():
global global_step
for epoch in range(1, epochs + 1):
model.train()
for step, (data, target) in enumerate(train_loader, 1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if step % (500 // world_size) == 0:
train_loss = loss.item()
logging.info(
'epoch {:d}/{:d}, batch {:5d}/{:d} with loss: {:.4f}'.
format(epoch, epochs, step, steps_per_epoch, train_loss))
global_step = (epoch - 1) * steps_per_epoch + step
if args.log_dir and rank == 0:
writer.add_scalar('train/loss', train_loss, global_step)
scheduler.step()
global_step = epoch * steps_per_epoch
test(val=True, epoch=epoch)
def test(val=False, epoch=None):
label = 'val' if val else 'test'
model.eval()
running_loss = 0.0
correct = 0
with torch.no_grad():
loader = val_loader if val else test_loader
for data, target in loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
prediction = output.max(1)[1]
correct += (prediction == target).sum().item()
test_loss = running_loss / len(loader)
test_accuracy = correct / len(loader.dataset)
msg = '{:s} loss: {:.4f}, {:s} accuracy: {:.4f}'.format(
label, test_loss, label, test_accuracy)
if val:
msg = 'epoch {:d}/{:d} with '.format(epoch, epochs) + msg
logging.info(msg)
if args.log_dir and rank == 0:
writer.add_scalar('{:s}/loss'.format(label), test_loss, global_step)
writer.add_scalar('{:s}/accuracy'.format(label), test_accuracy,
global_step)
if __name__ == '__main__':
args = parser.parse_args()
