使用 PyTorchTrainingJob 进行参数服务器训练
本教程演示如何使用 PyTorchTrainingJob 对 PyTorch 模型进行基于 RPC 的参数服务器训练(使用分布式 RPC 框架 torch.distributed.rpc)。示例修改自 PyTorch 官方教程 Implementing a Parameter Server Using Distributed RPC Framework,关于训练脚本的更多细节信息请参考此教程。
运行示例
请按照使用方法准备环境,然后前往本教程对应的示例,参照其 README 文档运行。
检查训练日志和指标
训练开始后,进入模型构建控制台的 Job 页面,可以看到名为 torch-mnist-trainingjob-ps 的 PyTorchTrainingJob 正在运行:
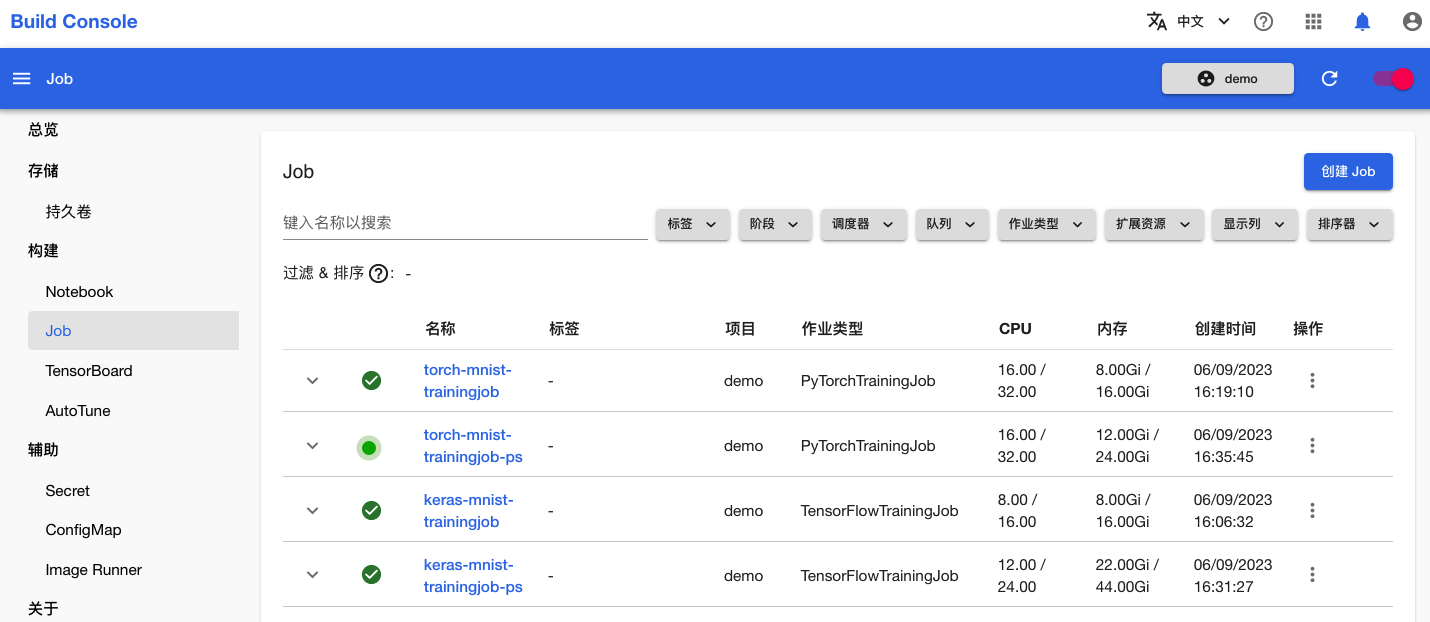
