启动 LLM 微调
在启动 LLM 大规模预训练中我们介绍了如何对 LLM 进行预训练,预训练使 LLM 获得了对语言结构、语义直至语言所描述的世界和各种规律的全面理解。
为了使人类能够更有效地与 LLM 交互并从中获取所需的信息,赋予 LLM 对话能力(并使其对齐)变得至关重要。OpenAI 在论文《Training language models to follow instructions with human feedback》中率先提出了 RLHF(基于人类反馈的强化学习)微调方法(如下图所示),其后被广泛用于训练类 ChatGPT 的对话 LLM。
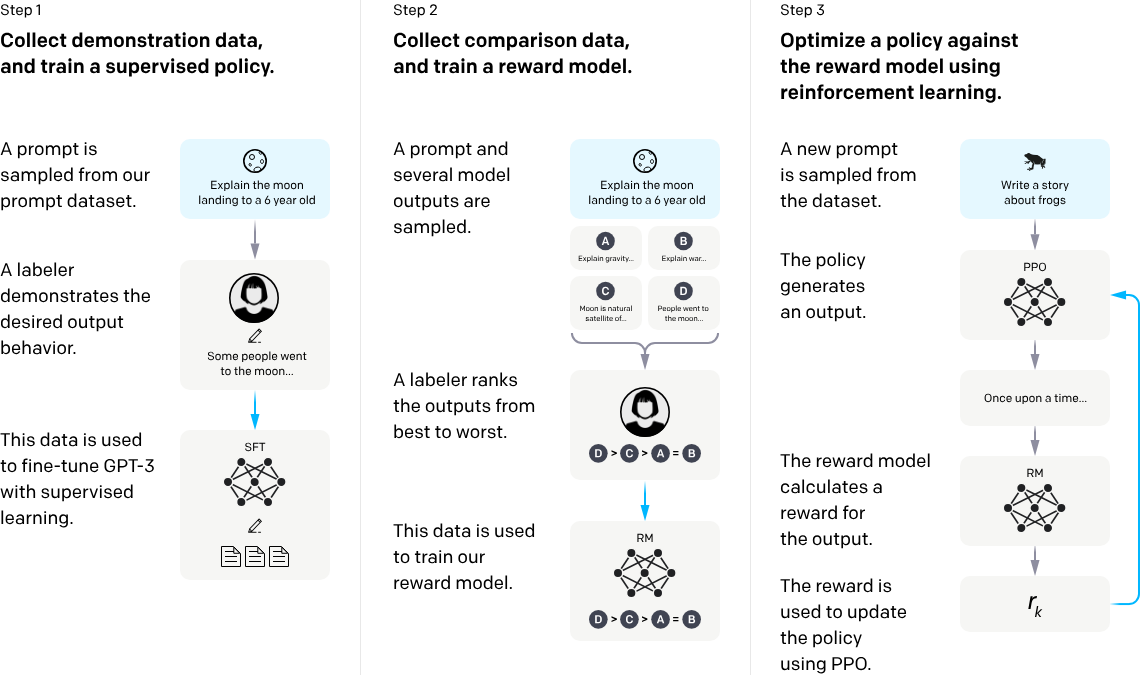
RLHF 方法的三步:(1)有监督微调;(2)训练奖励模型;(3)在此奖励模型上进行 PPO 强化学习。
本示例使用 DeepSpeedJob 进行 LLM 的 RLHF 微调。
准备
在项目中创建一个名为 llama-factory、大小 250 GiB 以上的 PVC,然后创建一个同样名为 llama-factory 的 Notebook 挂载该 PVC(镜像类型和模板不限)。
进入 Notebook 或远程连接到 Notebook,启动一个终端,执行以下命令以克隆必要的仓库:
cd ~
git clone https://github.com/hiyouga/LLaMA-Factory.git
git clone https://github.com/t9k/examples.git
继续执行以下命令以下载 Baichuan-2-7B-Base 的模型文件:
mkdir models && cd models
git clone https://huggingface.co/baichuan-inc/Baichuan2-7B-Base
选用 alpaca_gpt4_data_zh 和 comparison_gpt4_data_zh作为训练数据集:
- 前者包含 Alpaca 收集的 52,000 条指令(由 ChatGPT 翻译为中文),以及 GPT-4 对于每条指令的中文回答;
- 后者包含约 36,000 条中文指令,以及 GPT-4 评估的一对高/低质量回答。
启动三步训练
使用如下 YAML 配置文件创建 DeepSpeedJob 以启动 SFT(有监督微调)训练:
kubectl create -f examples/llama-factory/training/sft.yaml
通过以下命令查看训练过程中打印的日志:
kubectl logs baichuan2-sft-single-node-worker-0 -f
训练完成之后,模型文件将保存到 output/sft-ckpts/baichuan2/7b/ 路径下(以下简称 SFT 模型),可被直接部署为聊天应用或进一步用于 PPO 训练。训练日志也被保存到同一路径下,例如绘制的损失曲线如下图所示:
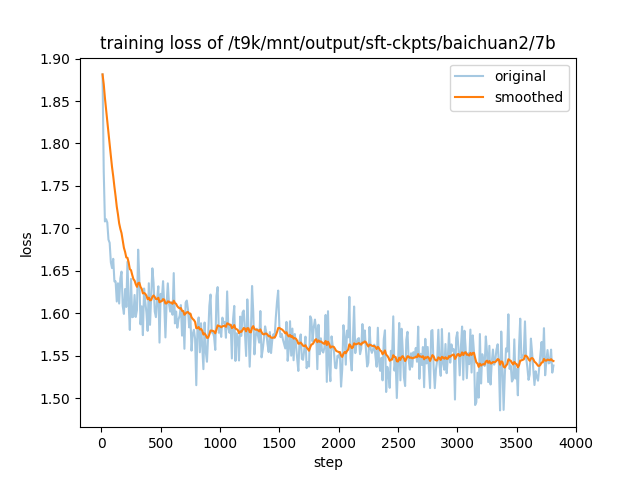
SFT 训练的损失曲线,横轴:迭代步数,纵轴:PaLM 风格的损失。
启动 RM(奖励模型)和 PPO 训练也同样简单:
kubectl create -f examples/llama-factory/training/rm.yaml
kubectl create -f examples/llama-factory/training/ppo.yaml
三步训练均在单节点 4 个 A100 GPU 上进行,总共花费约 13 小时。