logging.info('Using distributed PyTorch with %s backend', args.backend)
dist.init_process_group(backend=args.backend)
rank = dist.get_rank()
world_size = dist.get_world_size()
local_rank = int(os.environ['LOCAL_RANK'])
use_cuda = not args.no_cuda and torch.cuda.is_available()
if use_cuda:
logging.info('Using CUDA')
device = torch.device('cuda:{}'.format(local_rank) if use_cuda else 'cpu')
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
torch.manual_seed(1)
dataset_path = os.path.join(os.path.dirname(os.path.realpath(__file__)),
'data')
# rank 0 downloads datasets in advance
if rank == 0:
datasets.MNIST(root=dataset_path, train=True, download=True)
model = Net().to(device)
model = DDP(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001 * world_size)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.7)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))])
train_dataset = datasets.MNIST(root=dataset_path,
train=True,
download=False,
transform=transform)
train_dataset, val_dataset = torch.utils.data.random_split(
train_dataset, [48000, 12000])
test_dataset = datasets.MNIST(root=dataset_path,
train=False,
download=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=32 * world_size,
shuffle=True,
**kwargs)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=400,
shuffle=False,
**kwargs)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=1000,
shuffle=False,
**kwargs)
if args.log_dir and rank == 0:
if os.path.exists(args.log_dir):