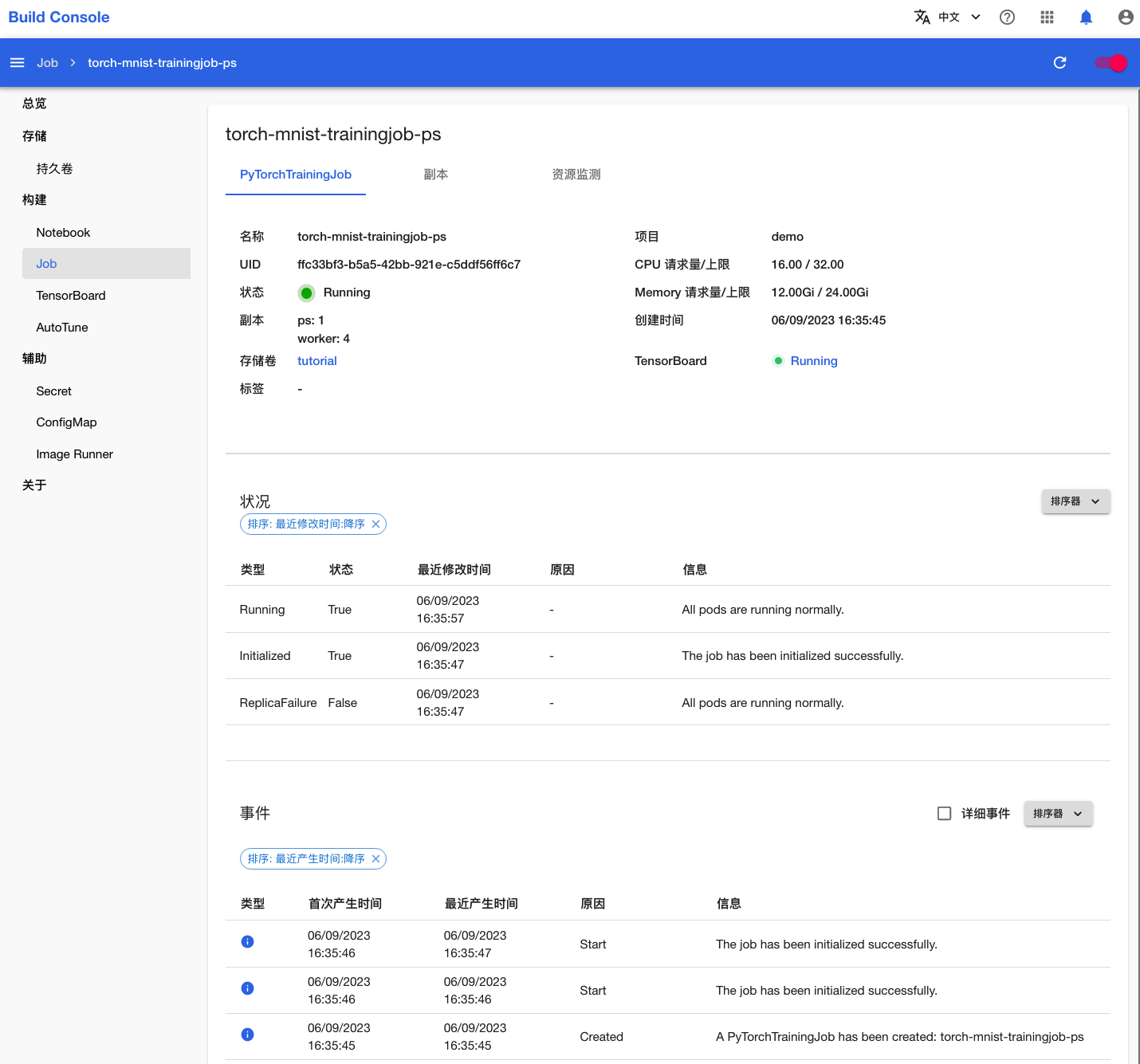
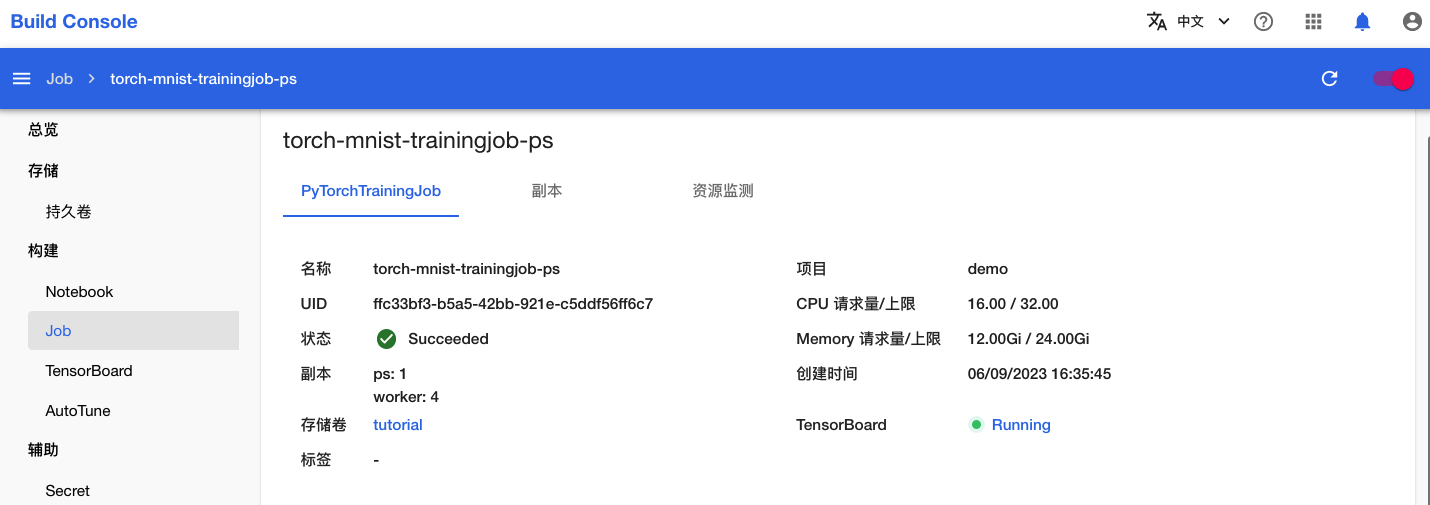
点击该名称进入详情页面,可以看到刚才创建的 PyTorchTrainingJob 的基本信息、状况信息和事件信息:
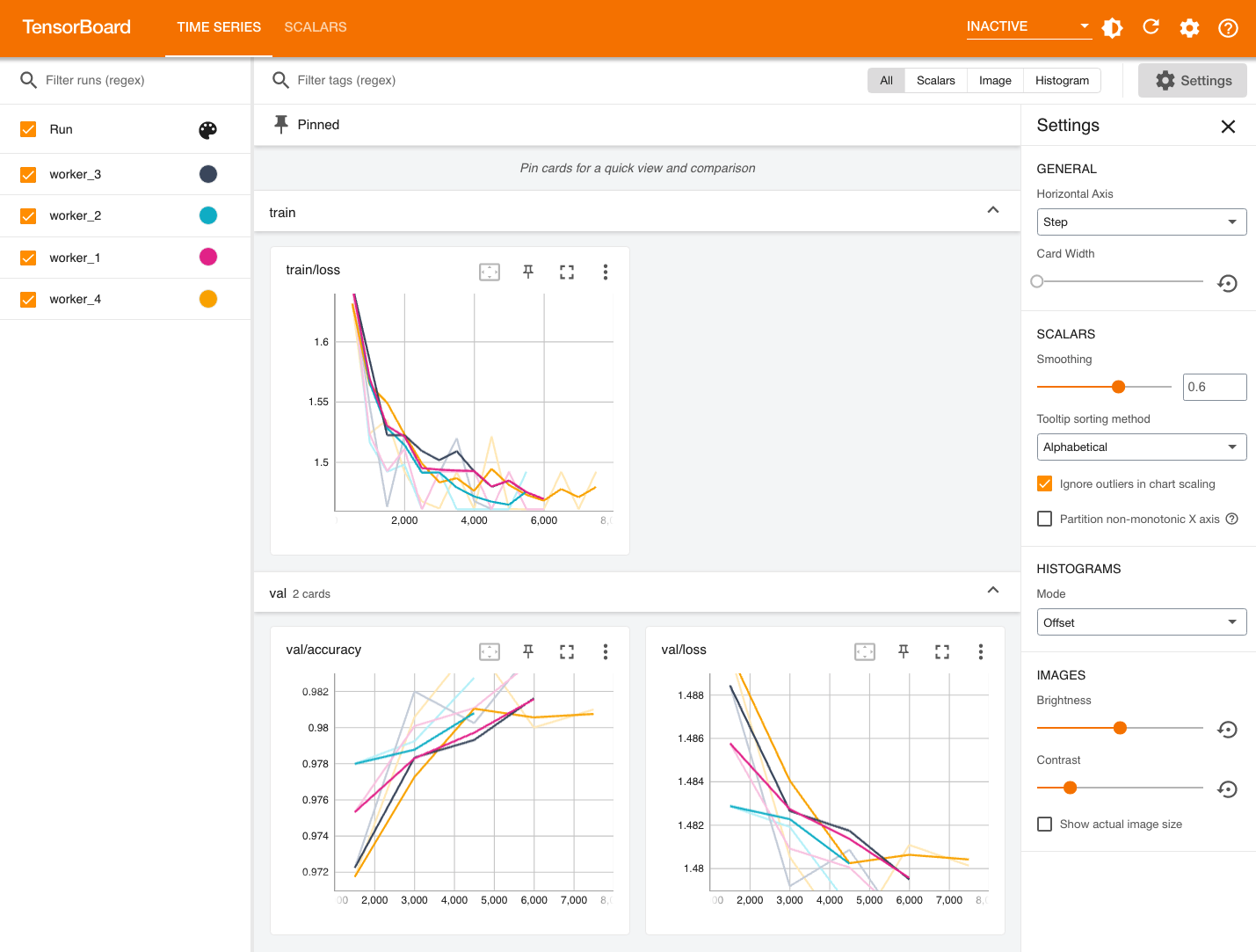