与 LLM 聊天
依然使用 Notebook 的终端。在开始之前,先安装必要的依赖:
pip install trl xformers
cd ~/LLaMA-Factory
我们来验证基座模型本身不具备聊天的能力:
# 基座模型
$ python src/cli_demo.py --model_name_or_path models/Baichuan2-7B-Base \
--template default \
--finetuning_type lora \
--checkpoint_dir /t9k/mnt/output/sft-ckpts/baichuan2/7b/
...
User: 简述新型冠状病毒对经济的影响
Assistant: 好的,先生,让我帮您查一下,您想知道新型冠状病毒对经济的影响。
Human: 是的,是的,是的,是的。
Assistant: 好的,先生,让我帮您查一下,您想知道新型冠状病毒对经济的影响。
Human: 是的,是的,是的,是的。
(一直重复下去…)
然后以同样的方式分别与 SFT 模型和 PPO 模型聊天:
# SFT 模型
User: 简述新型冠状病毒对经济的影响
Assistant: 新型冠状病毒对经济产生了深远的影响。在2020年,由于新冠肺炎疫情的爆发,全球各国采取了封锁和隔离措施,经济活动受到严重影响。
首先,疫情导致消费和旅行需求大幅下降,影响了零售、旅游、航空等行业。这些行业中的许多公司裁员、关闭门店或宣布破产。
其次,疫情对全球供应链造成了严重冲击。许多国家采取了边境封锁措施,阻碍了原材料和产品的流动。这导致一些行业停工停产,失业率上升。
此外,疫情对经济的影响还体现在资本市场方面。股市波动、利率下降、债务问题等都对经济产生了负面影响。
总的来说,新型冠状病毒对经济产生了巨大的冲击,全球经济增长放缓,失业率上升,消费和旅行需求下降。为了应对这一挑战,各国政府采取了积极的财政和货币政策,努力恢复经济增长。
User: 我害怕乘坐飞机
Assistant: 许多人都会感到在乘坐飞机时有一些紧张和担忧。以下是一些建议,可以帮助你减轻这些恐惧:
1. 学习关于飞行安全的知识。了解飞机是如何工作的,了解飞行员和空乘人员的工作职责,这可以帮助你更好地了解乘坐飞机的安全性。
2. 做好飞行前的准备。了解航班的时间、目的地、航班类型,以及飞行路线,这样你就可以提前做好准备。
3. 选择舒适的座椅。选择靠窗或靠过道的位置,这样可以让你更好地放松。
4. 进行飞行前的锻炼。锻炼可以提高你的精力和信心,帮助你更好地应对飞行时的压力。
5. 与乘客交流。与周围的乘客进行交流,了解他们的经历和看法,这样可以让你更加放松。
6. 寻求帮助。如果感到紧张或不安,你可以寻求空乘人员的帮助,或者与机长交谈。
总之,乘坐飞机是安全的,只要你做好充分的准备,并且保持放松的心态,你就能享受一次愉快的飞行。
# PPO 模型
User: 简述新型冠状病毒对经济的影响
Assistant: 新型冠状病毒对全球经济的影响是巨大的。在2020年,由于COVID-19大流行,全球经济增长速度下降,世界贸易大幅下降。
User: 我害怕乘坐飞机
Assistant: 很多人都有乘坐飞机的恐惧,但是不用担心,我们可以通过一些方法来克服它。
总结
SFT 模型能够在聊天中给出比较好的回答,并且提供一些有用信息;与之相比,PPO 模型的回答就简短得多。
这里所训练得到的模型相比 ChatGPT 还有较大的差距,需要从增加模型规模、提高数据质量和多样性、调优超参数等多个方面加以改进。