shutil.rmtree(args.log_dir, ignore_errors=True)
writer = SummaryWriter(args.log_dir)
global_step = 0
epochs = 10
steps_per_epoch = len(train_loader)
train()
test()
if rank == 0:
torch.save(model.state_dict(), args.save_path)
创建 Job 进行并行训练
回到模型构建控制台,在左侧的导航菜单中点击构建 > Job 进入 Job 管理页面,然后点击右上角的创建 Job > PyTorch。
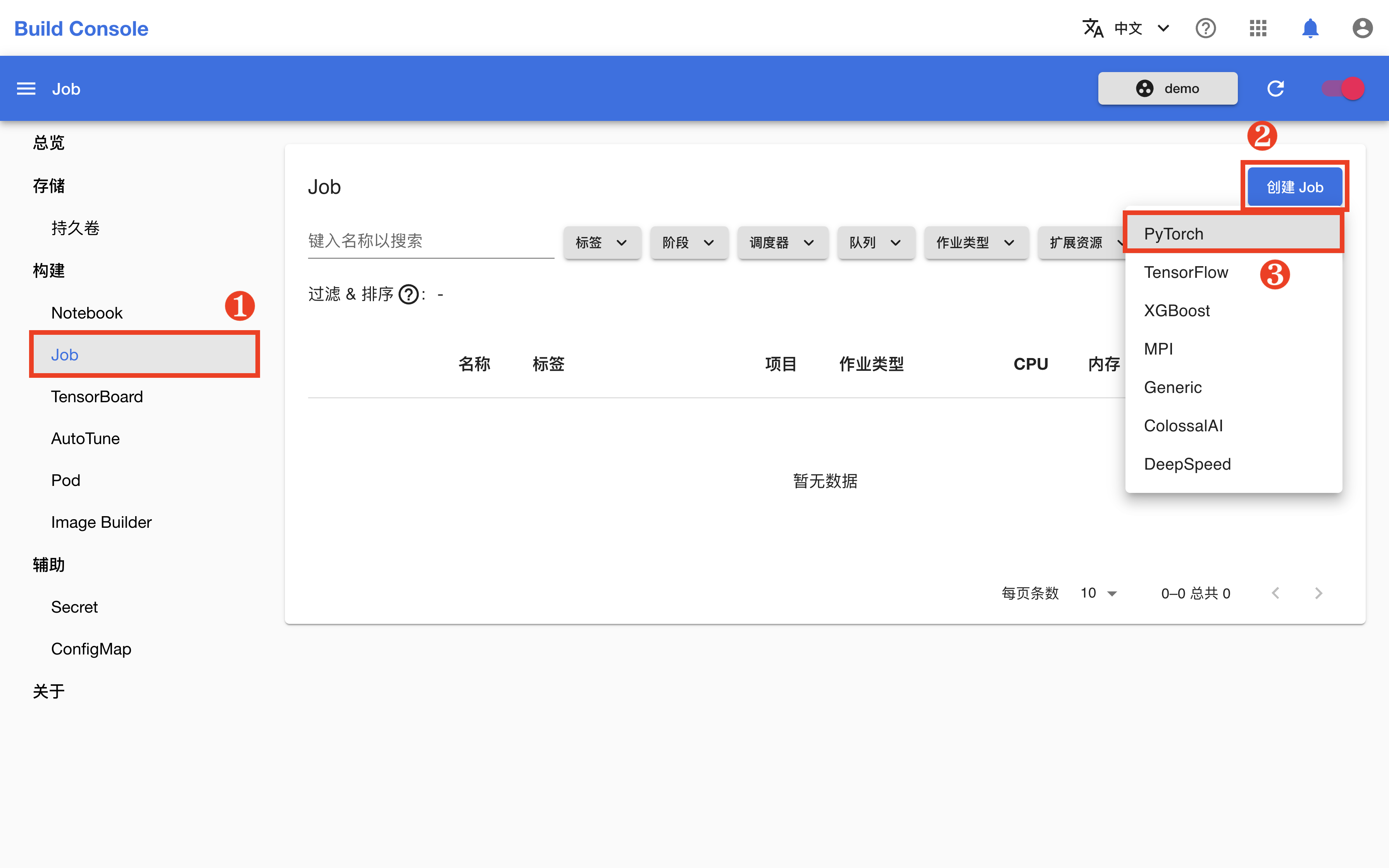
为了简化操作,在 Job 创建页面,点击预览 YAML,然后直接复制下面的 YAML 配置文件并粘贴到编辑框中,然后点击创建。
job.yaml
apiVersion: batch.tensorstack.dev/v1beta1
kind: PyTorchTrainingJob
metadata:
name: mnist # Job 名称
spec:
tensorboardSpec: # TensorBoard 服务器规约
resources:
limits:
cpu: 1
memory: 1Gi
trainingLogFilesets:
- t9k://pvc/mnist/log # 日志文件路径
image: tensorflow/tensorflow:2.14.0
# TensorBoard 服务器使用的镜像
torchrunConfig:
enabled: true # torchrun 启动
maxRestarts: 3
procPerNode: "4" # 每个副本启动的进程数
rdzvBackend: c10d
extraOptions: []
replicaSpecs:
- type: node
replicas: 1 # 副本数
restartPolicy: ExitCode
template:
spec:
securityContext:
runAsUser: 1000
containers:
- name: pytorch
image: t9kpublic/pytorch-1.13.0:sdk-0.5.2
# 容器的镜像
workingDir: /t9k/mnt # 工作路径
args: # `python`命令的参数
- torch_mnist_trainingjob.py
- "--log_dir"
- "log"
- "--save_path"
- "./model_state_dict.pt"
- "--backend"
- "nccl"
resources: # 计算资源
limits: # 限制量
cpu: 8 # CPU
memory: 16Gi # 内存
nvidia.com/gpu: 4 # GPU
requests: # 请求量
cpu: 4
memory: 8Gi
nvidia.com/gpu: 4
volumeMounts:
- name: data
mountPath: /t9k/mnt # 挂载路径
- name: dshm
mountPath: /dev/shm # 挂载共享内存
volumes:
- name: data
persistentVolumeClaim:
claimName: mnist # 要挂载的 PVC
- name: dshm
emptyDir:
medium: Memory
在跳转回到 Job 管理页面之后,等待刚才创建的 Job 就绪。第一次拉取镜像可能会花费较长的时间,具体取决于集群的网络状况。点击右上角的刷新图标来手动刷新 Job 状态,待 Job 开始运行之后,点击其名称进入详情页面。
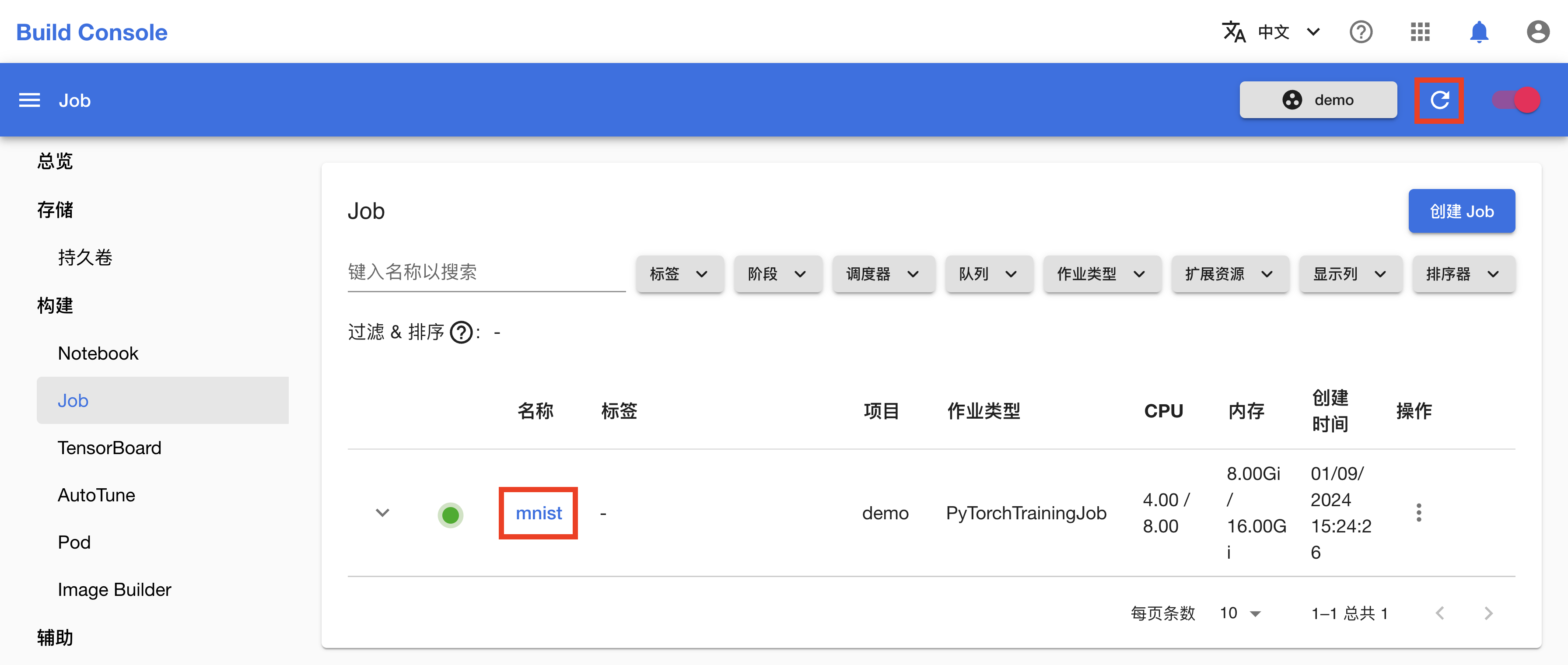
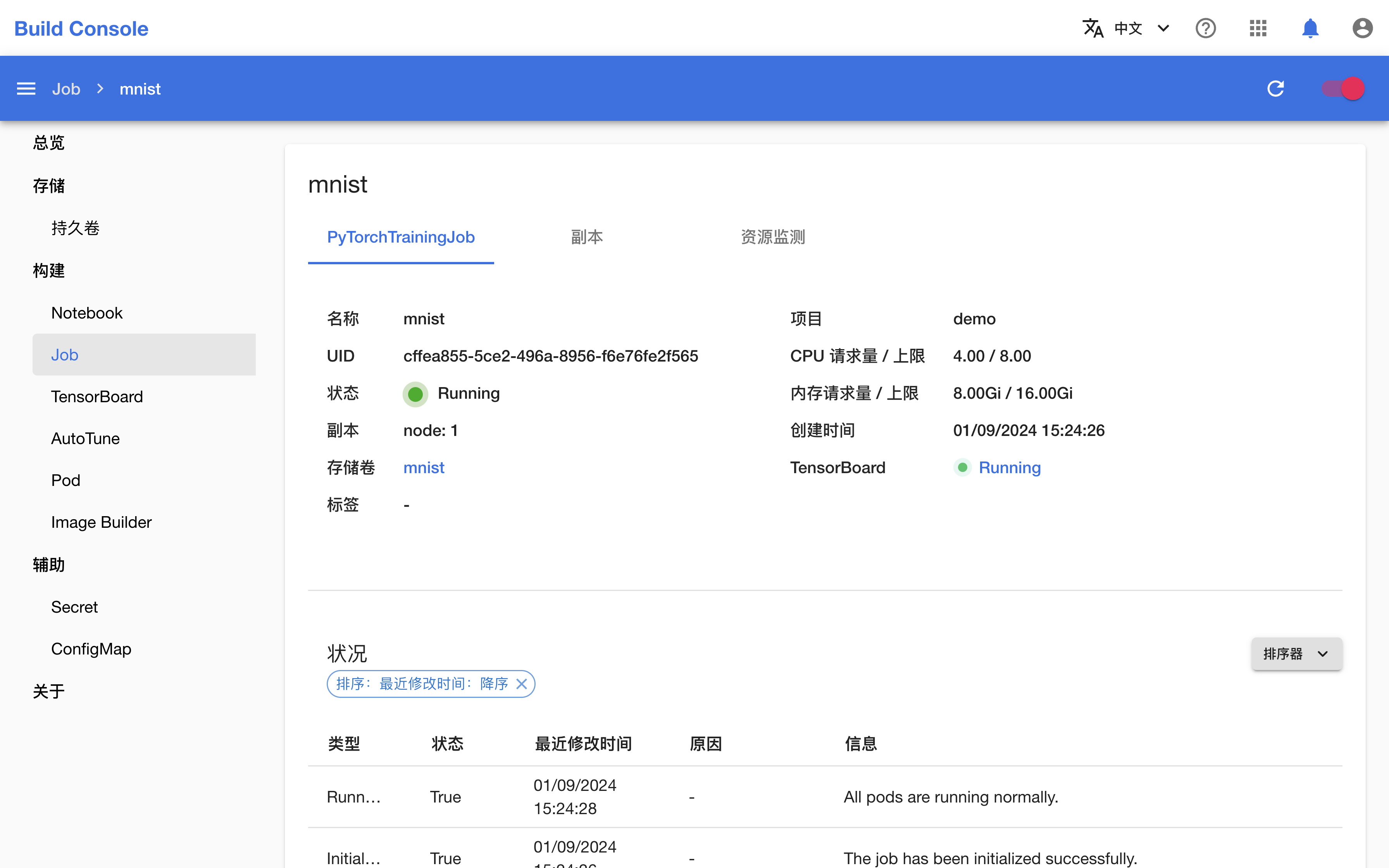
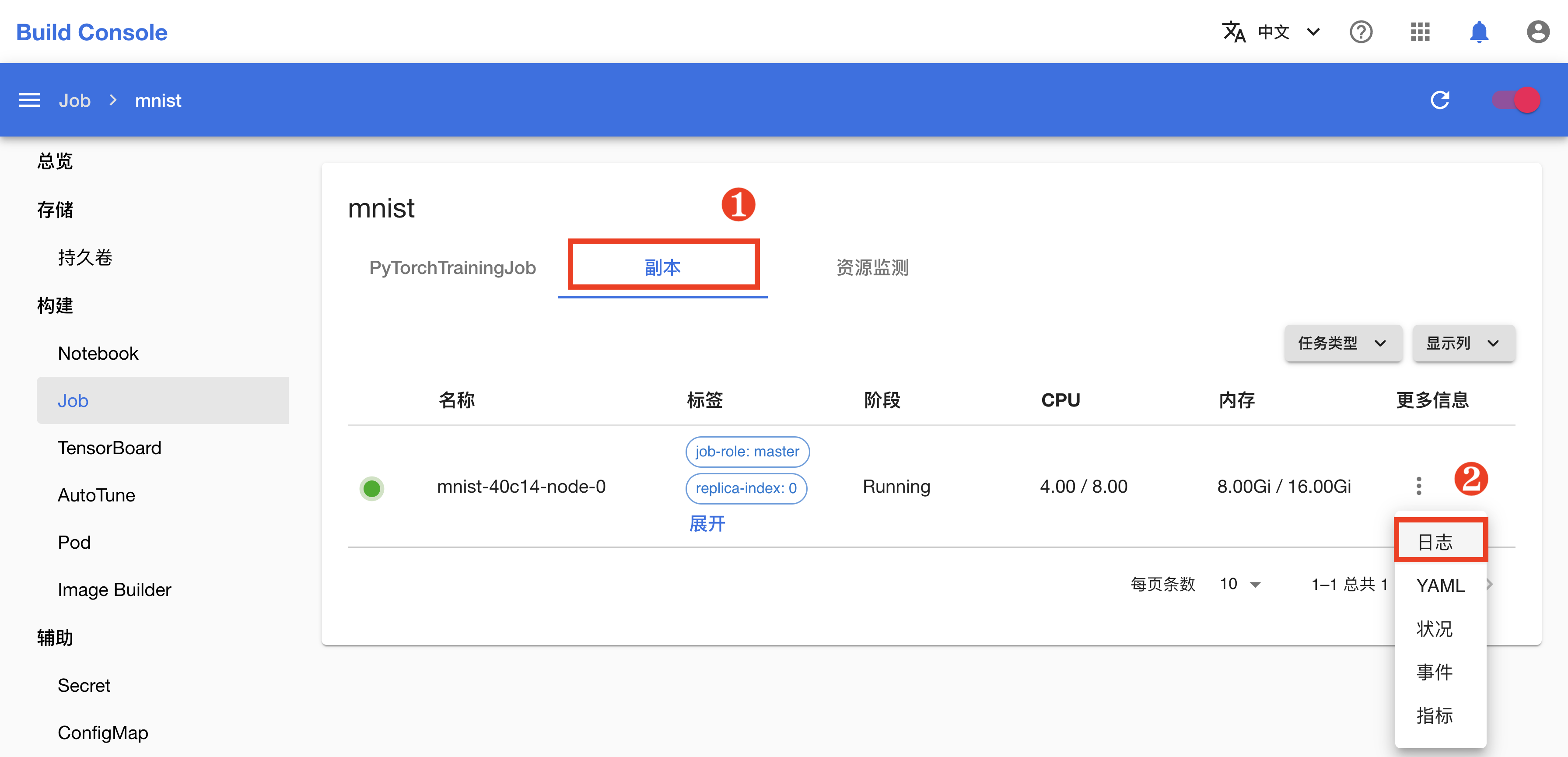
可以看到,Job 及其创建的 4 个 Worker(工作器)正在运行。
切换到副本标签页,点击副本的日志会显示其命令行输出,可以看到并行训练的当前进度。
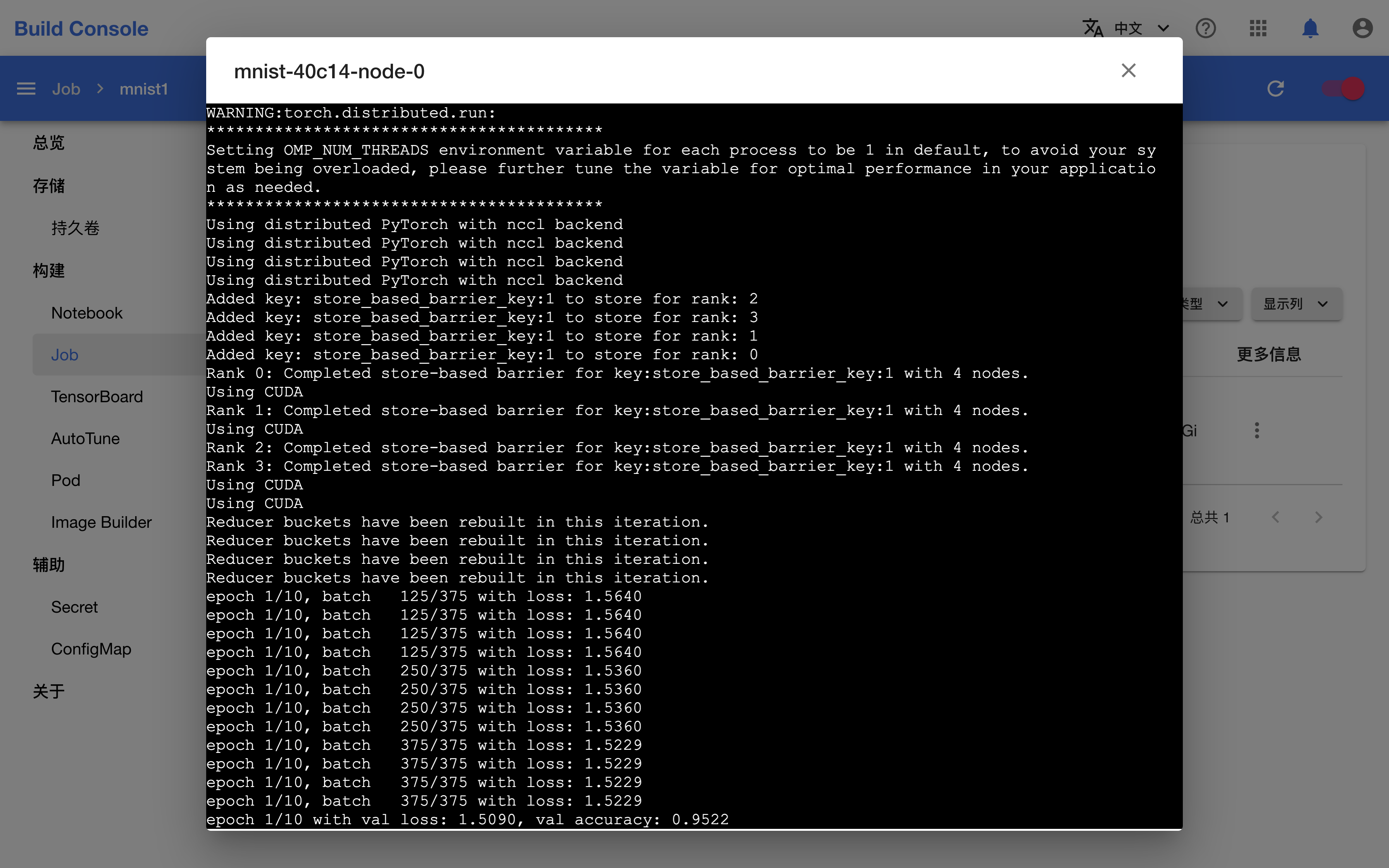
torch_mnist_trainingjob.py 训练脚本在训练过程中添加了 TensorBoard 回调并将日志保存在了 log 目录下,Job 相应地启动了一个 TensorBoard 服务器用于可视化展示这些数据。点击 TensorBoard 右侧的 Running 进入其前端页面。
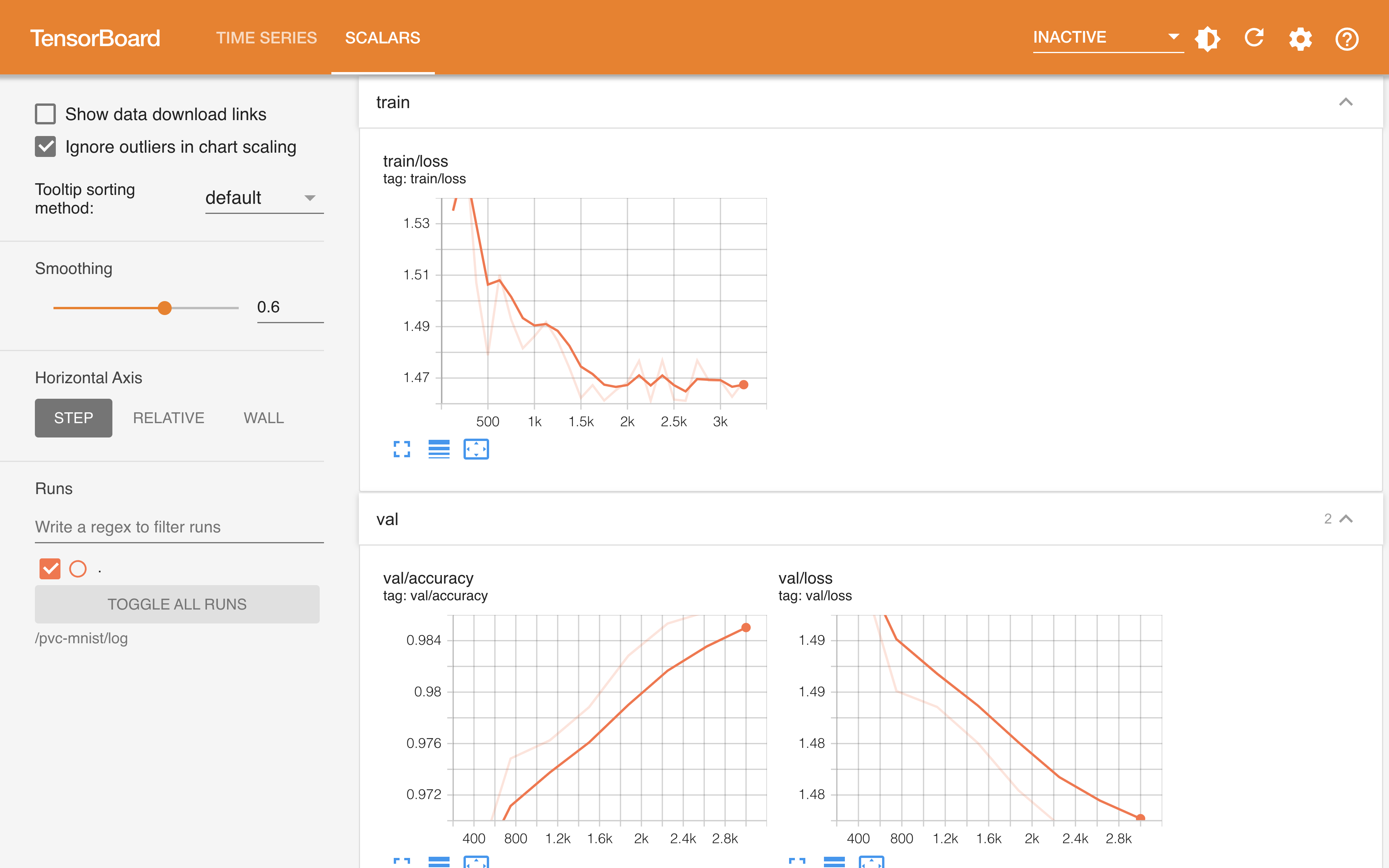
一段时间之后,Job 的状态变为 Done,表示训练已经成功完成。回到 Notebook mnist,将当前教程产生的所有文件移动到名为 parallel-training 的新文件夹下。