点击 TensorBoard 右侧的 Running 打开 TensorBoard,可以查看可视化展示的训练和验证指标:
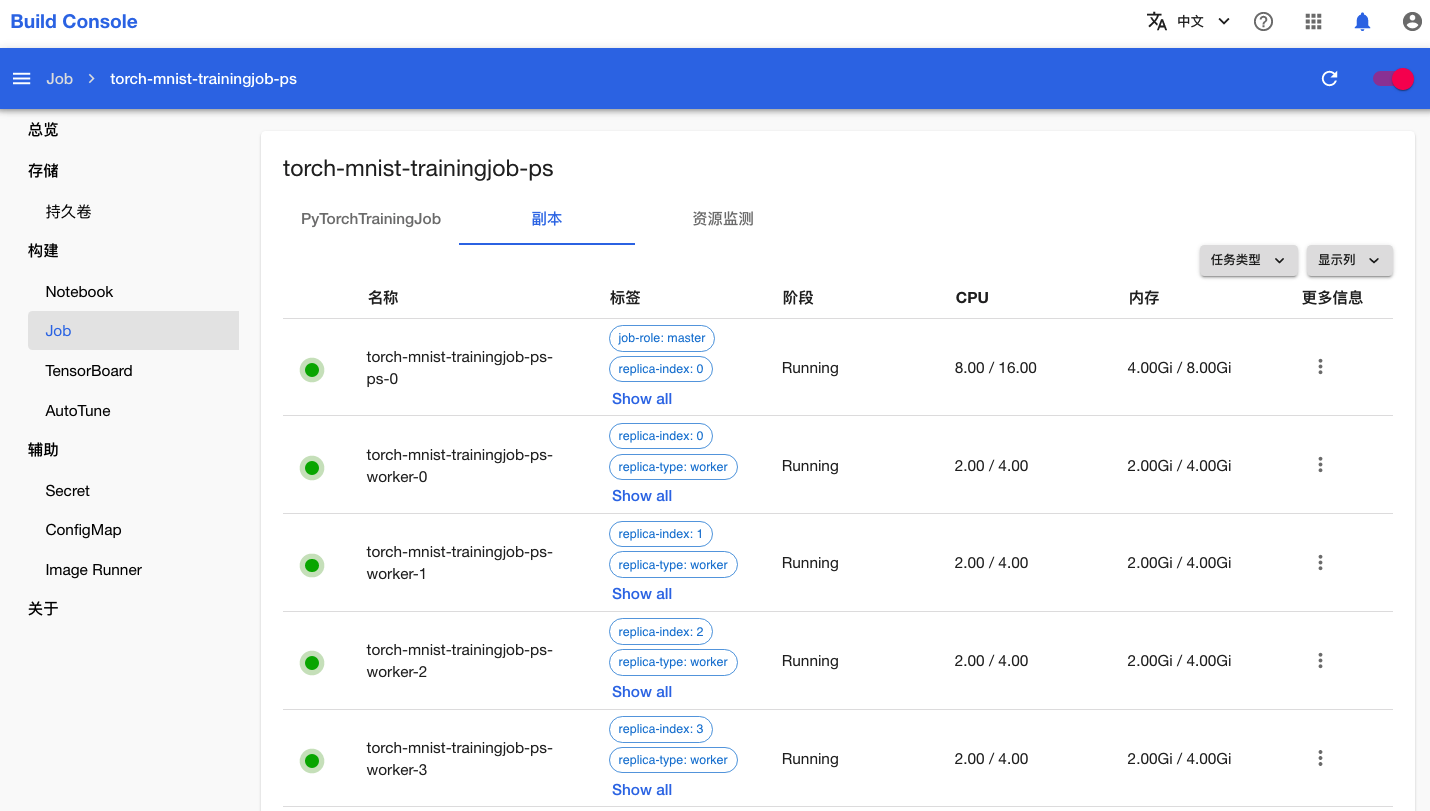
点击上方标签页的副本,查看 PyTorchTrainingJob 的 Pod 信息:
点击副本右侧的更多按钮 > 日志以查看训练脚本执行过程中的日志输出:
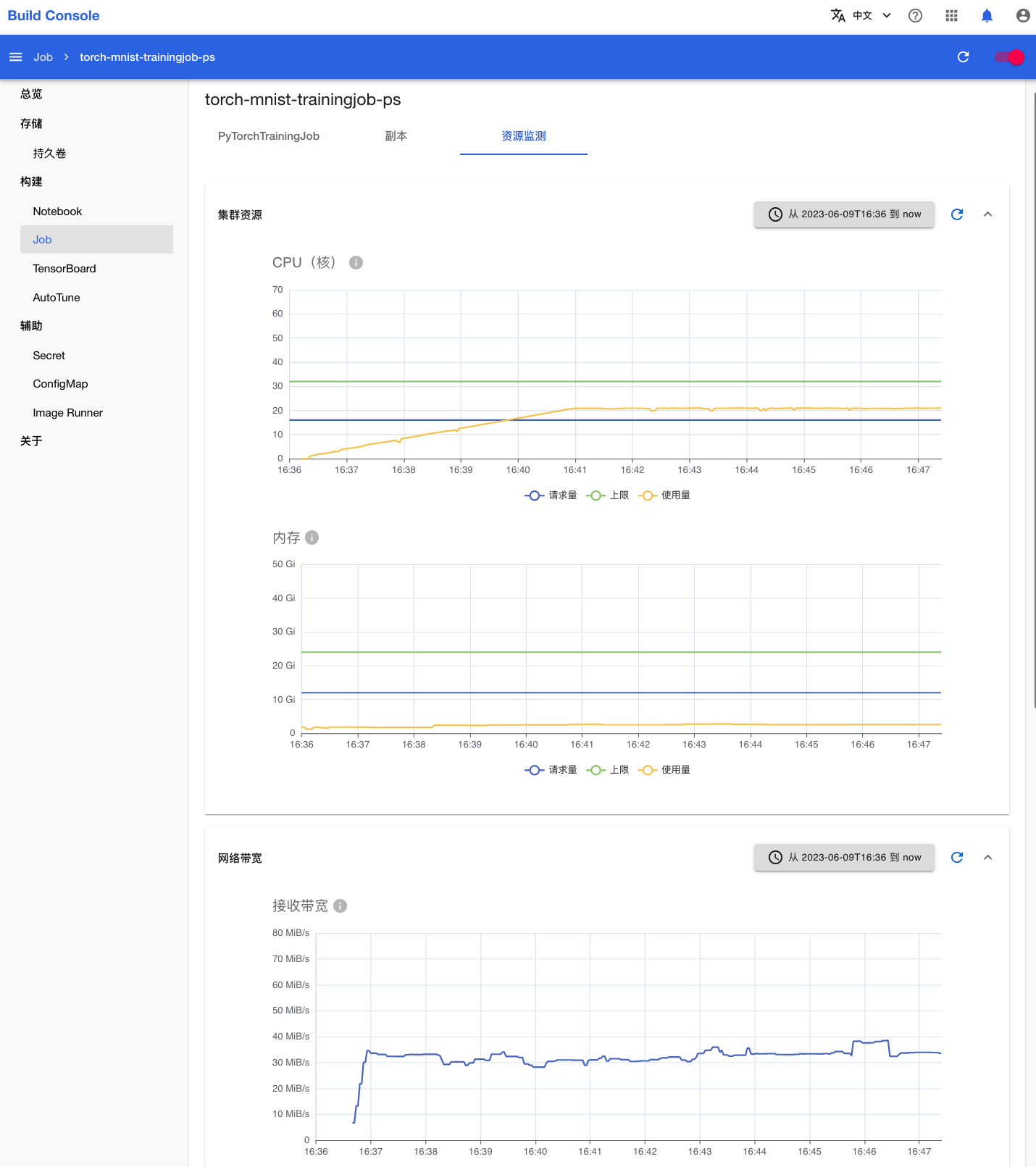
点击上方标签页的资源监测,查看 PyTorchTrainingJob 运行过程中使用集群计算资源、网络资源和存储资源的情况:
一段时间之后,PyTorchTrainingJob 的状态变为 Succeeded,表示训练成功完成。
若 PyTorchTrainingJob 在运行过程中出错,其状态会变为 Error,并在事件信息和 Pod 信息部分显示错误信息,此时需要根据给出的错误信息进行问题排查。